This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This also led to a backlog of data that needed to be ingested. Steep learning curve for datascientists: Many of Rockets datascientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
This reduces the reliance on manual data labeling and significantly speeds up the model training process. At its core, Snorkel Flow empowers datascientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets.
This new version enhances the data-focused authoring experience for datascientists, engineers, and SQL analysts. The updated Notebook experience features a sleek, modern interface and powerful new functionalities to simplify coding and data analysis.
According to IDC , 83% of CEOs want their organizations to be more data-driven. Datascientists could be your key to unlocking the potential of the Information Revolution—but what do datascientists do? What Do DataScientists Do? Datascientists drive business outcomes.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Datascientists often spend up to 80% of their time on data engineering in data science projects.
However, higher education institutions often lack ML professionals and datascientists. Amazon SageMaker Canvas is a low-code/no-code ML service that enables business analysts to perform data preparation and transformation, build ML models, and deploy these models into a governed workflow. International (CC BY 4.0)
Built on IBM’s Cognitive Enterprise Data Platform (CEDP), Wf360 ingestsdata from more than 30 data sources and now delivers insights to HR leaders 23 days earlier than before. Flexible APIs drive seven times faster time-to-delivery so technical teams and datascientists can deploy AI solutions at scale and cost.
With the IoT, tracking website clicks, capturing call data records for a mobile network carrier, tracking events generated by “smart meters” and embedded devices can all generate huge volumes of transactions. Many consider a NoSQL database essential for high dataingestion rates.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
Choose Sync to initiate the dataingestion job. After data synchronization is complete, select the desired FM to use for retrieval and generation (it requires model access to be granted to this FM in Amazon Bedrock before using). On the Amazon Bedrock console, navigate to the created knowledge base.
Each product translates into an AWS CloudFormation template, which is deployed when a datascientist creates a new SageMaker project with our MLOps blueprint as the foundation. These are essential for monitoring data and model quality, as well as feature attributions.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps.
However, a more holistic organizational approach is crucial because generative AI practitioners, datascientists, or developers can potentially use a wide range of technologies, models, and datasets to circumvent the established controls. Tanvi Singhal is a DataScientist within AWS Professional Services.
Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation. About the Authors Sandeep Singh is a Senior Generative AI DataScientist at Amazon Web Services, helping businesses innovate with generative AI.
The SageMaker Feature Store Feature Processor reduces this burden by automatically transforming raw data into aggregated features suitable for batch training ML models. It lets engineers provide simple data transformation functions, then handles running them at scale on Spark and managing the underlying infrastructure.
The teams built a new dataingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. Dr. Nicki Susman is a Senior DataScientist and the Technical Lead of the Principal Language AI Services team. He has 20 years of enterprise software development experience.
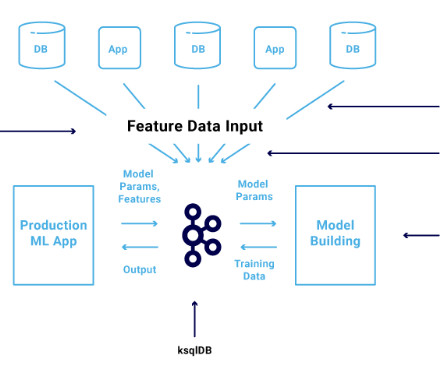
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. I had previously discussed example use cases and architectures that leverage Apache Kafka and machine learning.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Dataingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The dataingestion and extraction component ingests and extracts content from these unstructured documents.
Our expert speakers will cover a wide range of topics, tools, and techniques that datascientists of all levels can apply in their work. ODSC Europe is still a few months away, coming this June 14th-15th, but we couldn’t be more excited to announce our first group of sessions. Check a few of them out below.
In the following figure, we provide a reference architecture to preprocess data using AWS Batch and using Ground Truth to label the datasets. For more information on using Ground Truth to label 3D point cloud data, refer to Use Ground Truth to Label 3D Point Clouds.
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: DataIngestion: Collecting data from various sources and ensuring it’s available for analysis. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: DataScientists, Developers, AI Architects, and ML Engineers seeking to build cutting-edge autonomous systems.
Creates two indexes for text ( ooc_text ) and kNN embedding search ( ooc_knn ) and bulk uploads data from the combined dataframe through the ingest_data_into_ops function. This dataingestion process takes 5–10 minutes and can be monitored through the Amazon CloudWatch logs on the Monitoring tab of the Lambda function.
MongoDB Atlas offers automatic sharding, horizontal scalability, and flexible indexing for high-volume dataingestion. Among all, the native time series capabilities is a standout feature, making it ideal for a managing high volume of time-series data, such as business critical application data, telemetry, server logs and more.
You’ll explore dataingestion from multiple sources, preprocessing unstructured data into a normalized format that facilitates uniform chunking across various file types, and metadata extraction. You’ll also discuss loading processed data into destination storage.
The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data. The Python notebook method is great for datascientists already familiar with Jupyter notebooks and coding, and provides maximum control and tuning. This wraps up the entire workflow.
In this post, we assign the functions in terms of the ML lifecycle to each role as follows: Lead datascientist Provision accounts for ML development teams, govern access to the accounts and resources, and promote standardized model development and approval process to eliminate repeated engineering effort.
This reduces the reliance on manual data labeling and significantly speeds up the model training process. At its core, Snorkel Flow empowers datascientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets.
Amazon Athena to provide developers and business analysts SQL access to the generated data for analysis and troubleshooting. Amazon EventBridge to trigger the dataingestion and ML pipeline on a schedule and in response to events. His team applies data science and digital technologies to support Marubeni Power growth strategies.
The first is by using low-code or no-code ML services such as Amazon SageMaker Canvas , Amazon SageMaker Data Wrangler , Amazon SageMaker Autopilot , and Amazon SageMaker JumpStart to help data analysts prepare data, build models, and generate predictions. We recognize that customers have different starting points.
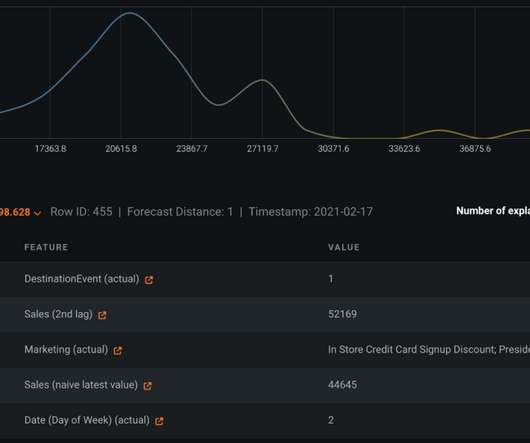
Datascientists have used the DataRobot AI Cloud platform to build time series models for several years. Recently, new forecasting features and an improved integration with Google BigQuery have empowered datascientists to build models with greater speed, accuracy, and confidence. Forecasting the future is difficult.
To proactively recommend articles on companies or industries that users are reading about, you can record how frequently readers are engaging with articles about specific companies and industries, and use this data with Amazon Personalize filters to further tailor the recommended content. Happy building!
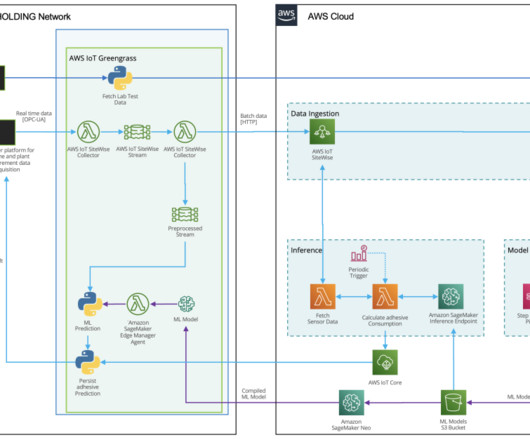
Dataingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Two types of data sources exist for this use case. Setting up and managing custom ML environments can be time-consuming and cumbersome.
This evolution underscores the demand for innovative platforms that simplify dataingestion and transformation, enabling faster, more reliable decision-making. As Tamers book, Financial Data Engineering , illustrates, success in this field requires a blend of technical skills, domain knowledge, and strategic foresight.
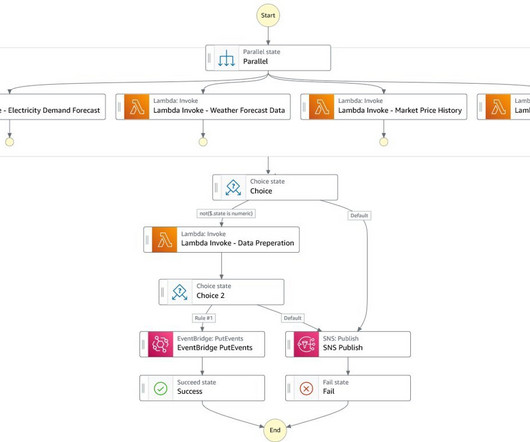
Other steps include: dataingestion, validation and preprocessing, model deployment and versioning of model artifacts, live monitoring of large language models in a production environment, monitoring the quality of deployed models and potentially retraining them. Take a look at an example of such a setup presented in Figure 4.
I recently took the Azure DataScientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft Data Science Learning Path and the Coursera Microsoft Azure DataScientist Associate Specialization.
Thus, making it easier for analysts and datascientists to leverage their SQL skills for Big Data analysis. It applies the data structure during querying rather than dataingestion. How Data Flows in Hive In Hive, data flows through several steps to enable querying and analysis.
They can efficiently aggregate and process data over defined periods, making them ideal for identifying trends, anomalies, and correlations within the data. High-Volume DataIngestion TSDBs are built to handle large volumes of data coming in at high velocities. What are the Benefits of Using a Time Series Database?
It involves the design, development, and maintenance of systems, tools, and processes that enable the acquisition, storage, processing, and analysis of large volumes of data. Data Engineers work to build and maintain data pipelines, databases, and data warehouses that can handle the collection, storage, and retrieval of vast amounts of data.
Users are able to rapidly improve training data quality and model performance using integrated error analysis to develop highly accurate and adaptable AI applications. Data can then be labeled programmatically using a data-centric AI workflow in Snorkel Flow to quickly generate high-quality training sets over complex, highly variable data.
Users are able to rapidly improve training data quality and model performance using integrated error analysis to develop highly accurate and adaptable AI applications. Data can then be labeled programmatically using a data-centric AI workflow in Snorkel Flow to quickly generate high-quality training sets over complex, highly variable data.
Vertex AI combines data engineering, data science, and ML engineering into a single, cohesive environment, making it easier for datascientists and ML engineers to build, deploy, and manage ML models. This unified approach enables seamless collaboration among datascientists, data engineers, and ML engineers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content