This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificial intelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications. Large language models (LLMs) have taken the field of AI by storm.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker.
The architectures strengths lie in its consistency across environments, automatic dataingestion processes, and comprehensive monitoring capabilities. He solves complex organizational and technical challenges using datascience and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud.
Data preparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
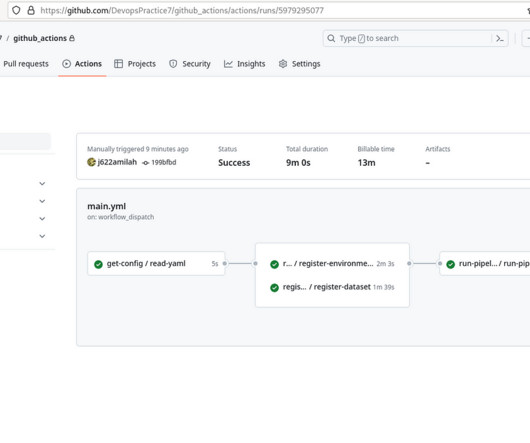
Datascience teams often face challenges when transitioning models from the development environment to production. This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
With the IoT, tracking website clicks, capturing call data records for a mobile network carrier, tracking events generated by “smart meters” and embedded devices can all generate huge volumes of transactions. Many consider a NoSQL database essential for high dataingestion rates.
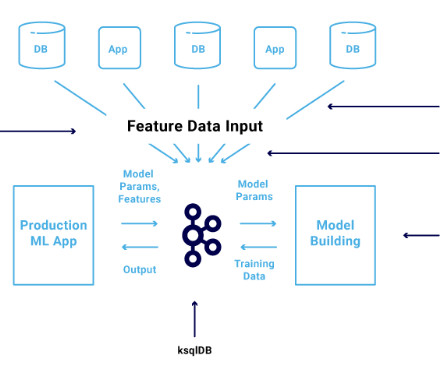
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
I recently took the Azure Data Scientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft DataScience Learning Path and the Coursera Microsoft Azure Data Scientist Associate Specialization.
The IDP Well-Architected Custom Lens follows the AWS Well-Architected Framework, reviewing the solution with six pillars with the granularity of a specific AI or machine learning (ML) use case, and providing the guidance to tackle common challenges. Additionally, the solution must handle high data volumes with low latency and high throughput.
Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. Some key differences are discussed below.
Manager DataScience at Marubeni Power International. MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability.
This approach, when applied to generative AI solutions, means that a specific AI or machine learning (ML) platform configuration can be used to holistically address the operational excellence challenges across the enterprise, allowing the developers of the generative AI solution to focus on business value.
This combination of great models and continuous adaptation is what will lead to a successful machine learning (ML) strategy. MLOps focuses on the intersection of datascience and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle.
Andre Franca | CTO | connectedFlow Join this session to demystify the world of Causal AI, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. By the end of this session, you’ll have a practical blueprint to efficiently harness feature stores within ML workflows.
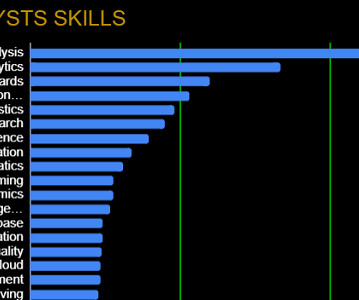
Top Data Analytics Skills and Platforms for 2023, PyTorch 2.0 Released, and 5 Huge DataScience Career Mistakes Top Data Analytics Skills and Platforms for 2023 We looked at over 25,000 job descriptions, and these are the data analytics platforms, tools, and skills that employers are looking for in 2023.
Andre Franca | CTO | connectedFlow Explore the world of Causal AI for datascience practitioners, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. No-Code and Low-Code AI: A Practical Project-Driven Approach to ML Gwendolyn D.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. The KG files were stored in Amazon Simple Storage Service (Amazon S3) and then loaded in Amazon Neptune.
Introduction In the rapidly evolving landscape of Machine Learning , Google Cloud’s Vertex AI stands out as a unified platform designed to streamline the entire Machine Learning (ML) workflow. This unified approach enables seamless collaboration among data scientists, data engineers, and ML engineers.
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: DataIngestion: Collecting data from various sources and ensuring it’s available for analysis. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning.
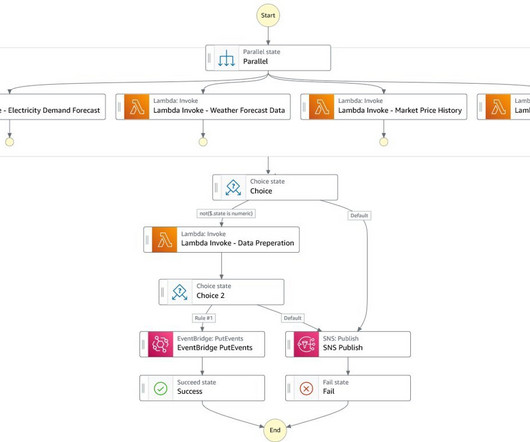
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. Raju Patil is a Data Scientist in AWS Professional Services.
Data scientists drive business outcomes. Many implement machine learning and artificial intelligence to tackle challenges in the age of Big Data. They develop and continuously optimize AI/ML models , collaborating with stakeholders across the enterprise to inform decisions that drive strategic business value. Download Now.
Large Model Quality and Evaluation Anoop Sinha | Research Director, AI & Future Technologies | Google Large model development faces many challenges when it comes to ML quality and evaluation, including the coverage, scale, and wide use cases for what LLMs are used for. Check out a few of them below.
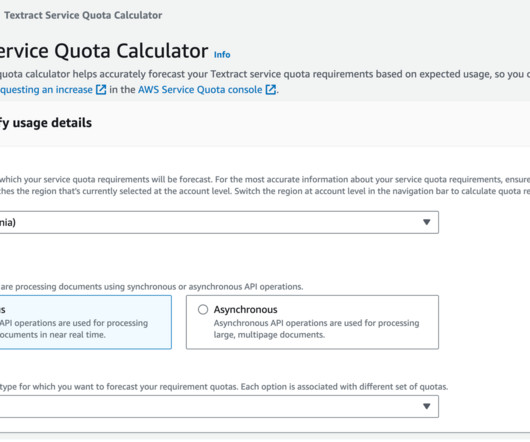
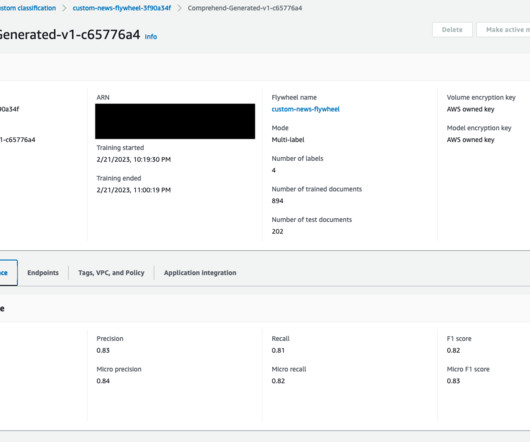
Harness a flywheel approach, wherein continuous data feedback is utilized to routinely orchestrate and evaluate enhancements to your models and processes. Enhance IDP with Amazon Comprehend Flywheel and Amazon Textract Custom Queries Leverage the Amazon Comprehend flywheel for a streamlined ML process, from dataingestion to deployment.
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, cloud dataingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. It’s an easy way to run analytics on IoT data to gain accurate insights.
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any datascience task then you definitely used pandas. So, pandas is a library which helps with performing dataingestion and transformations. Note for Readers — Are you a programming, AI, or machine learning enthusiast?
For a deeper dive into end-to-end solutions that cover dataingestion, classification, extraction, enrichment, verification and validation, and consumption, refer to Intelligent document processing with AWS AI services: Part 1 and Part 2. About the Authors Suyin Wang is an AI/ML Specialist Solutions Architect at AWS.
Amazon SageMaker Processing jobs for large scale dataingestion into OpenSearch. This notebook will ingest the SageMaker docs to an OpenSearch Service index called llm_apps_workshop_embeddings. This will download the dataset locally into the notebook and then ingest it into the OpenSearch Service index. .
These models offer tremendous potential but also bring a unique set of challenges when it comes to building large-scale ML projects. Naturally, training a machine learning model (regardless of the problem being solved or the particular model architecture that was chosen) is a key part of every ML project. But what happens next?
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. This includes preparing data, creating a SageMaker model, and performing batch transform using the model. The dataingestion for this practice should finish within 60 seconds.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and ML Engineers seeking to build cutting-edge autonomous systems.
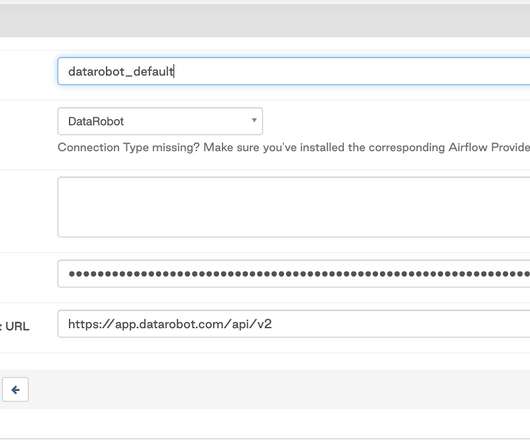
Airflow is a perfect tool to orchestrate stages of the DataRobot machine learning (ML) pipeline, because it provides an easy but powerful solution to integrate DataRobot capabilities into bigger pipelines, combine it with other services, as well as to clean your data, and store or publish the results. DataRobot Provider Modules.
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
They can efficiently aggregate and process data over defined periods, making them ideal for identifying trends, anomalies, and correlations within the data. High-Volume DataIngestion TSDBs are built to handle large volumes of data coming in at high velocities. What are the Benefits of Using a Time Series Database?
Robust validation and monitoring frameworks enhance pipeline reliability and trustworthiness, safeguarding against data-driven decision-making risks. Must Read Blogs: Elevate Your Data Quality: Unleashing the Power of AI and ML for Scaling Operations. The Difference Between Data Observability And Data Quality.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content