This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction Big Data is everywhere, and it continues to be a gearing-up topic these days. And DataIngestion is a process that assists a group or management to make sense of the ever-increasing volume and complexity of data and provide useful insights.
This article was published as a part of the DataScience Blogathon. Introduction to Apache Flume Apache Flume is a dataingestion mechanism for gathering, aggregating, and transmitting huge amounts of streaming data from diverse sources, such as log files, events, and so on, to a centralized data storage.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
As AI models grow and data volumes expand, databases must scale horizontally, to allow organisations to add capacity without significant downtime or performance degradation. Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation.
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
cuDF helps optimize content delivery by analyzing user data to predict demand and adjust content distribution in real time, improving overall user experiences. Along with cuML and cuDF, accelerated datascience libraries provide seamless integration with the open-source Dask library for multi-GPU or multi-node clusters.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps.
In June 2024, Databricks made three significant announcements that have garnered considerable attention in the datascience and engineering communities. These announcements focus on enhancing user experience, optimizing data management, and streamlining data engineering workflows.
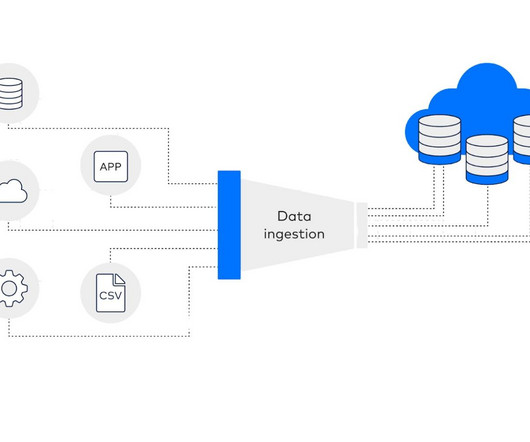
There are considered three main layers of the process data lakes use to receive and store new data. Dataingestion is when new data is introduced and absorbed into the lake. The processing layer is when data is managed and sorted into its storage category.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
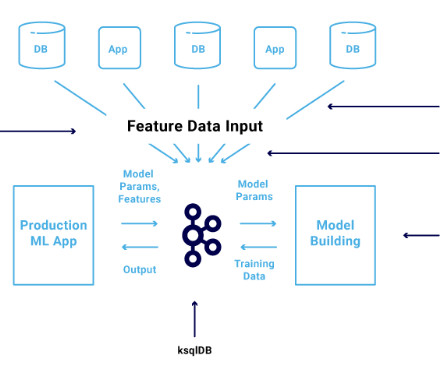
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
With the IoT, tracking website clicks, capturing call data records for a mobile network carrier, tracking events generated by “smart meters” and embedded devices can all generate huge volumes of transactions. Many consider a NoSQL database essential for high dataingestion rates.
The architectures strengths lie in its consistency across environments, automatic dataingestion processes, and comprehensive monitoring capabilities. He solves complex organizational and technical challenges using datascience and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud.
Axfood has a structure with multiple decentralized datascience teams with different areas of responsibility. Together with a central data platform team, the datascience teams bring innovation and digital transformation through AI and ML solutions to the organization.
This post dives into key steps for preparing data to build real-world ML systems. Dataingestion ensures that all relevant data is aggregated, documented, and traceable. Connecting to Data: Data may be scattered across formats, sources, and frequencies. It involves the following core operations: 1.
Originally posted on OpenDataScience.com Read more datascience articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels! You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
We created a spaCy end‐to‐end project workflow including package versioning, data pre‐processing, dataingestion into a database, annotation sessions using Prodigy’s user interface, model training, model evaluation, python packaging, and visual app for testing the model.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases.
Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation. Manoj holds a master’s degree in Computer Science specialized in DataScience from the University of North Carolina, Charlotte.
For example, you may start with wanting to solve the customer churn problem but end up uncovering a nasty data quality issue or lack of tools to build the most effective solution. This discovery may distract you with an initiative to overhaul the entire data capture system and dataingestion pipelines.
Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. The pipelines start working immediately upon dataingestion into Indexify, making them ideal for interactive applications and low-latency use cases. These pipelines are defined using declarative configuration.
Traditional Data Warehouse Architecture Bottom Tier (Database Server): This tier is responsible for storing (a process known as dataingestion ) and retrieving data. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
Each stage of the pipeline can perform structured extraction using any AI model or transform ingesteddata. The pipelines start working immediately upon dataingestion into Indexify, making them ideal for interactive applications and low-latency use cases. These pipelines are defined using declarative configuration.
Data engineering – Identifies the data sources, sets up dataingestion and pipelines, and prepares data using Data Wrangler. Datascience – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation.
Manage data through standard methods of dataingestion and use Enriching LLMs with new data is imperative for LLMs to provide more contextual answers without the need for extensive fine-tuning or the overhead of building a specific corporate LLM. Tanvi Singhal is a Data Scientist within AWS Professional Services.
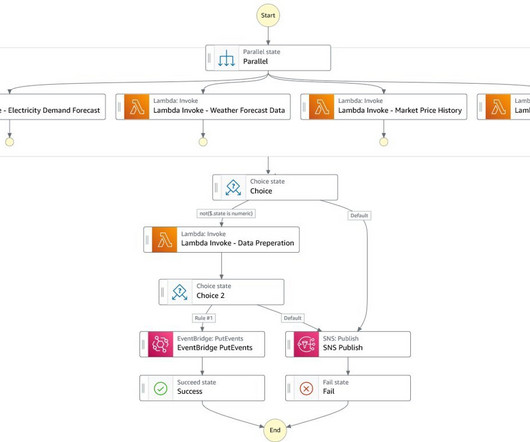
Manager DataScience at Marubeni Power International. Amazon Athena to provide developers and business analysts SQL access to the generated data for analysis and troubleshooting. Amazon EventBridge to trigger the dataingestion and ML pipeline on a schedule and in response to events. He holds a Ph.D.
MLOps focuses on the intersection of datascience and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. MLOps requires the integration of software development, operations, data engineering, and datascience.
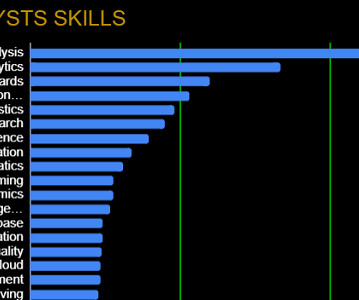
Top Data Analytics Skills and Platforms for 2023, PyTorch 2.0 Released, and 5 Huge DataScience Career Mistakes Top Data Analytics Skills and Platforms for 2023 We looked at over 25,000 job descriptions, and these are the data analytics platforms, tools, and skills that employers are looking for in 2023.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Machine Learning with XGBoost Matt Harrison | Python & DataScience Corporate Trainer | Consultant | MetaSnake Join one of the leading experts in Python for this upcoming ODSC East session. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Rather than requiring your datascience and IT teams to build and maintain AI models, you can use pre-trained AI services that can automate tasks for you. Additionally, the solution must handle high data volumes with low latency and high throughput. Suyin Wang is an AI/ML Specialist Solutions Architect at AWS.
TensorFlow Extended (TFX): End-to-End Pipeline: Providing a variety of tools and libraries for production-ready machine learning pipelines, TFX takes care of the entire lifecycle from dataingestion and validation to model training, evaluation, and deployment.
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in DataScience using Microsoft Azure. Integration: Seamlessly integrates with popular DataScience tools and frameworks, such as TensorFlow and PyTorch.
Photo by Andrew Neel on Unsplash Introduction If you are working or have worked on any datascience task then you definitely used pandas. So, pandas is a library which helps with performing dataingestion and transformations. Note for Readers — Are you a programming, AI, or machine learning enthusiast?
This evolution underscores the demand for innovative platforms that simplify dataingestion and transformation, enabling faster, more reliable decision-making. Tamer underscored the need for a disciplined approach, as errors in financial data can have widespread repercussions.
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: DataIngestion: Collecting data from various sources and ensuring it’s available for analysis. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning.
You can inspect the code for dataingestion, index creation, etc… in the notebook in my GitHub repository llamaindex-RAG-techniques. Sequential Chain Simple Chain: Prompt Query + LLM The simplest approach, define a sequential chain.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new datascience project and get it to production.
Streamlining Unstructured Data for Retrieval Augmented Generation Matt Robinson | Open Source Tech Lead | Unstructured In this talk, you’ll explore the complexities of handling unstructured data, and offer practical strategies for extracting usable text and metadata from unstructured data.
Causal AI: from Data to Action Dr. Andre Franca | CTO | connectedFlow Explore the world of Causal AI for datascience practitioners, with a focus on understanding cause-and-effect relationships within data to drive optimal decisions. Sign me up! Register for ODSC East today to save 60% on any pass.
Snowflake’s support for unstructured data management includes built-in capabilities to store, access, process, manage, govern, and share unstructured data, bringing the performance, concurrency, and scale benefits of the Snowflake Data Cloud to unstructured data. Ahmad Khan, Head of AI/ML Strategy at Snowflake.
Snowflake’s support for unstructured data management includes built-in capabilities to store, access, process, manage, govern, and share unstructured data, bringing the performance, concurrency, and scale benefits of the Snowflake Data Cloud to unstructured data. Ahmad Khan, Head of AI/ML Strategy at Snowflake.
I recently took the Azure Data Scientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft DataScience Learning Path and the Coursera Microsoft Azure Data Scientist Associate Specialization. data: this folder contains the .csv csv data files.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content