This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. Increased variance: Variance measures consistency.
The integration between the Snorkel Flow AI data development platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Here’s what that looks like in practice.
As generative AI continues to grow, the need for an efficient, automated solution to transform various data types into an LLM-ready format has become even more apparent. Meet MegaParse : an open-source tool for parsing various types of documents for LLMingestion. Check out the GitHub Page.
Existing research emphasizes the significance of distributed processing and dataquality control for enhancing LLMs. Utilizing frameworks like Slurm and Spark enables efficient big data management, while dataquality improvements through deduplication, decontamination, and sentence length adjustments refine training datasets.
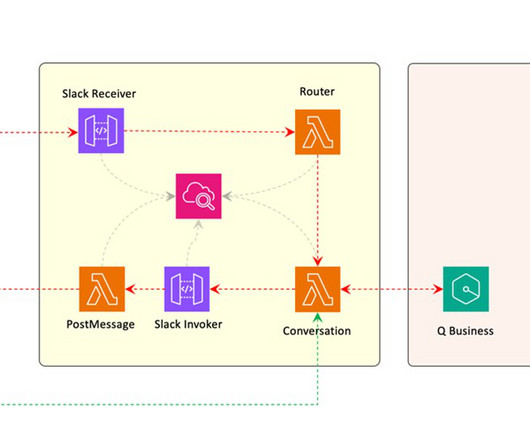
By moving our core infrastructure to Amazon Q, we no longer needed to choose a large language model (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for dataingestion and management.
Fine Tuning Strategies for Language Models and Large Language Models Kevin Noel | AI Lead at Uzabase Speeda | Uzabase Japan-US Language Models (LM) and Large Language Models (LLM) have proven to have applications across many industries. This talk provides a comprehensive framework for securing LLM applications.
It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. Finally, it offers best practices for fine-tuning, emphasizing dataquality, parameter optimization, and leveraging transfer learning techniques. This article examines data leakage in LLMs.
The integration between the Snorkel Flow AI data development platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Heres what that looks like in practice.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
As an early adopter of large language model (LLM) technology, Zeta released Email Subject Line Generation in 2021. ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content