This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
By leveraging ML and natural language processing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
The process begins with dataingestion and preprocessing, where prescriptive AI gathers information from different sources, such as IoT sensors, databases, and customer feedback. It organizes it by filtering out irrelevant details and ensuring dataquality.
Companies rely heavily on data and analytics to find and retain talent, drive engagement, improve productivity and more across enterprise talent management. However, analytics are only as good as the quality of the data, which must be error-free, trustworthy and transparent. What is dataquality? million each year.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data. What the Snorkel Flow + AWS integrations offer Streamlined dataingestion and management: With Snorkel Flow, organizations can easily access and manage unstructured data stored in Amazon S3.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
This solution addresses the complexities data engineering teams face by providing a unified platform for dataingestion, transformation, and orchestration. Image Source Key Components of LakeFlow: LakeFlow Connect: This component offers point-and-click dataingestion from numerous databases and enterprise applications.
Existing research emphasizes the significance of distributed processing and dataquality control for enhancing LLMs. Utilizing frameworks like Slurm and Spark enables efficient big data management, while dataquality improvements through deduplication, decontamination, and sentence length adjustments refine training datasets.
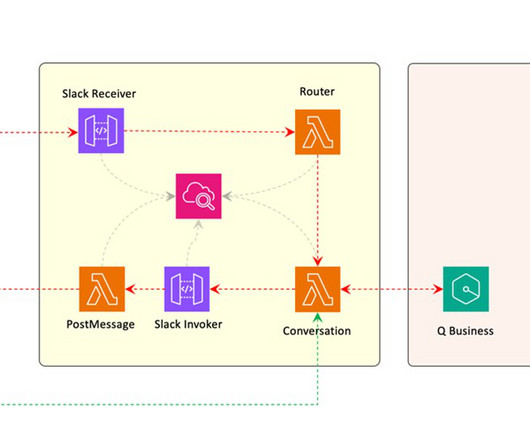
By moving our core infrastructure to Amazon Q, we no longer needed to choose a large language model (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for dataingestion and management.
The model will be approved by designated data scientists to deploy the model for use in production. For production environments, dataingestion and trigger mechanisms are managed via a primary Airflow orchestration. Workflow B corresponds to model quality drift checks.
Traditional Data Warehouse Architecture Bottom Tier (Database Server): This tier is responsible for storing (a process known as dataingestion ) and retrieving data. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
Supporting a wide range of document types and retaining all information during parsing reduces manual effort while enhancing the quality of input data for LLMs. Check out the GitHub Page. All credit for this research goes to the researchers of this project.
It emphasizes the role of LLamaindex in building RAG systems, managing dataingestion, indexing, and querying. Finally, it offers best practices for fine-tuning, emphasizing dataquality, parameter optimization, and leveraging transfer learning techniques.
A high amount of effort is spent organizing data and creating reliable metrics the business can use to make better decisions. This creates a daunting backlog of dataquality improvements and, sometimes, a graveyard of unused dashboards that have not been updated in years. Let’s start with an example.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment. An example direct acyclic graph (DAG) might automate dataingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and dataquality would be a non-negotiable, key requirement.
A new data flow is created on the Data Wrangler console. Choose Get data insights to identify potential dataquality issues and get recommendations. In the Create analysis pane, provide the following information: For Analysis type , choose DataQuality And Insights Report. For Target column , enter y.
When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data. What the Snorkel Flow + AWS integrations offer Streamlined dataingestion and management: With Snorkel Flow, organizations can easily access and manage unstructured data stored in Amazon S3.
Ensuring dataquality, governance, and security may slow down or stall ML projects. Data engineering – Identifies the data sources, sets up dataingestion and pipelines, and prepares data using Data Wrangler.
Summary : This comprehensive guide delves into data anomalies, exploring their types, causes, and detection methods. It highlights the implications of anomalies in sectors like finance and healthcare, and offers strategies for effectively addressing them to improve dataquality and decision-making processes.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. The right tool can significantly enhance efficiency, scalability, and dataquality.
DataQuality and Standardization The adage “garbage in, garbage out” holds true. Inconsistent data formats, missing values, and data bias can significantly impact the success of large-scale Data Science projects.
Efficient integration ensures data consistency and availability, which is essential for deriving accurate business insights. Step 6: Data Validation and Monitoring Ensuring dataquality and integrity throughout the pipeline lifecycle is paramount. The Difference Between Data Observability And DataQuality.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Whether you are a data engineer, analyst, or business intelligence professional, understanding these tools can help you make informed decisions for your data integration needs. Apache NiFi Apache NiFi is an open-source data integration tool that provides an intuitive user interface for designing data flows.
Example: Uber Implementation: To match riders with drivers almost instantaneously, Uber processes real-time data about ride requests, driver locations in real-time, and rider locations as well. Tooling Used: Apache Kafka is used for real-time streaming and processing of real-time data.
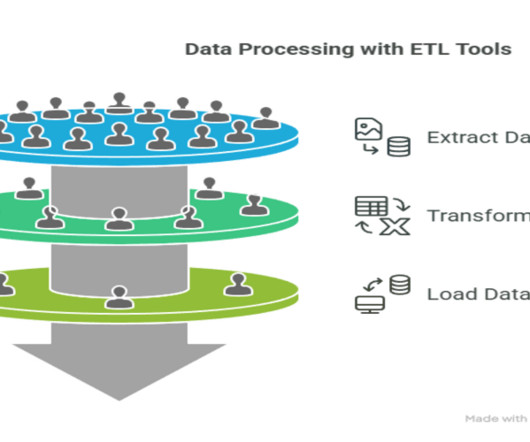
ETL facilitates Data Analytics by transforming raw data into meaningful insights, empowering businesses to uncover trends, track performance, and make strategic decisions. ETL also enhances dataquality and consistency by performing necessary data cleansing and validation during the transformation stage.
With the exponential growth of data and increasing complexities of the ecosystem, organizations face the challenge of ensuring data security and compliance with regulations. Although Data Governance is not mandatory, it works with dataquality and Master Data Management Tools.
This talk will cover the critical challenges faced and steps needed when transitioning from a demo to a production-quality RAG system for professional users of academic data, such as researchers, students, librarians, research officers, and others.
The key sectors where Data Engineering has a major contribution include IT, Internet/eCommerce, and Banking & Insurance. Salary of a Data Engineer ranges between ₹ 3.1 Data Storage: Storing the collected data in various storage systems, such as relational databases, NoSQL databases, data lakes, or data warehouses.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability.
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. And when the platform automates the entire process, it’ll likely produce and deploy a bad-quality model.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Dataingestion (extraction and versioning). Data validation (writing tests to check for dataquality). Data preprocessing. Let’s briefly go over each of the components below.
1 DataIngestion (e.g., Apache Kafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The next section delves into these architectural patterns, exploring how they are leveraged in machine learning pipelines to streamline dataingestion, processing, model training, and deployment.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content