This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This created a challenge for data scientists to become productive.
By helping customers integrate artificial intelligence (AI) and machine learning (ML) into their key business operations, Quantum helps customers to effectively manage and unlock meaningful value from their unstructured data, creating actionable business insights that lead to better business decisions.
This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificial intelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications. Large language models (LLMs) have taken the field of AI by storm.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
Your experience with migrations, ML ops, building a Kubernetes Operator or your depth with complex data environments leveraging BigQuery are what’s meaningful to Zencore and its clients. This led to inconsistent data standards and made it difficult for them to gain actionable insights.
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer dataplatform that simplifies the deployment and scaling of MongoDB databases in the cloud.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
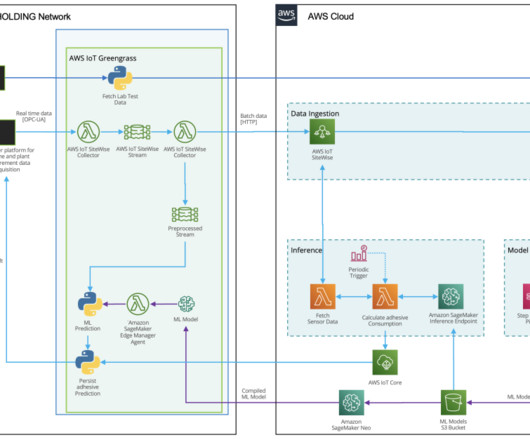
there is enormous potential to use machine learning (ML) for quality prediction. ML-based predictive quality in HAYAT HOLDING HAYAT is the world’s fourth-largest branded baby diapers manufacturer and the largest paper tissue manufacturer of the EMEA. Two types of data sources exist for this use case.
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Data pipeline stages But before delving deeper into the technical aspects of these tools, let’s quickly understand the core components of a data pipeline succinctly captured in the image below: Data pipeline stages | Source: Author What does a good data pipeline look like? Uses secure protocols for data security.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
Data Democratization on AWS Amazon QuickSight: Empower users with fast, easy-to-use BI service with natural language querying. AWS Data Exchange: Access third-party datasets directly within AWS. Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale.
Data Democratization on AWS Amazon QuickSight: Empower users with fast, easy-to-use BI service with natural language querying. AWS Data Exchange: Access third-party datasets directly within AWS. Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale.
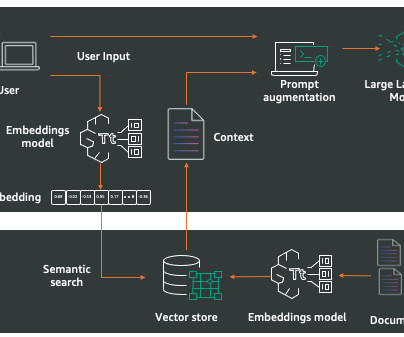
Retrieval Augmented Generation Amazon Bedrock Knowledge Bases gives FMs contextual information from your private data sources for RAG to deliver more relevant, accurate, and customized responses. The RAG workflow consists of two key components: dataingestion and text generation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content