This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Keeping track of how exactly the incoming data (the feature pipeline’s input) has to be transformed and ensuring that each model receives the features precisely how it saw them during training is one of the hardest parts of architecting ML systems. This is where feature stores come in. What is a feature store?
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
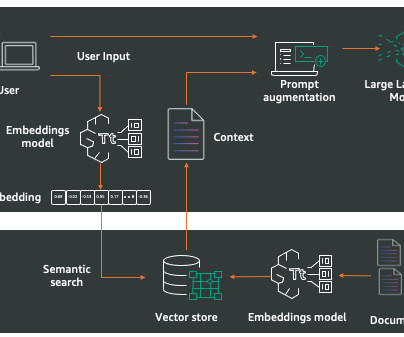
Retrieval Augmented Generation Amazon Bedrock Knowledge Bases gives FMs contextual information from your private data sources for RAG to deliver more relevant, accurate, and customized responses. The RAG workflow consists of two key components: dataingestion and text generation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









Let's personalize your content