This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A good place to start is refreshing the way organizations govern data, particularly as it pertains to its usage in generative AI solutions. For example: Validating and creating data protection capabilities : Dataplatforms must be prepped for higher levels of protection and monitoring.
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
Overcoming challenges means addressing dataingestion bottlenecks, hybrid cloud AI model distribution, robust model safeguarding through advanced encryption and governance for trustworthiness.
Rockets legacy data science architecture is shown in the following diagram. The diagram depicts the flow; the key components are detailed below: DataIngestion: Data is ingested into the system using Attunity dataingestion in Spark SQL.
A long-standing partnership between IBM Human Resources and IBM Global Chief Data Office (GCDO) aided in the recent creation of Workforce 360 (Wf360), a workforce planning solution using IBM’s Cognitive Enterprise DataPlatform (CEDP). Data quality is a key component for trusted talent insights.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a DataPlatform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Dataplatforms & Data Governance.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps. IBM watsonx consists of the following: IBM watsonx.ai
Oftentimes, this requires implementing a “hot” part of the initial dataingest, or landing zone where applications and users can work as fast as possible. How does Quantum plan to stay ahead in the rapidly evolving AI and data management landscape? In today’s world, being merely a “storage provider” is not enough.
Although migration work is a key component of our business, it’s the dataplatform engagements that really stand out when you’re talking about value to the business. This led to inconsistent data standards and made it difficult for them to gain actionable insights. The impact of these efforts was transformative.
The teams built a new dataingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. Principal and AWS collaborated on a new AWS Lambda function that was added to the Step Functions workflow.
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
Axfood has a structure with multiple decentralized data science teams with different areas of responsibility. Together with a central dataplatform team, the data science teams bring innovation and digital transformation through AI and ML solutions to the organization.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer dataplatform that simplifies the deployment and scaling of MongoDB databases in the cloud.
While a traditional data center typically handles diverse workloads and is built for general-purpose computing, AI factories are optimized to create value from AI. They orchestrate the entire AI lifecycle from dataingestion to training, fine-tuning and, most critically, high-volume inference.
Snowflake Data Engineering Solutions Maximize the potential of your data with Snowflakes data cloud. Our services harness Snowflakes powerful features to architect, build, and manage a modern dataplatform. Secure Data Sharing: Share data securely within and across organizations.
Snowflake Data Engineering Solutions Maximize the potential of your data with Snowflake’s data cloud. Our services harness Snowflake’s powerful features to architect, build, and manage a modern dataplatform. Secure Data Sharing: Share data securely within and across organizations.
Whether you aim for comprehensive data integration or impactful visual insights, this comparison will clarify the best fit for your goals. Key Takeaways Microsoft Fabric is a full-scale dataplatform, while Power BI focuses on visualising insights. Fabric suits large enterprises; Power BI fits team-level reporting needs.
Keeping track of how exactly the incoming data (the feature pipeline’s input) has to be transformed and ensuring that each model receives the features precisely how it saw them during training is one of the hardest parts of architecting ML systems. This is where feature stores come in. What is a feature store?
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Attend Snowflake University Snowflake has an online university that aims to educate users with all levels of expertise through a variety of courses.
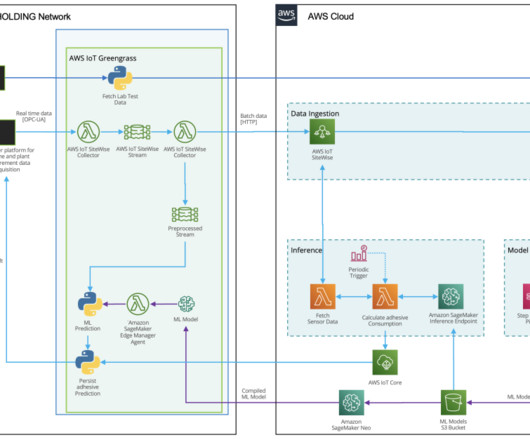
Dataingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Two types of data sources exist for this use case. HAYAT KIMYA integrated the ML solution in one of its plants.
Its drag-and-drop interface makes it user-friendly, allowing data engineers to build complex workflows without extensive coding knowledge. Nifi excels in dataingestion, routing, transformation, and system-to-system data flow management.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
Advantages of Using Splunk Real-time Visibility One of the significant advantages of Splunk is its ability to provide real-time data visibility. Thus, it lets users gain insights from vast data in real time. Additionally, it also supports a host of data formats. Thereby enabling faster decision-making and problem-solving.
Streaming dataplatforms: Apache Kafka and Apache Flink enable real-time ingestion and processing of user actions, clickstream data, and product catalogs, feeding fresh data to the models.
Arjuna Chala, associate vice president, HPCC Systems For those not familiar with the HPCC Systems data lake platform, can you describe your organization and the development history behind HPCC Systems? They were interested in creating a dataplatform capable of managing a sizable number of datasets.
Data Estate: This element represents the organizational data estate, potential data sources, and targets for a data science project. Data Engineers would be the primary owners of this element of the MLOps v2 lifecycle. The Azure dataplatforms in this diagram are neither exhaustive nor prescriptive.
Tools range from dataplatforms to vector databases, embedding providers, fine-tuning platforms, prompt engineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. Develop the text preprocessing pipeline Dataingestion: Use Unstructured.io
They work with other users to make sure the data reflects the business problem, the experimentation process is good enough for the business, and the results reflect what would be valuable to the business. What do they want to accomplish?
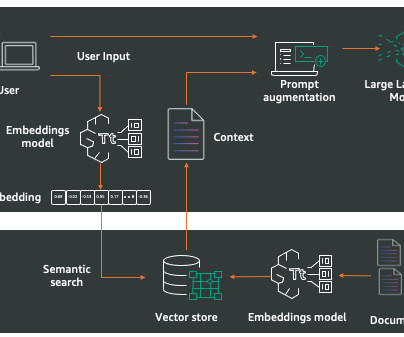
Retrieval Augmented Generation Amazon Bedrock Knowledge Bases gives FMs contextual information from your private data sources for RAG to deliver more relevant, accurate, and customized responses. The RAG workflow consists of two key components: dataingestion and text generation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content