This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality dataintegration problem of low-cost sensors. This is done to optimize performance and minimize cost of LLM invocation.
Table Search and Filtering: Integrated search and filtering functionalities allow users to find specific columns or values and filter data to spot trends and identify essential values. Enhanced Python Features: New Python coding capabilities include an interactive debugger, error highlighting, and enhanced code navigation features.
ELT Pipelines: Typically used for big data, these pipelines extract data, load it into data warehouses or lakes, and then transform it. DataIntegration, Ingestion, and Transformation Pipelines: These pipelines handle the organization of data from multiple sources, ensuring that it is properly integrated and transformed for use.
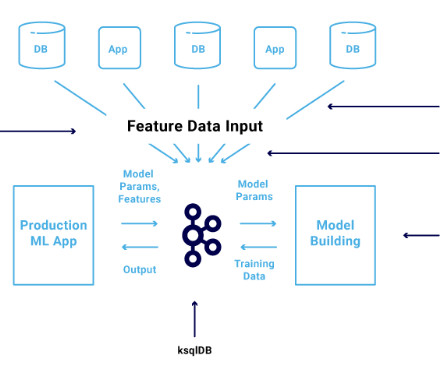
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. I had previously discussed example use cases and architectures that leverage Apache Kafka and machine learning.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for data labeling, data versioning, data augmentation, and integration with popular data storage systems.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
The key sectors where Data Engineering has a major contribution include IT, Internet/eCommerce, and Banking & Insurance. Salary of a Data Engineer ranges between ₹ 3.1 Data Storage: Storing the collected data in various storage systems, such as relational databases, NoSQL databases, data lakes, or data warehouses.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
These skills enable professionals to leverage Azure’s cloud technologies effectively and address complex data challenges. Below are the essential skills required for thriving in this role: Programming Proficiency: Expertise in languages such as Python or R for coding and data manipulation.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content