This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
This requires traditional capabilities like encryption, anonymization and tokenization, but also creating capabilities to automatically classify data (sensitivity, taxonomy alignment) by using machinelearning.
Be sure to check out his talk, “ Apache Kafka for Real-Time MachineLearning Without a Data Lake ,” there! The combination of data streaming and machinelearning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machinelearning tasks using the Apache Kafka ecosystem.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
Data scientists often spend up to 80% of their time on data engineering in data science projects. Objective of Data Engineering: The main goal is to transform raw data into structured data suitable for downstream tasks such as machinelearning.
This granularity supports better version control and data lineage tracking, which are crucial for dataintegrity and compliance. Additionally, field-specific chunking aids in organizing and maintaining large datasets, facilitating updating or modifying specific portions without affecting the whole.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrateddata, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The pipeline ensures correct, complete, and consistent data.
More than 170 tech teams used the latest cloud, machinelearning and artificial intelligence technologies to build 33 solutions. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
The company’s approach allows businesses to efficiently handle data growth while ensuring security and flexibility throughout the data lifecycle. Can you provide an overview of Quantum’s approach to AI-driven data management for unstructured data?
This solution addresses the complexities data engineering teams face by providing a unified platform for dataingestion, transformation, and orchestration. Image Source Key Components of LakeFlow: LakeFlow Connect: This component offers point-and-click dataingestion from numerous databases and enterprise applications.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. Tanvi Singhal is a Data Scientist within AWS Professional Services.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Many existing LLMs require specific formats and well-structured data to function effectively. Parsing and transforming different types of documents—ranging from PDFs to Word files—for machinelearning tasks can be tedious, often leading to information loss or requiring extensive manual intervention. Check out the GitHub Page.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
We know Google Cloud inside and out, including key areas like data cloud, machinelearning, AI, and Kubernetes. Lastly, the integration of generative AI is set to revolutionize business operations across various industries. Next, we focused on enhancing their dataingestion and validation processes.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like MachineLearning. Aggregation : Combining multiple data points into a single summary (e.g.,
This layer includes tools and frameworks for data processing, such as Apache Hadoop, Apache Spark, and dataintegration tools. Data as a Service (DaaS) DaaS allows organisations to access and integratedata from various sources without the need for complex data management.
The objective is to guide businesses, Data Analysts, and decision-makers in choosing the right tool for their needs. Whether you aim for comprehensive dataintegration or impactful visual insights, this comparison will clarify the best fit for your goals.
As businesses increasingly turn to cloud solutions, Azure stands out as a leading platform for Data Science, offering powerful tools and services for advanced analytics and MachineLearning. This roadmap aims to guide aspiring Azure Data Scientists through the essential steps to build a successful career.
Fraudulent Behaviour : Deliberate manipulation of data for personal gain can create anomalies that may go unnoticed without proper detection methods. Detecting Data Anomalies Detecting data anomalies involves various techniques and methods, which can be broadly categorised into statistical and MachineLearning approaches.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
This includes removing duplicates, correcting typos, and standardizing data formats. It forms the bedrock of data quality improvement. Implement Data Validation Rules To maintain dataintegrity, establish strict validation rules. This ensures that the data entered meets predefined criteria.
The key sectors where Data Engineering has a major contribution include IT, Internet/eCommerce, and Banking & Insurance. Salary of a Data Engineer ranges between ₹ 3.1 Data Storage: Storing the collected data in various storage systems, such as relational databases, NoSQL databases, data lakes, or data warehouses.
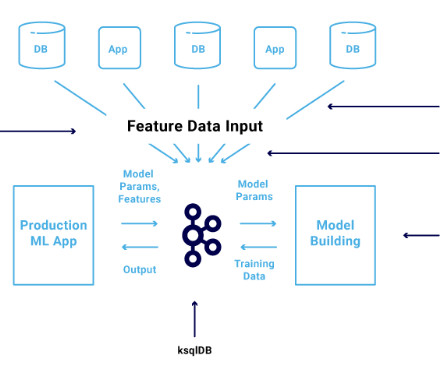
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
By leveraging machinelearning algorithms, companies can prioritize leads, schedule follow-ups, and handle customer service queries accurately. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics. Therefore, concerns about data privacy might emerge at any stage.
By processing data closer to where it resides, SnapLogic promotes faster, more efficient operations that meet stringent regulatory requirements, ultimately delivering a superior experience for businesses relying on their dataintegration and management solutions. Dhawal Patel is a Principal MachineLearning Architect at AWS.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content