This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
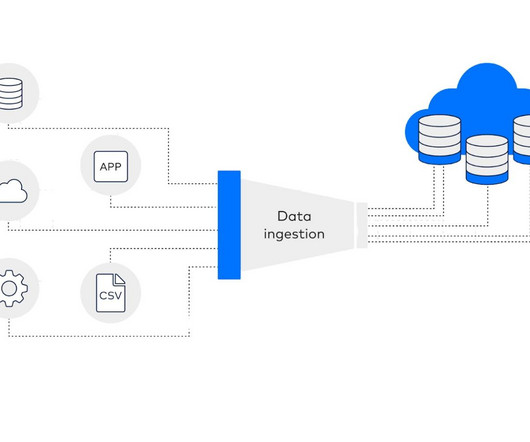
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. A popular method is extract, load, transform (ELT).
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Enterprise data is often complex, diverse and scattered across various repositories, making it difficult to integrate into gen AI solutions. This complexity is compounded by the need to ensure regulatory compliance, mitigate risk, and address skill gaps in dataintegration and retrieval-augmented generation (RAG) patterns.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrateddata, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. Data Sources: Data sources provide information and context to a data warehouse.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion.
Quantum provides end-to-end data solutions that help organizations manage, enrich, and protect unstructured data, such as video and audio files, at scale. Their technology focuses on transforming data into valuable insights, enabling businesses to extract value and make informed decisions.
Many existing LLMs require specific formats and well-structured data to function effectively. Parsing and transforming different types of documents—ranging from PDFs to Word files—for machine learning tasks can be tedious, often leading to information loss or requiring extensive manual intervention. Unstructured with Check Table 0.77
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automate data flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. What is Apache NiFi?
Customer 360 initiatives are designed to bring together relevant information about individual consumers from different touch points, including but not limited to sales, marketing, customer service, and social media platforms. How Data Engineering Enhances Customer 360 Initiatives 1.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. ETL stands for Extract, Transform, Load.
Introduction to BDaaS In today’s data-driven world, organisations are inundated with vast amounts of information generated from various sources. This explosion of data presents both opportunities and challenges. It provides APIs and data connectors to facilitate dataingestion, transformation, and delivery.
It covers best practices for ensuring scalability, reliability, and performance while addressing common challenges, enabling businesses to transform raw data into valuable, actionable insights for informed decision-making. What are Data Pipelines?
Enhances Transparency Transparency while documenting data is important. It allows the organizations to understand when the data was collected and when it was added to the system and other information. This establishes data accountability. Thus reducing the risk of misuse of data. The same applies to data.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
The objective is to guide businesses, Data Analysts, and decision-makers in choosing the right tool for their needs. Whether you aim for comprehensive dataintegration or impactful visual insights, this comparison will clarify the best fit for your goals.
Introduction Data transformation plays a crucial role in data processing by ensuring that raw data is properly structured and optimised for analysis. Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors.
Hence, the quality of data is significant here. Quality data fuels business decisions, informs scientific research, drives technological innovations, and shapes our understanding of the world. The Relevance of Data Quality Data quality refers to the accuracy, completeness, consistency, and reliability of data.
This is what data processing pipelines do for you. Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions.
This service enables Data Scientists to query data on their terms using serverless or provisioned resources at scale. It also integrates deeply with Power BI and Azure Machine Learning, providing a seamless workflow from dataingestion to advanced analytics.
On the other hand, AI-powered CRMs are faster and provide actionable insights based on real-time data. The collected data is more accurate, which leads to better customer information. On the operations front, it enables data democratization and ensures data governance.
By processing data closer to where it resides, SnapLogic promotes faster, more efficient operations that meet stringent regulatory requirements, ultimately delivering a superior experience for businesses relying on their dataintegration and management solutions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content