This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
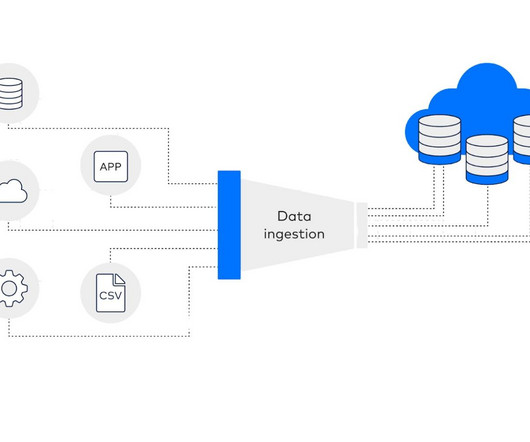
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
In June 2024, Databricks made three significant announcements that have garnered considerable attention in the datascience and engineering communities. These announcements focus on enhancing user experience, optimizing data management, and streamlining data engineering workflows.
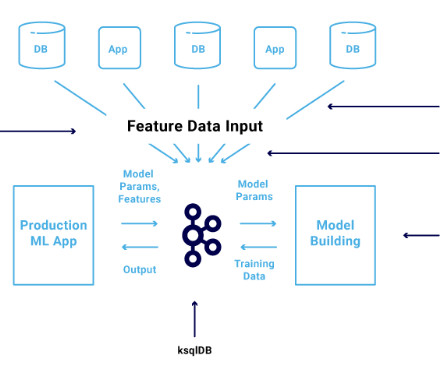
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
These can include structured databases, log files, CSV files, transaction tables, third-party business tools, sensor data, etc. The pipeline ensures correct, complete, and consistent data. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. Tanvi Singhal is a Data Scientist within AWS Professional Services.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in DataScience using Microsoft Azure. Integration: Seamlessly integrates with popular DataScience tools and frameworks, such as TensorFlow and PyTorch.
Data Engineering plays a critical role in enabling organizations to efficiently collect, store, process, and analyze large volumes of data. It is a field of expertise within the broader domain of data management and DataScience. Salary of a Data Engineer ranges between ₹ 3.1 Lakhs to ₹ 20.0
The objective is to guide businesses, Data Analysts, and decision-makers in choosing the right tool for their needs. Whether you aim for comprehensive dataintegration or impactful visual insights, this comparison will clarify the best fit for your goals.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Introduction Data transformation plays a crucial role in data processing by ensuring that raw data is properly structured and optimised for analysis. Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors.
This layer includes tools and frameworks for data processing, such as Apache Hadoop, Apache Spark, and dataintegration tools. Data as a Service (DaaS) DaaS allows organisations to access and integratedata from various sources without the need for complex data management.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
This includes removing duplicates, correcting typos, and standardizing data formats. It forms the bedrock of data quality improvement. Implement Data Validation Rules To maintain dataintegrity, establish strict validation rules. This ensures that the data entered meets predefined criteria.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content