This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
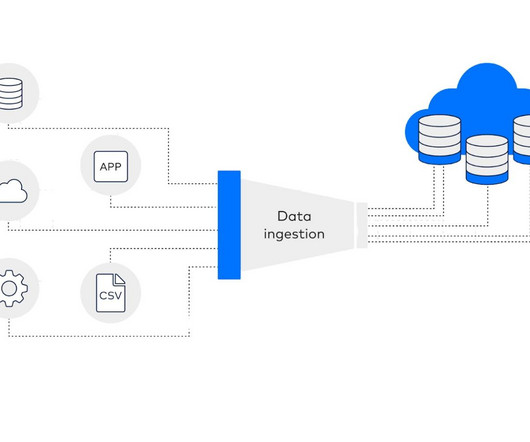
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. A popular method is extract, load, transform (ELT).
By leveraging ML and natural language processing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
Enterprise data is often complex, diverse and scattered across various repositories, making it difficult to integrate into gen AI solutions. This complexity is compounded by the need to ensure regulatory compliance, mitigate risk, and address skill gaps in dataintegration and retrieval-augmented generation (RAG) patterns.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
This granularity supports better version control and data lineage tracking, which are crucial for dataintegrity and compliance. Additionally, field-specific chunking aids in organizing and maintaining large datasets, facilitating updating or modifying specific portions without affecting the whole.
ELT Pipelines: Typically used for big data, these pipelines extract data, load it into data warehouses or lakes, and then transform it. DataIntegration, Ingestion, and Transformation Pipelines: These pipelines handle the organization of data from multiple sources, ensuring that it is properly integrated and transformed for use.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality dataintegration problem of low-cost sensors. A human-in-the-loop mechanism safeguards dataingestion.
This solution addresses the complexities data engineering teams face by providing a unified platform for dataingestion, transformation, and orchestration. Image Source Key Components of LakeFlow: LakeFlow Connect: This component offers point-and-click dataingestion from numerous databases and enterprise applications.
These can include structured databases, log files, CSV files, transaction tables, third-party business tools, sensor data, etc. The pipeline ensures correct, complete, and consistent data. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
By processing data closer to where it resides, SnapLogic promotes faster, more efficient operations that meet stringent regulatory requirements, ultimately delivering a superior experience for businesses relying on their dataintegration and management solutions. He currently is working on Generative AI for dataintegration.
For instance, weekly talent reports generated for IBM’s CHRO and CEO needed to be 100% clear of inaccuracies in the data. What’s more, while the HR team members had scripts to check for dataingestion errors and dataintegrity, they lacked a solution that could proactively identified business errors within the data.
By facilitating efficient dataintegration and enhancing LLM performance, LlamaIndex is tailored for scenarios where rapid, accurate access to structured data is paramount. Key Features of LlamaIndex: Data Connectors: Facilitates the integration of various data sources, simplifying the dataingestion process.
Oftentimes, this requires implementing a “hot” part of the initial dataingest, or landing zone where applications and users can work as fast as possible. Intelligent automation tools manage data movement, backup, and compliance tasks based on set policies, ensuring consistent application, and reducing administrative burdens.
Both approaches were typically monolithic and centralized architectures organized around mechanical functions of dataingestion, processing, cleansing, aggregation, and serving.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automate data flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. What is Apache NiFi?
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
Whether users need data from structured Excel spreadsheets or more unstructured formats like PowerPoint presentations, MegaParse provides efficient parsing while maintaining dataintegrity. Check out the GitHub Page.
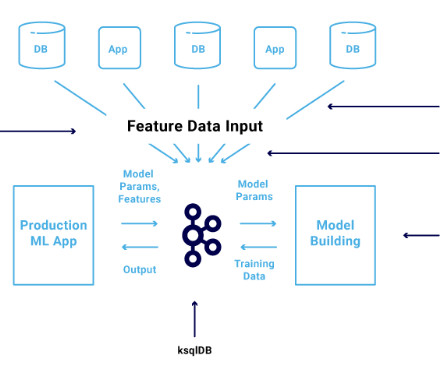
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for dataingestion, preprocessing, model training, real-time predictions, and monitoring. I had previously discussed example use cases and architectures that leverage Apache Kafka and machine learning.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their dataintegration processes for better analytics and decision-making. Introduction In todays data-driven world, organizations are overwhelmed with vast amounts of information. What is ETL?
Next, we focused on enhancing their dataingestion and validation processes. By implementing and automating their data job orchestration and integrating CI/CD pipelines, we ensured that their dataingestion was reliable and timely.
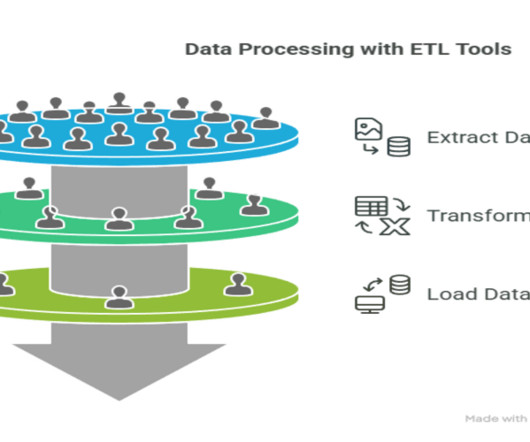
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances dataintegrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Example: Amazon Implementation: Amazon employs integration of information interfaced by its online shopping platform, Alexa conversations, and usage of Prime Video service, among others. Tools Used: AWS glue for dataintegration and transformation. Reduced redundancy: 45% lessened in identical customer profiles.
The objective is to guide businesses, Data Analysts, and decision-makers in choosing the right tool for their needs. Whether you aim for comprehensive dataintegration or impactful visual insights, this comparison will clarify the best fit for your goals.
This layer includes tools and frameworks for data processing, such as Apache Hadoop, Apache Spark, and dataintegration tools. Data as a Service (DaaS) DaaS allows organisations to access and integratedata from various sources without the need for complex data management.
Introduction Data transformation plays a crucial role in data processing by ensuring that raw data is properly structured and optimised for analysis. Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors.
The same applies to data. Improved DataIntegration and Collaboration Since Data Governance establishes data standards and definitions, it promotes data sharing and exchange among business units. It also fosters collaboration amongst different stakeholders, thus facilitating communication and data sharing.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
This blog explains how to build data pipelines and provides clear steps and best practices. From data collection to final delivery, we explore how these pipelines streamline processes, enhance decision-making capabilities, and ensure dataintegrity. What are Data Pipelines?
Training and Awareness Educating staff and their implications can foster a culture of data quality and integrity within the organisation. As the importance of data continues to grow across industries, the ability to detect and manage data anomalies will remain a vital skill for data analysts, scientists, and decision-makers.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. DataIngestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
The key sectors where Data Engineering has a major contribution include IT, Internet/eCommerce, and Banking & Insurance. Salary of a Data Engineer ranges between ₹ 3.1 Data Storage: Storing the collected data in various storage systems, such as relational databases, NoSQL databases, data lakes, or data warehouses.
This includes removing duplicates, correcting typos, and standardizing data formats. It forms the bedrock of data quality improvement. Implement Data Validation Rules To maintain dataintegrity, establish strict validation rules. This ensures that the data entered meets predefined criteria.
This service enables Data Scientists to query data on their terms using serverless or provisioned resources at scale. It also integrates deeply with Power BI and Azure Machine Learning, providing a seamless workflow from dataingestion to advanced analytics.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content