This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Guide For Data Analysis: From DataExtraction to Dashboard appeared first on Analytics Vidhya. Unlike hackathons, where we are supposed to come up with a theme-oriented project within the stipulated time, blogathons are different. Blogathons are competitions that are conducted for over a month […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction: DataExtraction is the process of extractingdata from various. The post DataExtraction from Unstructured PDFs appeared first on Analytics Vidhya.
Instead, leveraging CV dataextraction to focus on how well key job requirements align with a candidate’s CV can lead to a successful match for both the employer […] The post CV DataExtraction: Essential Tools and Methods for Recruitment appeared first on Analytics Vidhya.
Introduction Filtering a list is a fundamental operation in Python that allows us to extract specific elements from a list based on certain criteria. Whether you want to remove unwanted data, extract particular values, or apply complex conditions, mastering the art of list filtering is essential for efficient data manipulation.
Introduction The purpose of this project is to develop a Python program that automates the process of monitoring and tracking changes across multiple websites. We aim to streamline the meticulous task of detecting and documenting modifications in web-based content by utilizing Python.
This tutorial will teach you how to build stock trading algorithms using primitive technical indicators like MACD, SMA, EMA, […] The post Building and Validating Simple Stock Trading Algorithms Using Python appeared first on Analytics Vidhya.
The post Data Science Project: Scraping YouTube Data using Python and Selenium to Classify Videos appeared first on Analytics Vidhya. This article was submitted as part of Analytics Vidhya’s Internship Challenge. Introduction I’m an avid YouTube user. The sheer amount of content I can.
Unlike screen scraping, which simply captures the pixels displayed on a screen, web scraping captures the underlying HTML code along with the data stored in the corresponding database. This approach is among the most efficient and effective methods for dataextraction from websites.
Collecting this data can be time-consuming and prone to errors, presenting a significant challenge in data-driven industries. Traditionally, web scraping tools have been utilized to automate the process of dataextraction. Unlike traditional tools, this innovative solution allows users to describe the needed data.
With the growing need for automation in dataextraction, OCR tools have become an essential part of many applications, from digitizing documents to extracting information from scanned images. Optical Character Recognition (OCR) is a powerful technology that converts images of text into machine-readable content.
Please see the data provided below, which will be used for the purpose of this blog. It can analyze the text-based input provided by the user, interpret the query, and generate a response based on the content of the tabular data. Instead, we can use ChatGPT to generate SQL statements for a database that contains the data.
Dialogue DataExtraction using LeMUR and JSON. Audio File Processing with LLMs through LeMUR. Read more>> How to use audio data in LangChain with Python : Learn how to integrate audio files seamlessly into LangChain. Automatically Generate Action Items from a Meeting with LeMUR.
I realise this isn’t ground breaking stuff and it’s not showing some highfalutin function in python that’ll blow your socks off. Preparation I’ll be using Jupyter notebook and Python 3.11. Create your environment % conda create --name crimes python=3.11 This will create an environment named “crimes” and install Python 3.11
Firecrawl is a vital tool for data scientists because it addresses these issues head-on. This guarantees a complete dataextraction procedure by ensuring that no important data is lost. With this orchestration, users are guaranteed to receive the data they require promptly and effectively.
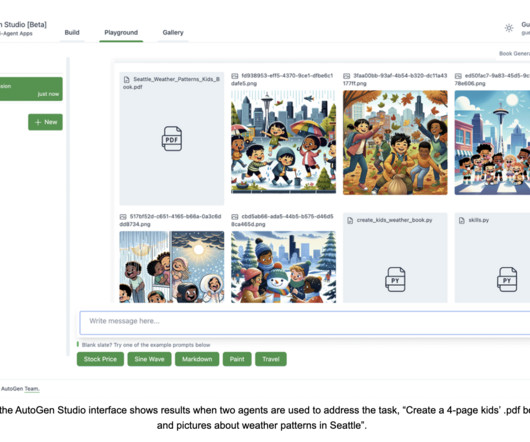
The Evolution of AutoGen In September 2023, Microsoft Research introduced AutoGen , a versatile, open-source Python-based framework that enables the configuration and orchestration of AI agents to facilitate multi-agent applications.
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and dataextraction, among other skills. Versatile Toolset Exposure : Including Python, Java, TensorFlow, and Keras.
Data products are accessible across the organization, resolving pain points for both business and technical producers. Streamlined data delivery Data producers can deliver data products to data consumers by using either dataextract or live access using flight service delivery method.
Extraction with a multi-modal language model The architecture uses a multi-modal LLM to perform extraction of data from various multi-lingual documents. We specifically used the Rhubarb Python framework to extract JSON schema -based data from the documents.
In this blog, we delve into the characteristics that define scripting languages, explore whether Python fits this classification, and provide examples to illustrate Python’s scripting capabilities. Rapid Prototyping : Python’s scripting capabilities facilitate quick prototyping and iterative development.
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models.
DataExtraction This project explores how data from Reddit, a widely used platform for discussions and content sharing, can be utilized to analyze global sentiment trends.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Getting complete and high-performance data is not always the case. The post How to Fetch Data using API and SQL databases! appeared first on Analytics Vidhya.
I believe big companies would not use these tools but have their programmers build scripts to scrape websites, which is more convenient for collecting large amounts of data. In case you’re not into coding or would like to learn easy ways to collect data, this article is for you. You can quickly scrape web data without coding.
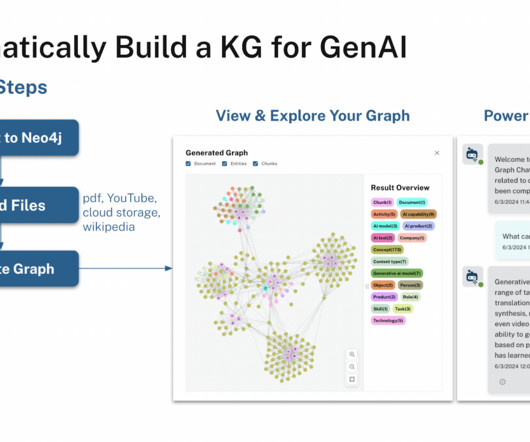
The program works well with long-form English text, but it does not work as well with tabular data, such as that found in Excel or CSV files or images that include presentations or diagrams. After building the knowledge graph, users can query their data using several Retrieval-Augmented Generation (RAG) techniques.
GPT-4o Mini : A lower-cost version of GPT-4o with vision capabilities and smaller scale, providing a balance between performance and cost Code Interpreter : This feature, now a part of GPT-4, allows for executing Python code in real-time, making it perfect for enterprise needs such as data analysis, visualization, and automation.
These tools offer a variety of choices to effectively extract, process, and analyze data from various web sources. Scrapy A powerful, open-source Python framework called Scrapy was created for highly effective web scraping and dataextraction.
In this tutorial, we will guide you through building an advanced financial data reporting tool on Google Colab by combining multiple Python libraries. Youll learn how to scrape live financial data from web pages, retrieve historical stock data using yfinance, and visualize trends with matplotlib.
Recognizing and adapting to these variations can be a complex task during dataextraction. To improve dataextraction, organizations often employ manual verification and validation processes, which increases the cost and time of the extraction process. python -m pip install amazon-textract-caller --upgrade !python
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Key Features: Customizable connectors, automated data syncing, open-source. Pros: Available as a library in Python, one of the largest user communities, flexible sync frequency. Astera Astera is an AI-powered no-code data management platform that allows businesses to effortlessly perform end-to-end data management.
Introduction In the ever-evolving landscape of data processing, extracting structured information from PDFs remains a formidable challenge, even in 2024. While numerous models excel at question-answering tasks, the real complexity lies in transforming unstructured PDF content into organized, actionable data.
It allows us to gather information from web pages and use it for various purposes, such as data analysis, research, or building applications. Project Overview The GitHub Topics Scraper is implemented using Python and utilizes the following libraries: requests: Used for making HTTP requests to retrieve the HTML content of web pages.
Key Features: Customizable connectors, automated data syncing, open-source. Pros: Available as a library in Python, one of the largest user communities, flexible sync frequency. Visit SAP Data Services → 10. Airbyte has a 300+ library of connectors and the functionality to create custom ones.
One of the key features of the o1 models is their ability to work efficiently across different domains, including natural language processing (NLP), dataextraction, summarization, and even code generation. o1 models also excel in tasks requiring detailed comprehension and information extraction from complex texts.
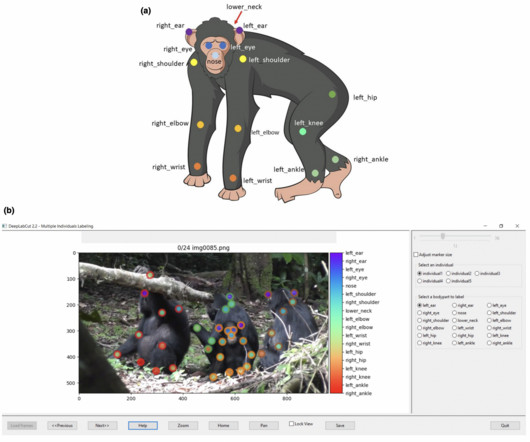
Video coding is preferred for collecting detailed behavioral data, but manually extracting information from extensive video footage is time-consuming. Machine learning has emerged as a solution, automating dataextraction and improving efficiency while maintaining reliability.
Say I don’t know the difference between tuples and lists/dictionaries in Python. Course: Web Scraping in Python BeautifulSoup, Selenium & Scrapy 2023 Instructor: Frank Andrade Rating: 4.4 Number of ratings: 1,087 Hours: 10 total hours Finally, we get a link with a CSV file that has the dataextracted.
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library.
The few-shot approach enhances the model’s ability to perform diverse tasks, making it a powerful tool for applications ranging from text classification to summarization and dataextraction.
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of BeautifulSoup} Image by Author Behold the wondrous marvel known as BeautifulSoup, a mighty Python library renowned for its prowess in the realms of web scraping and dataextraction from HTML and XML documents.
Dataextraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data. Using programming languages like Python with high-tech platforms like NLTK and SpaCy, companies can analyze user-generated content (e.g.,
It can be useful for quick dataextraction, but it sometimes misses key publications, and it’s not possible to manually upload a series of papers we are interested in. Elicit (www.elicit.org) aims to use AI to answer research questions by summarizing the available literature.
Solution overview To personalize users’ feeds, we analyzed extensive historical data, extracting insights into features that include browsing patterns and interests. Model training Meesho used Amazon EMR with Apache Spark to process hundreds of millions of data points, depending on the model’s complexity.
Prerequisites To start experimenting with Selective Execution, we need to first set up the following components of your SageMaker environment: SageMaker Python SDK – Ensure that you have an updated SageMaker Python SDK installed in your Python environment. or higher: python3 -m pip install sagemaker>=2.162.0
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































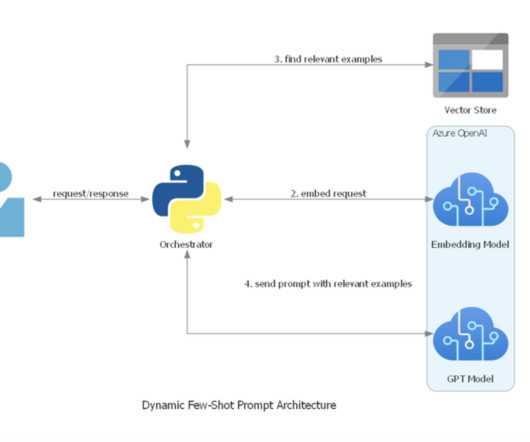




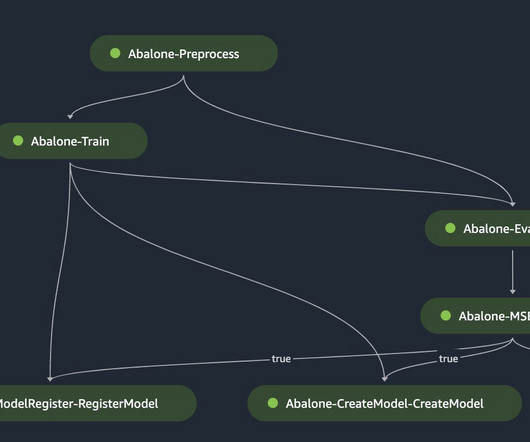






Let's personalize your content