This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
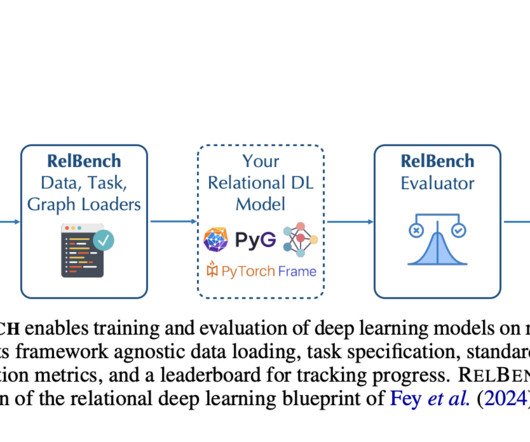
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. The solution integrates data in three tiers.
Today, marketers can use AI and ML-based data-driven techniques to take their marketing strategies to the next level – through hyperpersonalization. This is also a critical differentiator between hyperpersonalization and personalization – the depth and timing of the data used. Let’s discuss it in detail.
Enterprises generate massive volumes of unstructured data, from legal contracts to customer interactions, yet extracting meaningful insights remains a challenge. Traditionally, transforming raw data into actionable intelligence has demanded significant engineering effort.
AI and ML in Untargeted Metabolomics and Exposomics: Metabolomics employs a high-throughput approach to measure a variety of metabolites and small molecules in biological samples, providing crucial insights into human health and disease. The HRMS generates data in three dimensions: mass-to-charge ratio, retention time, and abundance.
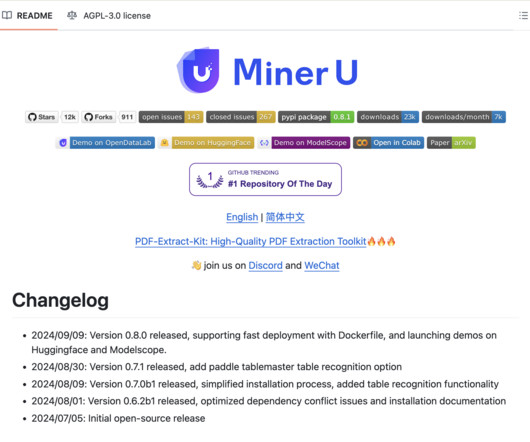
The model particularly focuses on ensuring the accurate extraction of crucial components like formulas, tables, and images, helping researchers acquire required data. MinerU’s architecture relies on natural language processing (NLP) and machine learning (ML) techniques to extract and organize data effectively.
With the growing need for automation in dataextraction, OCR tools have become an essential part of many applications, from digitizing documents to extracting information from scanned images. Dont Forget to join our 80k+ ML SubReddit. Here is the Colab Notebook.
While personalization is nothing new to brands, AI and ML technology allows brands to enter new levels of customer personalization to meet the high consumer expectations. What AI-driven personalization strategies can brands implement to enhance customer experiences?
Additionally, well cover real-world examples of processes such as: A mortgage lender that used AI-driven dataextraction to reduce mortgage processing times from 16 weeks to 10 weeks. A financial services company that achieved a four-fold reduction in dataextraction time from trade-related emails.
Simplifying DataExtraction with LangChain Agents Retrieving data from a database is seldom a straightforward endeavor. Non-technical users often lack both the time and the knowledge to figure out complex queries that match their data needs. The future of data interaction is here, and you’re a part of it.
It can handle multiple URLs simultaneously, making it suitable for large-scale data collection. Moreover, Crawl4AI offers features such as user-agent customization, JavaScript execution for dynamic dataextraction, and proxy support to bypass web restrictions, enhancing its versatility compared to traditional crawlers.
Firecrawl is a vital tool for data scientists because it addresses these issues head-on. This guarantees a complete dataextraction procedure by ensuring that no important data is lost. With this orchestration, users are guaranteed to receive the data they require promptly and effectively.
This feature makes it ideal for structured dataextraction applications, such as automated financial reporting, customer service automation, and real-time AI-based decision-making systems. Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit. Check out Model on HuggingFace.
Automating the dataextraction process, especially from tables and figures, can allow researchers to focus on data analysis and interpretation rather than manual dataextraction. With quicker access to relevant data, researchers can accelerate the pace of their work and contribute to advancements in their fields.
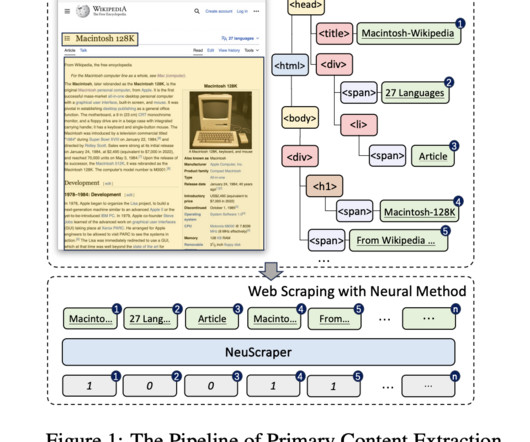
NeuScraper promises to enhance the efficiency of the web scraping process and significantly improve the quality of the dataextracted. It promises a seismic shift in how data is curated for LLM pretraining, paving the way for models that are more powerful and nuanced in their understanding of language.
We obviously leverage a lot of technical machine learning components, but I view the real ML algorithm as the customer benefits of our open platform. Another example of our ML algorithm is the assessment and delivery of degradations in temperature and gases. In data science, degradation in temperature is reflected through derivatives.
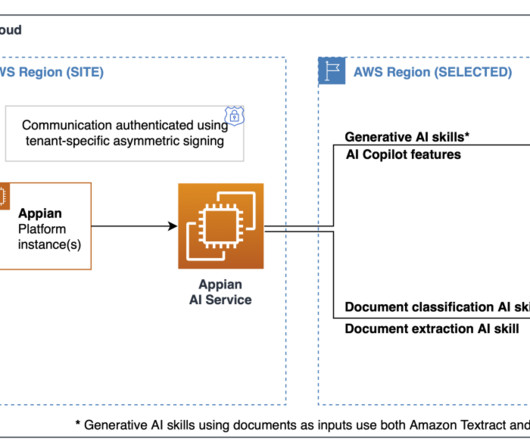
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
This enables companies to serve more clients, direct employees to higher-value tasks, speed up processes, lower expenses, enhance data accuracy, and increase efficiency. Data summarization using large language models (LLMs). In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.
By leveraging the transition from pretrained DM distributions to fine-tuning data distributions, FineXtract accurately guides the generation process toward high-probability regions of the fine-tuned data distribution, enabling successful dataextraction.' Second from right, the image extracted via FineXtract.
Artificial intelligence platforms enable individuals to create, evaluate, implement and update machine learning (ML) and deep learning models in a more scalable way. AI platform tools enable knowledge workers to analyze data, formulate predictions and execute tasks with greater speed and precision than they can manually.
Many of these tools depend on static rules or wrappers that cannot cope with the variability and unpredictability of modern web interfaces, leading to inefficiencies in web interaction and dataextraction. Also, don’t forget to follow us on Twitter. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
Parsio (OCR + AI chat) Enhance your dataextraction process by adopting an AI-driven document parser. Enhance your dataextraction routines with our state-of-the-art AI-based PDF parser. Bid farewell to labor-intensive data entry, and embrace seamless, automatic dataextraction with this advanced technology.
The introduction of function calling capabilities by OpenAI in early 2023 marked a substantial advancement in the ability of language… Continue reading on MLearning.ai »
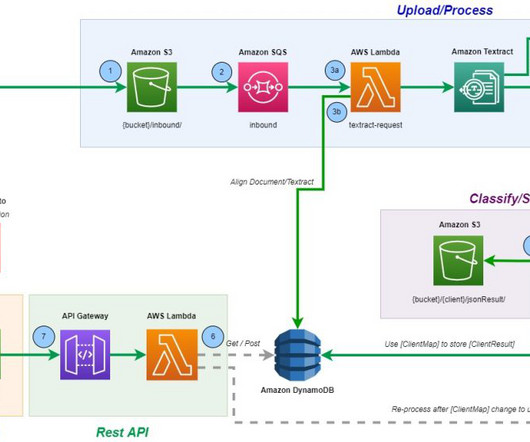
The architecture seamlessly integrates multiple AWS services with Amazon Bedrock, allowing for efficient dataextraction and comparison. Currently, she is focused on developing innovative solutions that leverage generative AI and machine learning (ML) for public sector entities.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Speed Varying data formats Data publishing What are some ways that Astera has integrated AI into customer workflow?
Traditional methods often flatten relational data into simpler formats, typically a single table. While simplifying data structure, this process leads to a substantial loss of predictive information and necessitates the creation of complex dataextraction pipelines. If you like our work, you will love our newsletter.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. For more information, refer to Custom Queries.
Its ability to understand and interpret complex document layouts opens new horizons for efficient dataextraction and analysis, which is essential in today’s digital age. Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Check out the Paper.
Experiment tracking in machine learning is the practice of preserving all pertinent data for each experiment you conduct. Experiment tracking is implemented by ML teams in a variety of ways, including using spreadsheets, GitHub, or in-house platforms. Major ML and DL libraries like TensorFlow, Keras, or Scikit-learn are also supported.
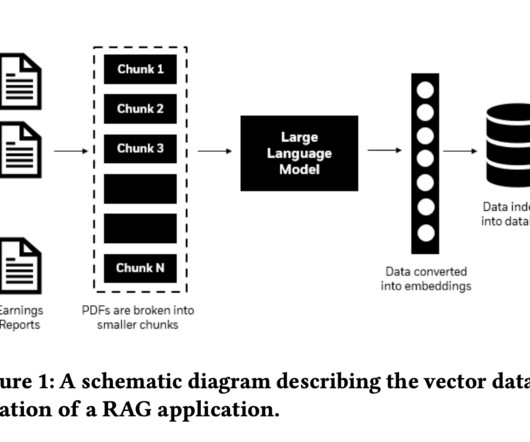
The program works well with long-form English text, but it does not work as well with tabular data, such as that found in Excel or CSV files or images that include presentations or diagrams. After building the knowledge graph, users can query their data using several Retrieval-Augmented Generation (RAG) techniques.
By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs. Note we have two folders.
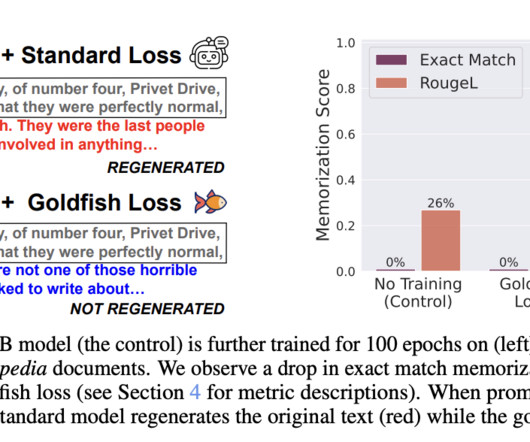
While goldfish-trained models may require slightly longer training times, they are resistant to verbatim reproduction and less susceptible to dataextraction attacks. Techniques include extracting training data via prompts, which measure “extractable memorization,” where a model completes a string from a given prefix.
This should contribute to a more holistic evaluation that may help to bridge the gap to real-world ML use cases. Large models have been shown to have learned a surprising amount of world knowledge from their pre-training data, which allows them to reproduce facts ( Jiang et al., 2020 ), Turing-NLG , BST ( Roller et al.,
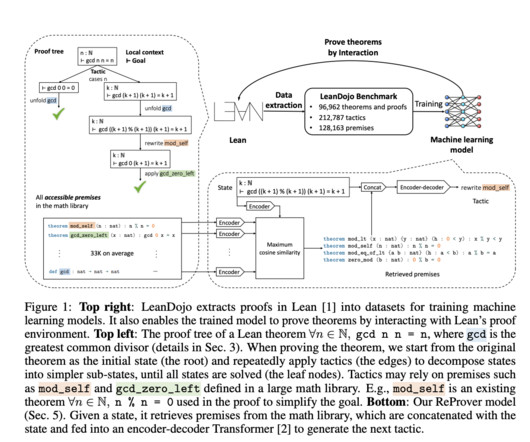
It offers resources for working with Lean and extractingdata. In dataextraction, training data is gathered from proof trees and intermediate proof states that are not immediately evident in the original Lean code. LeanDojo has been built around the Lean proof assistant, which is popular among mathematicians.
These components interact with headless browsers powered by Puppeteer to perform tasks such as dataextraction, form completion, and navigation. Dont Forget to join our 60k+ ML SubReddit. All credit for this research goes to the researchers of this project. If you like our work, you will love our newsletter.
Dataextraction tools are crucial for ATP, capturing intermediate states invisible in code but visible during runtime. Tools exist for various proof assistants, but Lean 4 tools face challenges in massive extraction across multiple projects due to single-project design limitations. Many learning-based systems (e.g.,
Because traditional tools use a single chunk size for information retrieval, they frequently have trouble with different levels of data complexity. Most retrieval techniques concentrate on either precise data retrieval or semantic understanding. If you like our work, you will love our newsletter.
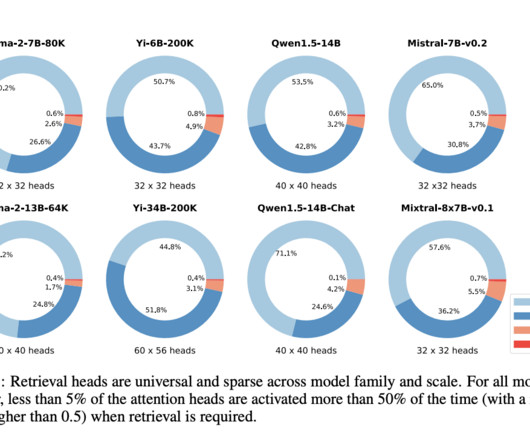
This discovery deepens our understanding of attention mechanisms in large-scale text processing and suggests practical enhancements for developing more efficient and accurate language models, potentially benefiting a wide range of applications that rely on detailed and precise dataextraction. Check out the Paper and Github Page.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
It is crucial to pursue a metrics-driven strategy that emphasizes the quality of dataextraction at the field level, particularly for high-impact fields. Harness a flywheel approach, wherein continuous data feedback is utilized to routinely orchestrate and evaluate enhancements to your models and processes.
Artificial intelligence and machine learning (AI/ML) technologies can assist capital market organizations overcome these challenges. Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents. He is a GenAI ambassador and a member of AWS AI/ML technical field community.
The ability to extract relevant insights from unstructured text, such as earnings call transcripts and financial reports, is essential for making informed decisions that can impact market predictions and investment strategies. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
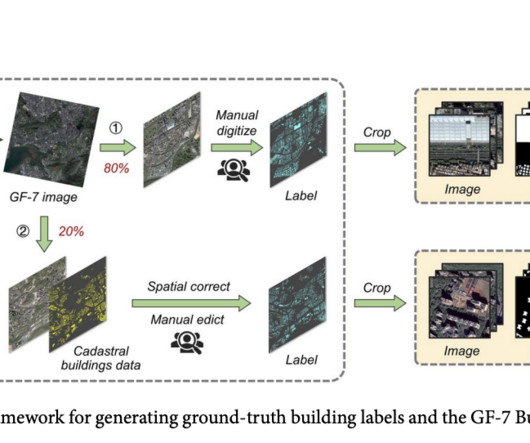
In urban development and environmental studies, accurate and efficient building dataextraction from satellite imagery is a cornerstone for myriad applications. Join our 37k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. Check out the Paper.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content