This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly.
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
The postprocessing component uses bounding box metadata from Amazon Textract for intelligent dataextraction. The postprocessing component is capable of extractingdata from complex, multi-format, multi-page PDF files with varying headers, footers, footnotes, and multi-column data.
Apart from describing the contents of the dataset, during this presentation we will go through the process of its creation, which involved tasks such as dataextraction and preprocessing using different resources (Biopython, Spark NLP for Healthcare, and OpenCV, among others).
It combines text, table, and image (including chart) data into a unified vector representation, enabling cross-modal understanding and retrieval. These embeddings represent textual and visual data in a numerical format, which is essential for various natural language processing (NLP) tasks.
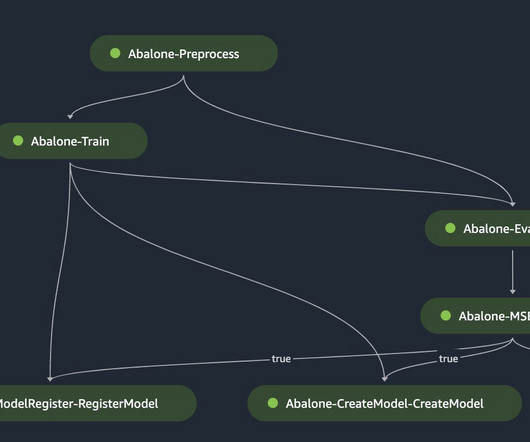
We use a typical pipeline flow, which includes steps such as dataextraction, training, evaluation, model registration and deployment, as a reference to demonstrate the advantages of Selective Execution. SageMaker Pipelines allows you to define runtime parameters for your pipeline run using pipeline parameters.
Thus, businesses struggle to manage a specialized workforce for generating labeled data to feed the models. Top Text Annotation Tools for NLP Each annotation tool has a specific purpose and functionality. NLP Lab is a Free End-to-End No-Code AI platform for document labeling and AI/ML model training.
Whether you’re looking to classify documents, extract keywords, detect and redact personally identifiable information (PIIs), or parse semantic relationships, you can start ideating your use case and use LLMs for your natural language processing (NLP). In this example, you explicitly set the instance type to ml.g5.48xlarge.
Extracting layout elements for search indexing and cataloging purposes. The contents of the LAYOUT_TITLE or LAYOUT_SECTION_HEADER , along with the reading order, can be used to appropriately tag or enrich metadata. This improves the context of a document in a document repository to improve search capabilities or organize documents.
By taking advantage of advanced natural language processing (NLP) capabilities and data analysis techniques, you can streamline common tasks like these in the financial industry: Automating dataextraction – The manual dataextraction process to analyze financial statements can be time-consuming and prone to human errors.
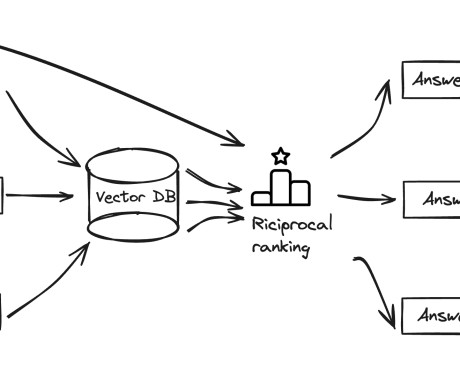
Amazon Kendra: Amazon Kendra provides semantic search capabilities for ranking of documents and passages, it also deals with the overhead of handling text extraction, embeddings, and managing vector datastore. Amazon DynamoDB : Used for storing metadata and other necessary information for quick retrieval during search operations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content