This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
Over the past year I have on several occasions encouraged NLP researchers to do systematic reviews of the research literature. I In AI and NLP, most literature surveys are like “previous work” sections in papers. The Dataextracted : what information we extract from the paper. For
Akeneo is the product experience (PX) company and global leader in Product Information Management (PIM). How is AI transforming product information management (PIM) beyond just centralizing data? Akeneo is described as the “worlds first intelligent product cloud”what sets it apart from traditional PIM solutions?
Medical dataextraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP.
Large language models (LLMs) have unlocked new possibilities for extractinginformation from unstructured text data. This post walks through examples of building informationextraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
By integrating this method with Azure OpenAI’s robust capabilities, Microsoft offers a highly versatile solution to improve model output and resource utilization across various NLP tasks. Providing all examples related to these tasks in a single prompt can lead to information overload and reduced accuracy. Check out the Details.
To address this issue, Evernorth has developed an innovative clinical support tool designed to facilitate rapid and efficient access to necessary information, irrespective of data structure or format. The post Using Generative AI for DataExtraction Clinical Support appeared first on John Snow Labs.
Introduction In the world of data analysis, extracting useful information from tabular data can be a difficult task. Conventional approaches typically require manual exploration and analysis of data, which can be requires a significant amount of effort, time, or workforce to complete.
AI has witnessed rapid advancements in NLP in recent years, yet many existing models still struggle to balance intuitive responses with deep, structured reasoning. The core feature of DeepHermes 3 is its ability to switch between intuitive and deep reasoning, allowing users to customize how the model processes and delivers information.
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. This growing prevalence underscores the need for advanced tools to analyze and interpret the vast amounts of clinical data generated in oncology.
The quest for clean, usable data for pretraining Large Language Models (LLMs) resembles searching for treasure amidst chaos. While rich with information, the digital realm is cluttered with extraneous content that complicates the extraction of valuable data.
Summary: Deep Learning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction Deep Learning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data.
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
To extract key information from high volumes of documents from emails and various sources, companies need comprehensive automation capable of ingesting emails, file uploads, and system integrations for seamless processing and analysis. Finding relevant information that is necessary for business decisions is difficult.
DataExtraction & Analysis : Summarizing large reports or extracting key insights from datasets using GPT-4’s advanced reasoning abilities. Cohere Cohere specializes in natural language processing (NLP) and provides scalable solutions for enterprises, enabling secure and private data handling.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learning models, and data mining techniques to derive pertinent qualitative information from unstructured text data.
In this article, we will explore the significance of table extraction and demonstrate the application of John Snow Labs’ NLP library with visual features installed for this purpose. We will delve into the key components within the John Snow Labs NLP pipeline that facilitate table extraction. cache() Confused?
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.
These development platforms support collaboration between data science and engineering teams, which decreases costs by reducing redundant efforts and automating routine tasks, such as data duplication or extraction. AutoAI automates data preparation, model development, feature engineering and hyperparameter optimization.
Medical records, rich with sensitive information, are invaluable for research and innovation but must be carefully managed to ensure compliance with regulations like HIPAA and GDPR. De-identification, the process of removing or obscuring personally identifiable information (PII) from medical data, lies at the heart of this effort.
Many techniques were created to process this unstructured data, such as sentiment analysis, keyword extraction, named entity recognition, parsing, etc. The evolution of Large Language Models (LLMs) allowed for the next level of understanding and informationextraction that classical NLP algorithms struggle with.
It requires an understanding of how AI models process information and a creative touch to tailor prompts that align with the desired outcome. The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. This 10-hour course, also highly rated at 4.8,
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). This opens up applications where data is very expensive to collect and enables adapting models swiftly to new domains.
Naive RAG models face limitations such as missing content, reasoning mismatch, and challenges in handling multimodal data. Although they can retrieve relevant information, they may struggle to generate complete and coherent responses when required information is absent, leading to incomplete or inaccurate outputs.
Learn NLPdata processing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk Many data we analyze as data scientists consist of a corpus of human-readable text.
One of the key features of the o1 models is their ability to work efficiently across different domains, including natural language processing (NLP), dataextraction, summarization, and even code generation. o1 models also excel in tasks requiring detailed comprehension and informationextraction from complex texts.
Clone Researchers have developed various benchmarks to evaluate natural language processing (NLP) tasks involving structured data, such as Table Natural Language Inference (NLI) and Tabular Question Answering (QA). The benchmark is built using dataextracted from strategy video games that mimic real-world business situations.
From uncovering hidden patterns to providing actionable recommendations, generative AI’s proficiency in data analytics heralds a new era where innovation spans the spectrum from artistic expression to informed business strategies. So let’s take a brief look at some examples of how generative AI can be used for data analytics.
HiveMind HiveMind is a tool that automates tasks like content writing, dataextraction, and translation. Anyword Anyword is an AI writing assistant that makes it easy for users to include specific details, SEO keywords, and other important information. Narrato Narrato is a platform used for content creation and copywriting.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. The following screenshot shows the updated information on the Private tab.
Significance for Cancer Diagnosis Biomarkers (short for biological marker ) are measurable biological indicators that provide crucial information about health status, disease processes, or treatment responses. Personalized Screening: Biomarker information helps guide the selection of targeted therapies and personalized treatment plans.
Natural Language Processing has emerged as a powerful tool in oncology research as it extracts and analyzes information from unstructured clinical text like pathology reports, electronic health records ( EHRs ), radiology reports, and clinical notes. In this article, we will discuss the significance and applications of NLP in Oncology.
Natural language processing (NLP) is a core part of artificial intelligence. But how can you find the best books on NLP? 10 Must-read Books on NLP One quick note before we jump into the list. Some of these books cover more basic NLP elements. Booth The first book in our list focuses on machine learning-based NLP.
By leveraging AI, organizations can automate the extraction and interpretation of information from documents to focus more on their core activities. Businesses can’t afford to wait days for document processing; they need information at their fingertips. First and foremost, the digital era demands speed and efficiency.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
An IDP pipeline usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. It is crucial to pursue a metrics-driven strategy that emphasizes the quality of dataextraction at the field level, particularly for high-impact fields.
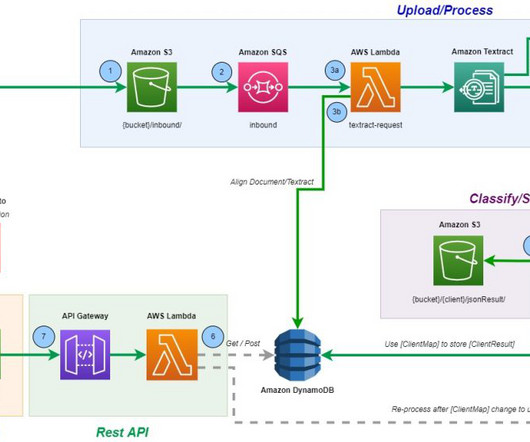
Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents. An event on message receipt invokes a Lambda function that in turn invokes the Amazon Textract StartDocumentAnalysis API for informationextraction.
Medical records, rich with sensitive information, are invaluable for research and innovation but must be carefully managed to ensure compliance with regulations like HIPAA and GDPR. Deidentification, the process of removing or obscuring personally identifiable information (PII) from medical data, lies at the heart of this effort.
HiveMind HiveMind is a tool that automates tasks like content writing, dataextraction, and translation. Anyword Anyword is an AI writing assistant that makes it easy for users to include specific details, SEO keywords, and other important information. Narrato Narrato is a platform used for content creation and copywriting.
The field of NLP, in particular, has experienced a significant transformation due to the emergence of Large Language Models (LLMs). Before delving deeper into this algorithm, let’s take a detour to explore the world of text classification via compressor algorithms, a sub-field of NLP that has been around for quite a while.
Text annotation is important as it makes sure that the machine learning model accurately perceives and draws insights based on the provided information. Thus, businesses struggle to manage a specialized workforce for generating labeled data to feed the models. Prodigy offers the support in the paid version.
Continue to read to get a handful of important information What is OCR Technology? OCR is a technology that reads text from images and turns it into machine-readable data. Use Natural Language Processing (NLP) NLP techniques can be used to make processing documents even better.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content