This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many techniques were created to process this unstructured data, such as sentiment analysis, keyword extraction, named entity recognition, parsing, etc. The evolution of Large Language Models (LLMs) allowed for the next level of understanding and informationextraction that classical NLP algorithms struggle with.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.
Large language models (LLMs) have unlocked new possibilities for extractinginformation from unstructured text data. This post walks through examples of building informationextraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
Annotating transcripts with metadata such as timestamps, speaker labels, and emotional tone gives researchers a comprehensive understanding of the context and nuances of spoken interactions. This allows healthcare organizations to comply with regulations such as HIPAA while still benefiting from the rich data collected through their research.
For more information about version updates, see Shut down and Update Studio Classic Apps. Each model card shows key information, including: Model name Provider name Task category (for example, Text Generation) Select the model card to view the model details page. Search for Meta to view the Meta model card.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
On a high level, the accounts payable process includes receiving and scanning invoices, extraction of the relevant data from scanned invoices, validation, approval, and archival. The second step (extraction) can be complex. You can visualize the indexed metadata using OpenSearch Dashboards.
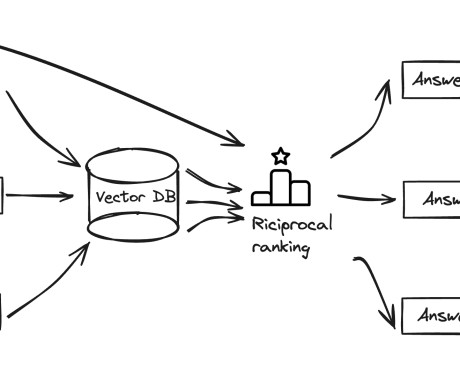
Naive RAG models face limitations such as missing content, reasoning mismatch, and challenges in handling multimodal data. Although they can retrieve relevant information, they may struggle to generate complete and coherent responses when required information is absent, leading to incomplete or inaccurate outputs. split('.')[0]}.json"
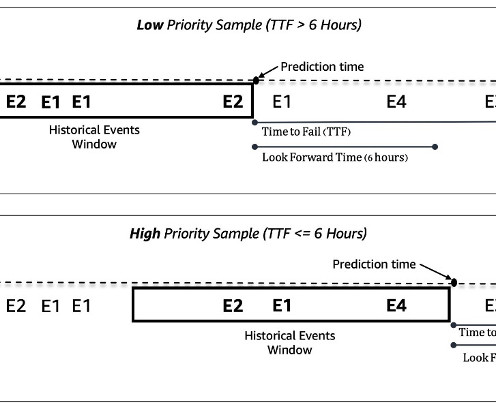
Machine ID Event Type ID Timestamp 0 E1 2022-01-01 00:17:24 0 E3 2022-01-01 00:17:29 1000 E4 2022-01-01 00:17:33 114 E234 2022-01-01 00:17:34 222 E100 2022-01-01 00:17:37 In addition to dynamic machine events, static metadata about each machine is also available. All the names in the table are anonymized to protect customer information.)
For an example of clustering based on this metric, refer to Cluster time series data for use with Amazon Forecast. In this post, we generate features from the time series dataset using the TSFresh Python library for dataextraction. Irvine, CA: University of California, School of Information and Computer Science.
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
Web crawling is the automated process of systematically browsing the internet to gather and index information from various web pages. Data Collection : The crawler collects information from each page it visits, including the page title, meta tags, headers, and other relevant data. What is Web Crawling?
Tableau’s robust visualization capabilities complement Data Blending, empowering users to create dynamic visualizations that convey complex insights with clarity. Ultimately, Data Blending in Tableau fosters a deeper understanding of data dynamics and drives informed strategic actions.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Processing of Data Once the data is stored, Hive provides a metadata layer allowing users to define the schema and create tables.
Building document processing and understanding solutions for financial and research reports, medical transcriptions, contracts, media articles, and so on requires extraction of information present in titles, headers, paragraphs, and so on. List – Any information grouped together in list form. Returned as LAYOUT_TITLE block type.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. It is part of IBM’s Infosphere Information Server ecosystem.
It comprises several essential elements: Data Files: These files store the actual data used by applications. Data Dictionary: This repository contains metadata about database objects, such as tables and columns. Indices: Indices are used to speed up data retrieval processes by providing quick access paths to information.
Personal Assistants : LangChain is ideal for building personal assistants that can take actions, remember interactions, and have access to your data, providing personalized assistance. Extraction : LangChain helps extract structured information from unstructured text, streamlining data analysis and interpretation.
For example, an LLM trained on predominantly European data might overrepresent those perspectives, unintentionally narrowing the scope of information or viewpoints it offers. For example, a recruitment LLM favoring male applicants due to biased training data reflects a harmful bias that requires correction.
Text annotation is important as it makes sure that the machine learning model accurately perceives and draws insights based on the provided information. Projects & Teams The stakeholders collaborate effectively while working on large-scale dataextraction/validation projects.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
The solution is designed to provide customers with a detailed, personalized explanation of their preferred features, empowering them to make informed decisions. Requested information is intelligently fetched from multiple sources such as company product metadata, sales transactions, OEM reports, and more to generate meaningful responses.
By taking advantage of advanced natural language processing (NLP) capabilities and data analysis techniques, you can streamline common tasks like these in the financial industry: Automating dataextraction – The manual dataextraction process to analyze financial statements can be time-consuming and prone to human errors.
Gladia's platform also enables real-time extraction of insights and metadata from calls and meetings, supporting key enterprise use cases such as sales assistance and automated customer support. The model will create coherent responses by filling in gaps with information that sounds plausible but is incorrect.
What Are the Key Components of Data Warehouse Architecture? Data warehouse architecture typically consists of several key components: Data Sources: Various systems from which dataextracted. ETL Process: Extract, Transform, Load processes that prepare data for analysis. What Are Non-additive Facts?
The agent then interprets the users request and determines if actions need to be invoked or information needs to be retrieved from a knowledge base. Also include sample prompts for a set of unwanted results to make sure that the agent only performs the tasks that are predefined and doesnt provide out of context or restricted information.
Today, we’re excited to share the journey of the VW —an innovator in the automotive industry and Europe’s largest car maker—to enhance knowledge management by using generative AI , Amazon Bedrock , and Amazon Kendra to devise a solution based on Retrieval Augmented Generation (RAG) that makes internal information more easily accessible by its users.
Required for tasks such as market research, data analysis, content aggregation, and competitive intelligence. This efficient method saves time, improves decision making, and allows businesses to study trends and patterns, making it a powerful tool for extracting valuable information from the Internet. <img>: Images. <ul>,
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content