This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The IDP Well-Architected Custom Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build a secure, efficient, and reliable IDP solution on AWS. This post focuses on the Reliability pillar of the IDP solution.
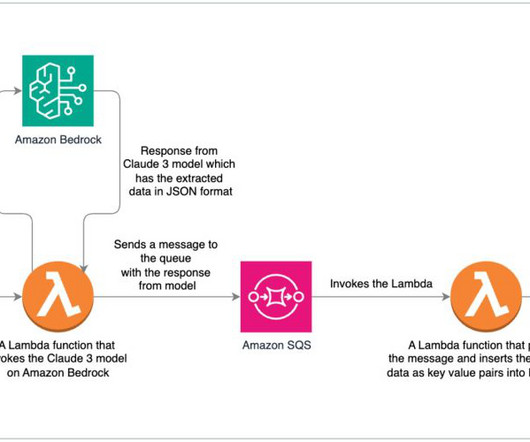
With Intelligent Document Processing (IDP) leveraging artificial intelligence (AI), the task of extractingdata from large amounts of documents with differing types and structures becomes efficient and accurate. The following diagram is how we visualize these IDP phases.
The postprocessing component uses bounding box metadata from Amazon Textract for intelligent dataextraction. The postprocessing component is capable of extractingdata from complex, multi-format, multi-page PDF files with varying headers, footers, footnotes, and multi-column data.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. We specifically used the Rhubarb Python framework to extract JSON schema -based data from the documents.
Enterprise customers can unlock significant value by harnessing the power of intelligent document processing (IDP) augmented with generative AI. By infusing IDP solutions with generative AI capabilities, organizations can revolutionize their document processing workflows, achieving exceptional levels of automation and reliability.
Developers face significant challenges when using foundation models (FMs) to extractdata from unstructured assets. This dataextraction process requires carefully identifying models that meet the developers specific accuracy, cost, and feature requirements.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content