This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. This solution incorporates customizable rules, allowing you to define the criteria for invoking a human review.
Current methods for extractingdata from unstructured sources, including regular expressions and rule-based systems, are often limited by their inability to maintain the semantic integrity of the original documents, especially when handling scientific literature. Check out the GitHub.
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
With a remarkable 500,000-token context window —more than 15 times larger than most competitors—Claude Enterprise is now capable of processing extensive datasets in one go, making it ideal for complex document analysis and technical workflows. Flash $0.00001875 / 1K characters $0.000075 / 1K characters $0.0000375 / 1K characters Gemini 1.5
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
Many companies across all industries still rely on laborious, error-prone, manual procedures to handle documents, especially those that are sent to them by email. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Layout is a new feature that allows customers to automatically extract layout elements such as paragraphs, titles, subtitles, headers, footers, and more from documents.
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. This growing prevalence underscores the need for advanced tools to analyze and interpret the vast amounts of clinical data generated in oncology.
Document processing is an essential yet time-consuming activity in many businesses. Every day, countless hours are spent on sorting, filing, and searching for documents. By leveraging AI, organizations can automate the extraction and interpretation of information from documents to focus more on their core activities.
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. These are two common methods for text representation: Bag-of-words (BoW): BoW represents text as a collection of unique words in a text document. What is text mining? positive, negative or neutral).
You can handle documents differently with these tools. Your team will spend less time on boring tasks like entering data and more time on important work. So, do you want to improve how you manage documents? These tools provide users with a better interface to easily convert jpeg to word documents. How Does OCR Work?
In this presentation, we delve into the effective utilization of Natural Language Processing (NLP) agents in the context of Acciona. We explore a range of practical use cases where NLP has been deployed to enhance various processes and interactions.
The latest version of Finance NLP , 1.15, introduces numerous additional features to the existing collection of 926+ models and 125+ Language Models from previous releases of the library. Normalizing date mentions in text This notebook shows how to use Finance NLP to standardize date mentions in the texts to a unique format.
Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. The solution integrates data in three tiers.
In this article, we will explore the significance of table extraction and demonstrate the application of John Snow Labs’ NLP library with visual features installed for this purpose. We will delve into the key components within the John Snow Labs NLP pipeline that facilitate table extraction. cache() Confused?
The NLP Lab, a No-Code prominent tool in this field, has been at the forefront of such evolution, constantly introducing cutting-edge features to simplify and improve document analysis tasks. The recently published enhancements of this feature have significantly boosted its utility when dealing with large documents.
This blog explores the performance and comparison of de-identification services provided by Healthcare NLP, Amazon, and Azure, focusing on their accuracy when applied to a dataset annotated by healthcare experts. Dataset For this benchmark, we utilized 48 open-source documents annotated by domain experts from John Snow Labs.
Let’s explore how to effectively prompt OpenAI’s o1 models and highlight the differences between o1 and GPT-4, drawing on insights from OpenAI’s documentation and usage guidelines. For instance, if you’re generating content for a formal document, mentioning that in the prompt will help the o1 model adjust its language accordingly.
Solution architecture The mmRAG solution is based on a straightforward concept: to extract different data types separately, you generate text summarization using a VLM from different data types, embed text summaries along with raw data accordingly to a vector database, and store raw unstructured data in a document store.
This is because trades involve different counterparties and there is a high degree of variation among documents containing commercial terms (such as trade date, value date, and counterparties). Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents.
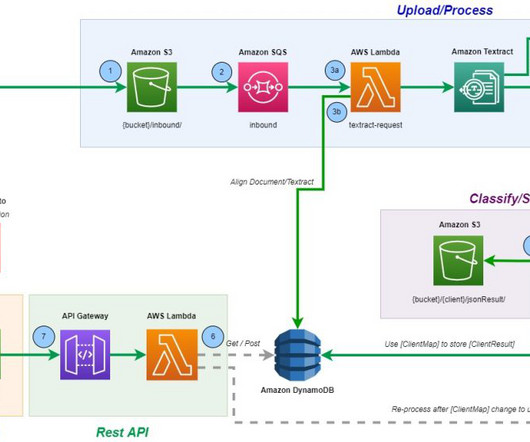
The IDP Well-Architected Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build secure, efficient, and reliable IDP solutions on AWS. This post focuses on the Operational Excellence pillar of the IDP solution.
These development platforms support collaboration between data science and engineering teams, which decreases costs by reducing redundant efforts and automating routine tasks, such as data duplication or extraction. forums, documentation, customer support) can also be invaluable for troubleshooting issues and sharing knowledge.
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and dataextraction, among other skills. This 10-hour course, also highly rated at 4.8,
Even though evaluations are guided by the UNDP Evaluation Guideline, there is no standard written format for these evaluations, and the aforementioned sections may occur at different locations in the document, or not all of them may exist. Amazon Textract is used to extractdata from PDF documents.
HiveMind HiveMind is a tool that automates tasks like content writing, dataextraction, and translation. Lavender Lavender is a browser extension that merges AI writing, social data, and inbox productivity tools. NexMind NexMind swiftly produces optimized long and short-form content with NLP and semantic suggestions.
The IDP Well-Architected Custom Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build a secure, efficient, and reliable IDP solution on AWS. In this case, you must convert unsupported document formats to PDF or image format.
Research And Discovery: Analyzing biomarker dataextracted from large volumes of clinical notes can uncover new correlations and insights, potentially leading to the identification of novel biomarkers or combinations with diagnostic or prognostic value.
Text annotation assigns labels to a text document or various elements of its content. Thus, businesses struggle to manage a specialized workforce for generating labeled data to feed the models. Top Text Annotation Tools for NLP Each annotation tool has a specific purpose and functionality.
HiveMind HiveMind is a tool that automates tasks like content writing, dataextraction, and translation. Lavender Lavender is a browser extension that merges AI writing, social data, and inbox productivity tools. NexMind NexMind swiftly produces optimized long and short-form content with NLP and semantic suggestions.
This blog explores the performance and comparison of de-identification services provided by Healthcare NLP, Amazon, Azure, and OpenAI focusing on their accuracy when applied to a dataset annotated by healthcare experts. Dataset For this benchmark, we utilized 48 open-source documents annotated by domain experts from John Snow Labs.
For instance, NLP in oncology can help identify patients with a high risk of cancer, and predict treatment outcomes. In this article, we will discuss the significance and applications of NLP in Oncology. The process involves four steps: dataextraction, eligibility criteria matching, trial identification, and patient outreach.
Tasks such as routing support tickets, recognizing customers intents from a chatbot conversation session, extracting key entities from contracts, invoices, and other type of documents, as well as analyzing customer feedback are examples of long-standing needs. In this example, you explicitly set the instance type to ml.g5.48xlarge.
Natural language processing (NLP) is a core part of artificial intelligence. But how can you find the best books on NLP? 10 Must-read Books on NLP One quick note before we jump into the list. Some of these books cover more basic NLP elements. Booth The first book in our list focuses on machine learning-based NLP.
The field of NLP, in particular, has experienced a significant transformation due to the emergence of Large Language Models (LLMs). An interesting approach One algorithm of note focuses on topic classification by employing data compression algorithms. Photo by nadi borodina on Unsplash We live in interesting times.
R’s machine learning capabilities allow for model training, evaluation, and deployment. · Text Mining and Natural Language Processing (NLP): R offers packages such as tm, quanteda, and text2vec that facilitate text mining and NLP tasks.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
Once validated, the deployment tools facilitate the integration of these models into real-world applications, be it in automating customer support interactions, analyzing financial documents, or interpreting medical texts. DOLMA The DOLMA dataset is a collection of documents and their corresponding logical forms.
Phi-3’s advanced capabilities are particularly beneficial for tasks such as document summarization, market research analysis, content generation, and leveraging the RAG (Retrieval Augmented Generation) framework for question answering. This function will take the user’s question as input.
ICL is a new approach in NLP with similar objectives to few-shot learning that lets models understand context without extensive tuning. Step 2 Apart from Prompt → FM → Adapt → Completion pattern, we often need a Chain of Tasks that involves dataextraction, predictive AI, and generative AI foundational models.
In addition, the emergence of smartphones and electronic documents also lead to further advancements in OCR technology. In short, optical character recognition software helps convert images or physical documents into a searchable form. Since then, OCR technology has experienced multiple developmental phases.
Data Analysis Once data is collected, AI assistants employ Machine Learning techniques to analyse it. Natural Language Processing (NLP) Many AI Research Assistants use NLP to understand and interpret human language.
What are the key advantages that it offers for financial NLP tasks? Gideon Mann: To your point about data-centric AI and the commoditization of LLMs, when I look at what’s come out of open-source and academia, and the people working on LLMs, there has been amazing progress in making these models easier to use and train.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content