This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, before data can be analyzed and converted into actionable insights, it must first be effectively sourced and extracted from a myriad of platforms, applications, and systems. This is where dataextraction tools come into play. What is DataExtraction? Why is DataExtraction Crucial for Businesses?
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Healthcare documentation is an integral part of the sector that ensures the delivery of high-quality care and maintains the continuity of patient information. However, as healthcare providers have to deal with excessive amounts of data, managing it can feel overwhelming.
In the fast-paced digital era, businesses are constantly seeking innovative solutions to streamline their document management processes. These tools harness the power of machine learning, natural language processing, and intelligent automation to simplify the creation, storage, and retrieval of critical business documents.
Traditional methods for handling such data are either too slow, require extensive manual work, or are not flexible enough to adapt to the wide variety of document types and layouts that businesses encounter. Sparrow supports local dataextraction pipelines through advanced machine learning models like Ollama and Apple MLX.
Extracting information quickly and efficiently from websites and digital documents is crucial for businesses, researchers, and developers. They require specific data from various online sources to analyze trends, monitor competitors, or gather insights for strategic decisions.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
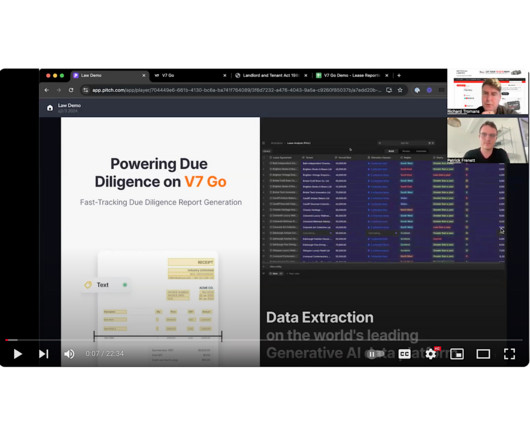
This week’s Product Walk Through is with V7 Labs and its genAI-driven Go capability for extracting key data from legal documents. V7 Labs is an AI development group and Go is its tool specifically …
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. This solution incorporates customizable rules, allowing you to define the criteria for invoking a human review.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. MICR line format).
We aim to streamline the meticulous task of detecting and documenting modifications in web-based content by utilizing Python. Introduction The purpose of this project is to develop a Python program that automates the process of monitoring and tracking changes across multiple websites.
Extracting structured data from PDFs and images can be challenging, but combining Optical Character Recognition (OCR) with Language Models (LLMs) offers a powerful solution. Within the Azure ecosystem, Azure Document Intelligence is the way to go when analyzing documents. Essentially a pure traditional OCR.
Flash excels at summarisation, chat applications, image and video captioning, dataextraction from long documents and tables, and more,” explained Demis Hassabis, CEO of Google DeepMind. While lighter-weight than the 1.5 This is because it’s been trained by 1.5
Optical Character Recognition (OCR) has revolutionized the way that businesses automate document processing. The more complex the document being processed, the less accurate it becomes. Although out of the box OCR technologies may not be suited for this task, there are other ways to achieve your document processing goals with OCR.
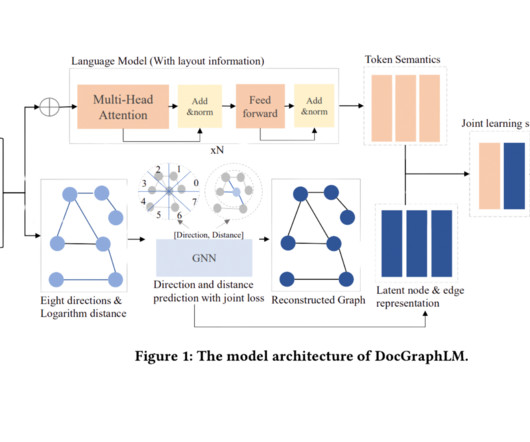
There is a growing need to develop methods capable of efficiently processing and interpreting data from various document formats. This challenge is particularly pronounced in handling visually rich documents (VrDs), such as business forms, receipts, and invoices. Check out the Paper.
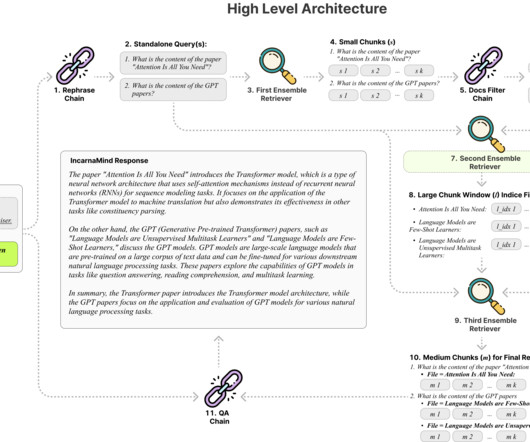
The necessity of being able to query documents in natural language has increased with the introduction of AI-driven solutions. Using a unique architecture intended to improve user-document interaction, IncarnaMind has tackled these problems.
It is common practice for businesses to employ conventional methods when developing an extraction pipeline for each unique document layout. Also, while off-the-shelf LLMs have great reasoning capabilities, they have problems with hallucinations and inaccurate extraction; thus, they need to be more dependable for industrial use cases.
Imagine you're processing 100 invoices a day and need to compile all the details into an Excel sheet by the end of the day; Extractors.ai makes this task fast and effortless, CEO Aravind Jayendran said.
In this post, we focus on one such complex workflow: document processing. This serves as an example of how generative AI can streamline operations that involve diverse data types and formats. We demonstrate how generative AI along with external tool use offers a more flexible and adaptable solution to this challenge.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Layout is a new feature that allows customers to automatically extract layout elements such as paragraphs, titles, subtitles, headers, footers, and more from documents.
Current methods for extractingdata from unstructured sources, including regular expressions and rule-based systems, are often limited by their inability to maintain the semantic integrity of the original documents, especially when handling scientific literature.
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
Professionals conducting research can use Paperguide to consolidate industry reports, extract key data points, and create well-structured professional documents with AI writing assistance. With support for document uploads in 50+ languages , you can easily explore global research like never before. No problem.
With a remarkable 500,000-token context window —more than 15 times larger than most competitors—Claude Enterprise is now capable of processing extensive datasets in one go, making it ideal for complex document analysis and technical workflows. Flash $0.00001875 / 1K characters $0.000075 / 1K characters $0.0000375 / 1K characters Gemini 1.5
Parsio (OCR + AI chat) Enhance your dataextraction process by adopting an AI-driven document parser. Enhance your dataextraction routines with our state-of-the-art AI-based PDF parser. Bid farewell to labor-intensive data entry, and embrace seamless, automatic dataextraction with this advanced technology.
Enter generative AI, a groundbreaking technology that transforms how we approach dataextraction. Summarization : Condense large documents into concise summaries, making it easier to digest extensive reports or articles quickly. What is Generative AI? This is useful for organizing information and enhancing search capabilities.
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. read()) answer = response_body.get("content")[0].get("text")
Many companies across all industries still rely on laborious, error-prone, manual procedures to handle documents, especially those that are sent to them by email. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
Document processing is an essential yet time-consuming activity in many businesses. Every day, countless hours are spent on sorting, filing, and searching for documents. By leveraging AI, organizations can automate the extraction and interpretation of information from documents to focus more on their core activities.
Automating the dataextraction process, especially from tables and figures, can allow researchers to focus on data analysis and interpretation rather than manual dataextraction. With quicker access to relevant data, researchers can accelerate the pace of their work and contribute to advancements in their fields.
This approach is among the most efficient and effective methods for dataextraction from websites. Web scraping involves creating custom scripts that interact directly with the Document Object Model (DOM) structure of web pages. This method can sometimes be complex and requires a solid understanding of HTML, CSS, and JavaScript.
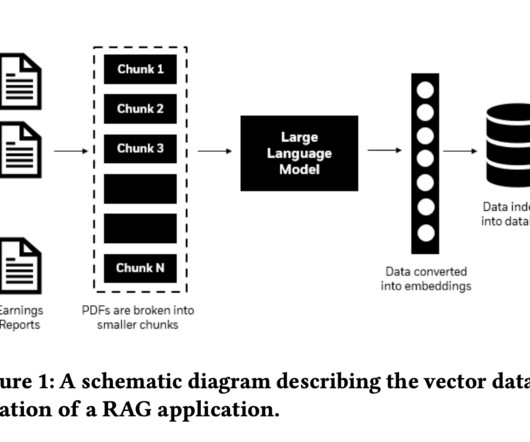
The ability to extract relevant insights from unstructured text, such as earnings call transcripts and financial reports, is essential for making informed decisions that can impact market predictions and investment strategies. Researchers from BlackRock, Inc., and NVIDIA introduced a novel approach known as HybridRAG.
The multimodal PDF dataextraction blueprint uses NVIDIA NeMo Retriever NIM microservices to extract insights from enterprise documents, helping developers build powerful AI agents and chatbots. The digital human blueprint supports the creation of interactive, AI-powered avatars for customer service.
You can handle documents differently with these tools. Your team will spend less time on boring tasks like entering data and more time on important work. So, do you want to improve how you manage documents? These tools provide users with a better interface to easily convert jpeg to word documents. How Does OCR Work?
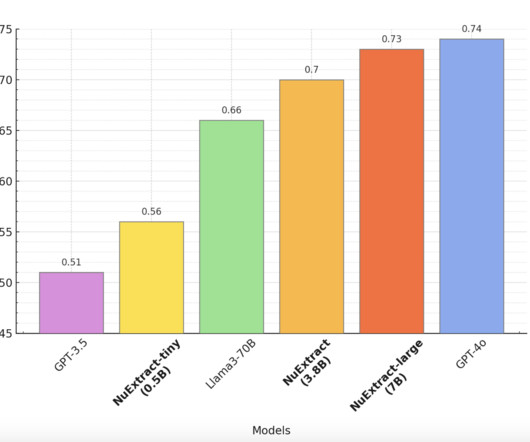
NuMind introduces NuExtract , a cutting-edge text-to-JSON language model that represents a significant advancement in structured dataextraction from text. This model aims to transform unstructured text into structured data highly efficiently. Structured extraction tasks vary significantly in complexity.
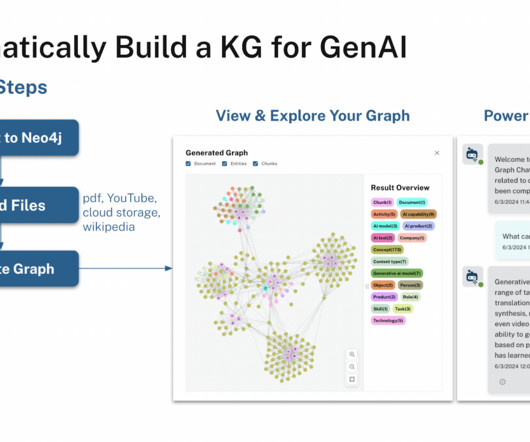
The program works well with long-form English text, but it does not work as well with tabular data, such as that found in Excel or CSV files or images that include presentations or diagrams. After building the knowledge graph, users can query their data using several Retrieval-Augmented Generation (RAG) techniques.
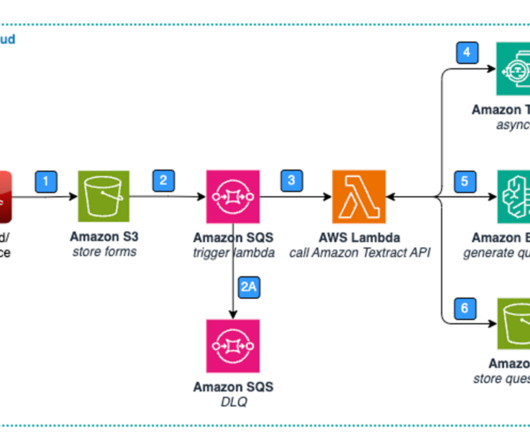
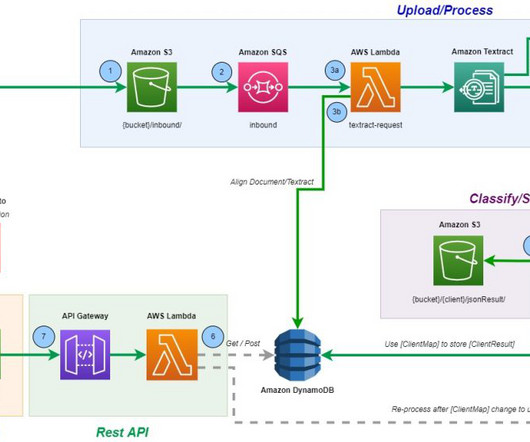
In this post, we show how to automate the accounts payable process using Amazon Textract for dataextraction. We also provide a reference architecture to build an invoice automation pipeline that enables extraction, verification, archival, and intelligent search. Now let’s dive into each of the document processing steps.
Healthcare Data Abstraction: The Three Barriers To begin with, each project has its own sets of rules for what, how, and when data should be extracted and normalized. Second, the information is frequently derived from natural language documents or a combination of structured, imaging, and document sources.
By taking advantage of advanced natural language processing (NLP) capabilities and data analysis techniques, you can streamline common tasks like these in the financial industry: Automating dataextraction – The manual dataextraction process to analyze financial statements can be time-consuming and prone to human errors.
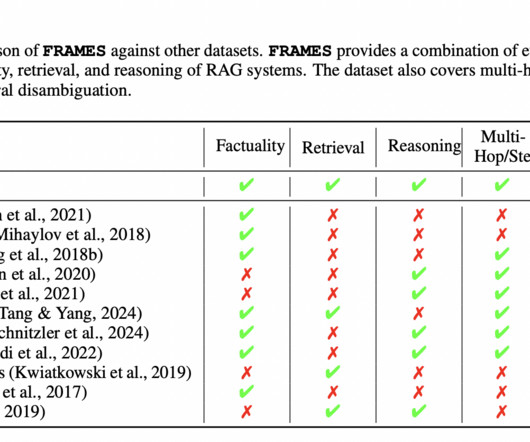
Unlike traditional models that rely solely on pre-existing knowledge, RAG systems can incorporate real-time data, making them valuable for tasks requiring up-to-date information and multi-hop reasoning. with two additional documents and 0.47 when models iteratively retrieved and synthesized relevant information.
The IDP Well-Architected Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build secure, efficient, and reliable IDP solutions on AWS. This post focuses on the Operational Excellence pillar of the IDP solution.
This is because trades involve different counterparties and there is a high degree of variation among documents containing commercial terms (such as trade date, value date, and counterparties). Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents.
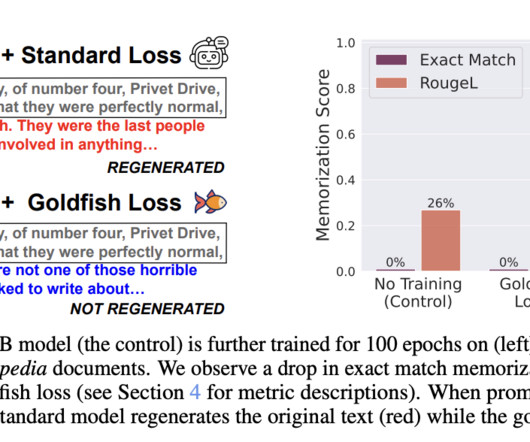
While goldfish-trained models may require slightly longer training times, they are resistant to verbatim reproduction and less susceptible to dataextraction attacks. Techniques include extracting training data via prompts, which measure “extractable memorization,” where a model completes a string from a given prefix.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content