This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
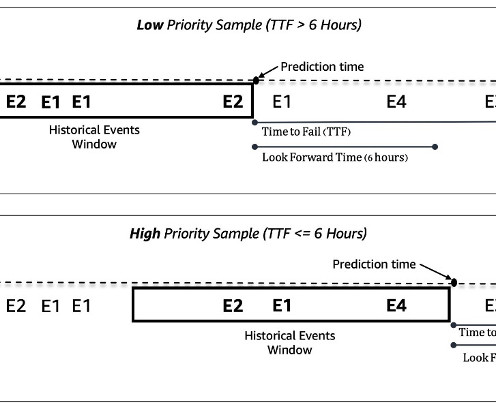
Machine ID Event Type ID Timestamp 0 E1 2022-01-01 00:17:24 0 E3 2022-01-01 00:17:29 1000 E4 2022-01-01 00:17:33 114 E234 2022-01-01 00:17:34 222 E100 2022-01-01 00:17:37 In addition to dynamic machine events, static metadata about each machine is also available. Careful optimization is needed in the dataextraction and preprocessing stage.
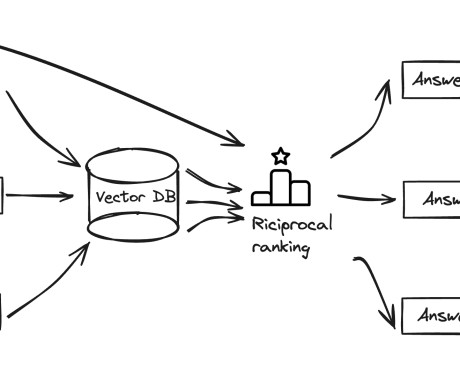
It combines text, table, and image (including chart) data into a unified vector representation, enabling cross-modal understanding and retrieval. For tables, the system retrieves relevant table locations and metadata, and computes the cosine similarity between the multimodal embedding and the vectors representing the table and its summary.
By following these detailed steps, you can effectively leverage Data Blending in Tableau to integrate, analyze, and visualize diverse datasets, empowering informed decision-making and driving business success. While powerful, Data Blending in Tableau has limitations. What is the purpose of using metadata in tableau?
In machine learning, experiment tracking stores all experiment metadata in a single location (database or a repository). Model hyperparameters, performance measurements, run logs, model artifacts, data artifacts, etc., Neptune AI ML model-building metadata may be managed and recorded using the Neptune platform.
The MLflow Tracking component has an API and UI that enable different logging metadata (such as parameters, code versions, metrics, and output files) and afterward viewing the outcomes. You can utilize Polyaxon UI or incorporate it with another board, such as TensorBoard, to display the logged metadata later.
This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 DataScience tools for 2024. ETL stands for Extract, Transform, Load. What is ETL?
The simplest way to run this example is by using Amazon SageMaker Studio with the DataScience 3.0 Sensitive dataextraction and redaction LLMs show promise for extracting sensitive information for redaction. You can effectively use LLMs for entity extraction tasks through careful prompt engineering.
Disk Storage Disk Storage refers to the physical storage of data within a DBMS. It comprises several essential elements: Data Files: These files store the actual data used by applications. Data Dictionary: This repository contains metadata about database objects, such as tables and columns.
Understanding Data Warehouse Functionality A data warehouse acts as a central repository for historical dataextracted from various operational systems within an organization. DataExtraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
Using the PACE-Way (an Amazon-based development approach), the team developed a time-boxed prototype over a maximum of 6 weeks, which included a full stack solution with frontend and UX, backed by specialist expertise, such as datascience, tailored for VW’s needs.
The header contains metadata such as the page title and links to external resources. """ # Run the extraction chain with the provided schema and content start_time = time.time() extracted_content = create_extraction_chain(schema=schema, llm=llm).run(content) HTML Elements ( Wikipedia ) 1. lister-item-header a::text').get(),
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content