This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Introduction I have been associated with Analytics Vidya from the 3rd edition of Blogathon. The post Guide For Data Analysis: From DataExtraction to Dashboard appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction: DataExtraction is the process of extractingdata from various. The post DataExtraction from Unstructured PDFs appeared first on Analytics Vidhya.
Instead, leveraging CV dataextraction to focus on how well key job requirements align with a candidate’s CV can lead to a successful match for both the employer […] The post CV DataExtraction: Essential Tools and Methods for Recruitment appeared first on Analytics Vidhya.
The post DataScience Project: Scraping YouTube Data using Python and Selenium to Classify Videos appeared first on Analytics Vidhya. This article was submitted as part of Analytics Vidhya’s Internship Challenge. Introduction I’m an avid YouTube user. The sheer amount of content I can.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Getting complete and high-performance data is not always the case. The post How to Fetch Data using API and SQL databases! appeared first on Analytics Vidhya.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as dataextraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
This article was published as a part of the DataScience Blogathon. Introduction to Data Engineering In recent days the consignment of data produced from innumerable sources is drastically increasing day-to-day. So, processing and storing of these data has also become highly strenuous.
Summary: This guide highlights the best free DataScience courses in 2024, offering a practical starting point for learners eager to build foundational DataScience skills without financial barriers. Introduction DataScience skills are in high demand. billion in 2021 and projected to reach $322.9
What is R in DataScience? As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. How is R Used in DataScience? R is a popular programming language and environment widely used in the field of datascience.
AI platforms offer a wide range of capabilities that can help organizations streamline operations, make data-driven decisions, deploy AI applications effectively and achieve competitive advantages. Visual modeling: Combine visual datascience with open source libraries and notebook-based interfaces on a unified data and AI studio.
In datascience, degradation in temperature is reflected through derivatives. We saw a gap in offerings that deliver adaptable, top-notch solutions that seamlessly integrate with customers’ current technology and met that need with streamlined dataextraction, maximized hardware investments and seamless third-party compatibility.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. So pretty much what is available to a developer or data scientist who is working with the open source libraries and going through their own datascience journey.
The multimodal PDF dataextraction blueprint uses NVIDIA NeMo Retriever NIM microservices to extract insights from enterprise documents, helping developers build powerful AI agents and chatbots. The digital human blueprint supports the creation of interactive, AI-powered avatars for customer service.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
Here, I use a practical, real example to walk you through the process of using GPT-4 to scrape renewable energy data from a web page, and then to visualize it with charts and maps. First off, the process that we are undertaking from beginning to end: DataExtraction: Start by identifying your data… Read the full blog for free on Medium.
Through its proficient understanding of language and patterns, it can swiftly navigate and comprehend the data, extracting meaningful insights that might have remained hidden by the casual viewer. You can also get datascience training on-demand wherever you are with our Ai+ Training platform. Get your pass today !
Extracting insights from videos involves understanding the content, context, and nuances present within the frames and audio tracks. Traditional methods often require manual annotation or simplistic automated processes that lack depth.
In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes dataextraction, management, and governance. The solution integrates data in three tiers. Then we move to the next stage of accessing the actual dataextracted from the raw unstructured data.
Automation of R&D in DataScience RD-Agent automates critical R&D tasks like data mining, model proposals, and iterative developments. Automating these key tasks allows AI models to evolve faster while continuously learning from the data provided.
DataExtraction This project explores how data from Reddit, a widely used platform for discussions and content sharing, can be utilized to analyze global sentiment trends.
A deep dive — dataextraction, initializing the model, splitting the data, embeddings, vector databases, modeling, and inference Photo by Simone Hutsch on Unsplash We are seeing a lot of use cases for langchain apps and large language models these days.
Tools The programming language I used to perform the analysis is Python, along with, but not limited to, the following libraries: import pandas as pd # structured data manipulationimport numpy as np # scientific and numerical computingimport scipy # scientific and numerical computingimport matplotlib.pyplot as plt # data visualisationimport seaborn (..)
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. Dataextraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data.
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and dataextraction, among other skills. This 10-hour course, also highly rated at 4.8,
DataScience has emerged as one of the most prominent and demanding prospects in the with millions of job roles coming up in the market. Pursuing a career in DataScience can be highly promising and you can become a DataScience even without having prior knowledge on technical concepts.
Summary: DataScience is becoming a popular career choice. Mastering programming, statistics, Machine Learning, and communication is vital for Data Scientists. A typical DataScience syllabus covers mathematics, programming, Machine Learning, data mining, big data technologies, and visualisation.
We will specifically focus on the two most common uses: template-based normalized key-value entity extractions and document Q&A, with large language models. Template-based normalized extractions In almost all IDP use cases, the dataextracted is eventually sent to a downstream system for further processing or analytics.
We’ll need to provide the chunk data, specify the embedding model used, and indicate the directory where we want to store the database for future use. Q1: Which are the 2 high focuses of datascience? A1: The two high focuses of datascience are Velocity and Variety, which are characteristics of Big Data.
It is crucial to pursue a metrics-driven strategy that emphasizes the quality of dataextraction at the field level, particularly for high-impact fields. Harness a flywheel approach, wherein continuous data feedback is utilized to routinely orchestrate and evaluate enhancements to your models and processes.
Focusing on multiple myeloma (MM) clinical trials, SEETrials showcases the potential of Generative AI to streamline dataextraction, enabling timely, precise analysis essential for effective clinical decision-making. Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai
With its user-friendly interface and powerful capabilities, you can efficiently label, train, deploy, and extract information without any coding knowledge. Embrace the world of effortless dataextraction and intelligent decision-making, empowering yourself to excel in the dynamic second-hand car market. Happy analyzing!
Perl: Known for its text processing capabilities, Perl is used for tasks like dataextraction, manipulation, and report generation. Web Scraping : Python’s libraries like BeautifulSoup facilitate web scraping for dataextraction and analysis. How do scripting languages contribute to datascience and analysis?
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of BeautifulSoup} Image by Author Behold the wondrous marvel known as BeautifulSoup, a mighty Python library renowned for its prowess in the realms of web scraping and dataextraction from HTML and XML documents.
With these developments, extraction and analysing of data have become easier while various techniques in dataextraction have emerged. Data Mining is one of the techniques in DataScience utilised for extracting and analyzing data.
Now you can run inference against the dataextracted from PrestoDB: body_str = "total_extended_price,avg_discount,total_quantityn1,2,3n66.77,12,2" response = smr.invoke_endpoint( EndpointName=endpoint_name, Body=body_str.encode('utf-8') , ContentType='text/csv', ) response_str = response["Body"].read().decode()
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest datascience and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. million human-written instructions for self-driving cars.
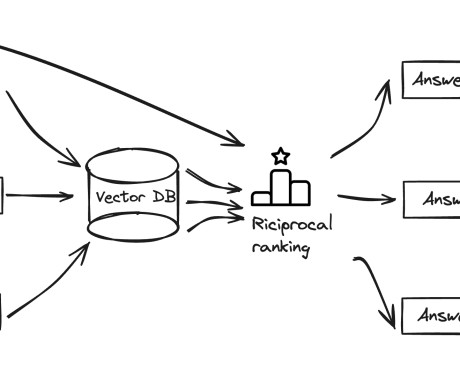
Image by Narciso on Pixabay Introduction Query Pipelines is a new declarative API to orchestrate simple-to-advanced workflows within LlamaIndex to query over your data. Other frameworks have built similar approaches, an easier way to build LLM workflows over your data like RAG systems, query unstructured data or structured dataextraction.
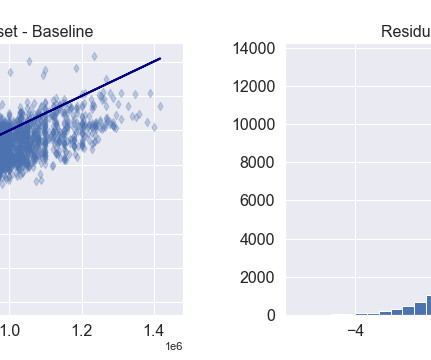
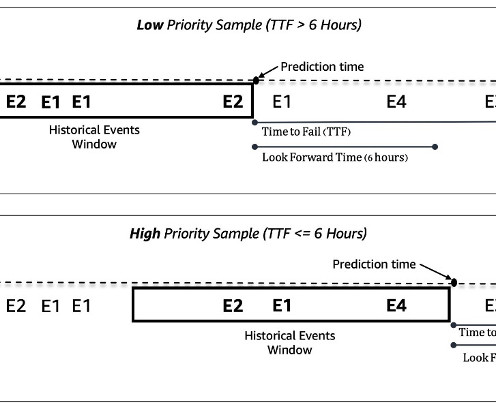
Careful optimization is needed in the dataextraction and preprocessing stage. About the authors Aruna Abeyakoon is the Senior Director of DataScience & Analytics at Light & Wonder Land-based Gaming Division. Event sequence modeling was challenging due to the extremely uneven distribution of events over time.
Introduction Welcome Back, Let's continue with our DataScience journey to create the Stock Price Prediction web application. The scope of this article is quite big, we will exercise the core steps of datascience, let's get started… Project Layout Here are the high-level steps for this project.
It involves mapping and transforming data elements to align with a unified schema. The Process of Data Integration Data integration involves three main stages: · DataExtraction It involves retrieving data from various sources. These courses will help you acquire all the skills in the data domain.
It combines text, table, and image (including chart) data into a unified vector representation, enabling cross-modal understanding and retrieval. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in datascience and independent consulting in AI/ML.
By understanding these key components, organisations can effectively manage and leverage their data for strategic advantage. Extraction This is the first stage of the ETL process, where data is collected from various sources. The goal is to retrieve the required data efficiently without overwhelming the source systems.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content