This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
artificialintelligence-news.com Meta confirms that its Llama 3 open source LLM is coming in the next month On Tuesday, Meta confirmed that it plans an initial release of Llama 3 — the next generation of its large language model used to power generative AI assistants — within the next month. techxplore.com Are deepfakes illegal?
legal document review) It excels in tasks that require specialised terminologies or brand-specific responses but needs a lot of computational resources and may become obsolete with new data. For instance, a medical LLM fine-tuned on clinical notes can make more accurate recommendations because it understands niche medical terminology.
Lets be real: building LLM applications today feels like purgatory. The truth is, we’re in the earliest days of understanding how to build robust LLM applications. What makes LLM applications so different? Two big things: They bring the messiness of the real world into your system through unstructured data.
Created Using Midjourney In case you missed yesterday’s newsletter due to July the 4th holiday, we discussed the universe of in-context retrieval augmented LLMs or techniques that allow to expand the LLM knowledge without altering its core architecutre. Like any large tech company, data is the backbone of the Uber platform.
This is not ideal because data distribution is prone to change in the real world which results in degradation in the model’s predictive power, this is what you call datadrift. There is only one way to identify the datadrift, by continuously monitoring your models in production.
This problem often stems from inadequate user value, underwhelming performance, and an absence of robust best practices for building and deploying LLM tools as part of the AI development lifecycle. Real-world applications often expose gaps that proper data preparation could have preempted. Engineering scalable and adaptable solutions.
Some popular data quality monitoring and management MLOps tools available for data science and ML teams in 2023 Great Expectations Great Expectations is an open-source library for data quality validation and monitoring. It could help you detect and prevent data pipeline failures, datadrift, and anomalies.
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
When Vertex Model Monitoring detects datadrift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. See what Snorkel option is right for you. Book a demo today. The post Snorkel Flow 2023.R3
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. Prompt-response management: Refining LLM-backed applications through continuous prompt-response optimization and quality control.
Query validation and improvement To constrain the LLM output, we can introduce additional mechanisms for validating and improving the query. At each generation step by the LLM, tokens that would invalidate the query are rejected, and the highest-probability valid tokens are kept.
The quick turnaround was particularly impressive considering the absence of any labeled data at the onset, and particularly valuable because it allowed them to complete their project ahead of the deadline dictated by their pending partnership. Ongoing success and future plans The client continues to use our platform independently.
Deepchecks Deepchecks specializes in LLM evaluation. These capabilities enable organizations to rigorously test, monitor, and improve their LLM applications while maintaining complete data sovereignty. This proactive approach allows teams to quickly resolve issues, continuously improving model reliability and performance.
This approach allows AI applications to interpret natural language queries, retrieve relevant data, and generate human-like responses grounded in accurate information. When a user inputs a query, an LLM (large language model) interprets it using Natural Language Understanding (NLU). and Mistral.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


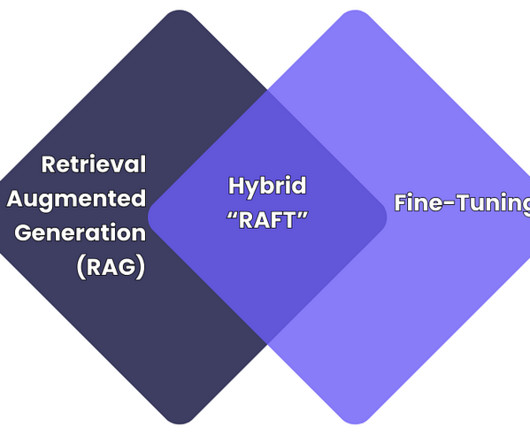

















Let's personalize your content