This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data validation frameworks play a crucial role in maintaining dataset integrity over time. Automated tools such as TensorFlow Data Validation (TFDV) and Great Expectations help enforce schema consistency, detect anomalies, and monitor datadrift. Another promising development is the rise of explainabledata pipelines.
along with the EU AI Act , support various principles such as accuracy, safety, non-discrimination, security, transparency, accountability, explainability, interpretability, and data privacy. Machine learning starts with a defined dataset, but is then set free to absorb new data and create new learning paths and new conclusions.
Answering them, he explained, requires an interdisciplinary approach. tweaktown.com Research Researchers unveil time series deep learning technique for optimal performance in AI models A team of researchers has unveiled a time series machine learning technique designed to address datadrift challenges.
Post-deployment monitoring and maintenance: Managing deployed models includes monitoring for datadrift, model performance issues, and operational errors, as well as performing A/B testing on your different models. You must be able to explain complex thing easily without dumbing them down.
But just as important, you want it to be explainable. Explainability requirements continue after the model has been deployed and is making predictions. It should be clear when datadrift is happening and if the model needs to be retrained. MLDev Explainability. Global Explainability . Local Explainability.
The Problems in Production Data & AI Model Output Building robust AI systems requires a thorough understanding of the potential issues in production data (real-world data) and model outcomes. Model Drift: The model’s predictive capabilities and efficiency decrease over time due to changing real-world environments.
Key Challenges in ML Model Monitoring in Production DataDrift and Concept DriftData and concept drift are two common types of drift that can occur in machine-learning models over time. Datadrift refers to a change in the input data distribution that the model receives.
Baseline job datadrift: If the trained model passes the validation steps, baseline stats are generated for this trained model version to enable monitoring and the parallel branch steps are run to generate the baseline for the model quality check. Monitoring (datadrift) – The datadrift branch runs whenever there is a payload present.
True to its name, Explainable AI refers to the tools and methods that explain AI systems and how they arrive at a certain output. In this blog, we’ll dive into the need for AI explainability, the various methods available currently, and their applications. Why do we need Explainable AI (XAI)?
Discuss with stakeholders how accuracy and datadrift will be monitored. Incorporate methodologies to address model drift and datadrift. Ensure predictions are explainable. Predictions can be made in batches or in real time. Predictions can be saved to a database or used immediately in another process.
In parallel to using data quality drift checks as a proxy for monitoring model degradation, the system also monitors feature attribution drift using the normalized discounted cumulative gain (NDCG) score. Alerts are raised whenever anomalies are detected. For a detailed understanding, we use Amazon SageMaker Clarify.
Uber wrote about how they build a datadrift detection system. In our case that meant prioritizing stability, performance, and flexibility above all else. Don’t be afraid to use boring technology.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and data science experience who wanted to implement MLOps.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. Some popular data quality monitoring and management MLOps tools available for data science and ML teams in 2023 Great Expectations Great Expectations is an open-source library for data quality validation and monitoring.
Offering a seamless workflow, the platform integrates with the cloud and data sources in the ecosystem today. Data science teams have explainability and governance with one-click compliance documentation, blueprints, and model lineage. Advanced features like monitoring, datadrift tracking, and retraining keep models aligned.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
This post explains the functions based on a modular pipeline approach. You can set up automated alerts to notify when there are deviations in the model quality, such as datadrift and anomalies. Amazon SageMaker Model Monitor helps continuously monitor the quality of your ML models in real time.
And sensory gating causes our brains to filter out information that isn’t novel, resulting in a failure to notice gradual datadrift or slow deterioration in system accuracy. DataDrift assesses how the distribution of data changes across all features. Contact us to request a personal demo. Request a demo.
Improve model accuracy: In-depth feature engineering (example, PCA) Hyperparameter optimization (HPO) Quality assurance and validation with test data. Monitoring setup (model, datadrift). Data Engineering Explore using feature store for future ML use cases. Deploy to production (inference endpoint).
The model training process is not a black box—it includes trust and explainability. You can see the entire process from data to predictions with all of the different steps—as well as the supportive documentation on every stage and an automated compliance report, which is very important for highly regulated industries.
All models built within DataRobot MLOps support ethical AI through configurable bias monitoring and are fully explainable and transparent. The in-built, data quality assessments and visualization tools result in equitable, fair models that minimize the potential for harm, along with world-class datadrift, service help, and accuracy tracking.
I’m also excited to spread the word about some of the latest enhancements and integrations between Datarobot’s AI Cloud and Snowflake’s Data Cloud. I’ll explain these briefly, along with why they are good news for our joint customers. For example, your data may have valid value ranges. Scoring code. Prediction explanations.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
DataRobot does a great job of explaining exactly how it got to this feature. It joins the primary data with the city-level dataset and calculates the moving 90-day median. Delivering Explainable and Transparent Models with DataRobot Explainability is a key differentiator in DataRobot that allows for smoother collaboration on your team.
The second is drift. Then there’s data quality, and then explainability. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift. Approaching drift resolution looks very similar to how we approach performance tracing.
The second is drift. Then there’s data quality, and then explainability. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift. Approaching drift resolution looks very similar to how we approach performance tracing.
The second is drift. Then there’s data quality, and then explainability. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift. Approaching drift resolution looks very similar to how we approach performance tracing.
Articles Netflix explained how they build a federated search on their heterogeneous contents for their content engineering. Built for data scientists, NannyML has an easy-to-use interface, interactive visualizations, is completely model-agnostic and currently supports all tabular use cases, classification and regression.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes data quality, privacy, and compliance. AWS Cloudwatch is an excellent tool we used to log these events and send notifications.
This explainability of the predictions can help you see how and why the AI came to these predictions. Set up a data pipeline that delivers predictions to HubSpot and automatically initiate offers within the business rules you set. A look at datadrift. A clear picture of the model’s accuracy.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. We pay our contributors, and we don’t sell ads.
The proposed architecture for the batch inference pipeline uses Amazon SageMaker Model Monitor for data quality checks, while using custom Amazon SageMaker Processing steps for model quality check. Model approval After a newly trained model is registered in the model registry, the responsible data scientist receives a notification.
We will focus on the six requirements that seem most important for the task: accuracy, scalability, speed, explainability, privacy and adaptability over time. Adaptability over time To use Text2SQL in a durable way, you need to adapt to datadrift, i. the changing distribution of the data to which the model is applied.
Monitoring Monitor model performance for datadrift and model degradation, often using automated monitoring tools. In the future, the landscape will focus more on: Explainability and interpretability: As LLMOps technology improves, so will explainability features that help you understand how LLMs arrive at their outputs.
Together, these data ops efforts ensure that model development time is efficient, model performance is robust, and teams focus more on innovation and customer experience, which is what matters. The piece that connects the model to the application and the data is the explainability of the model. Bayan Bruss: Thanks Kishore.
Together, these data ops efforts ensure that model development time is efficient, model performance is robust, and teams focus more on innovation and customer experience, which is what matters. The piece that connects the model to the application and the data is the explainability of the model. Bayan Bruss: Thanks Kishore.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Is it a black-box model, or can the decisions be explained?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












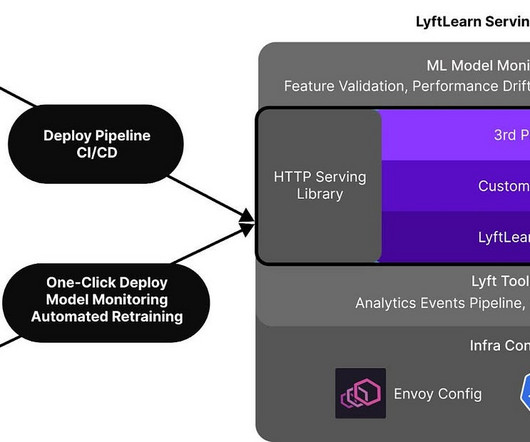








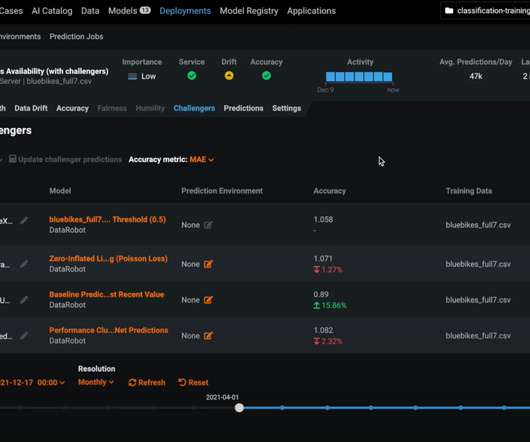





















Let's personalize your content