This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for datascientist to remain competitive in the market. Coding skills remain important, but the real value of datascientists today is shifting.
along with the EU AI Act , support various principles such as accuracy, safety, non-discrimination, security, transparency, accountability, explainability, interpretability, and data privacy. Human element: Datascientists are vulnerable to perpetuating their own biases into models. Moreover, both the EU and the U.S.
Collaboration – Datascientists each worked on their own local Jupyter notebooks to create and train ML models. They lacked an effective method for sharing and collaborating with other datascientists. This has helped the datascientist team to create and test pipelines at a much faster pace.
Each product translates into an AWS CloudFormation template, which is deployed when a datascientist creates a new SageMaker project with our MLOps blueprint as the foundation. These are essential for monitoring data and model quality, as well as feature attributions. Alerts are raised whenever anomalies are detected.
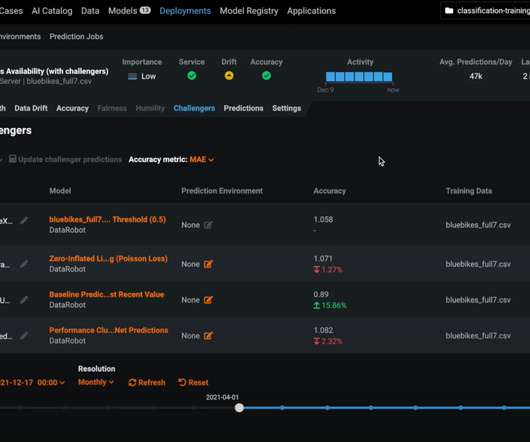
The primary goal of model monitoring is to ensure that the model remains effective and reliable in making predictions or decisions, even as the data or environment in which it operates evolves. Datadrift refers to a change in the input data distribution that the model receives. The MLOps difference?
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. The platform gives you a unified set of tools for enterprise‑grade solutions for everything you need to do with data, including building, deploying, sharing, and maintaining solutions that have to do with data.
Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Datascientists need to understand the business problem and the project scope to assess feasibility, set expectations, define metrics, and design project blueprints. Monitor and observe results.
True to its name, Explainable AI refers to the tools and methods that explain AI systems and how they arrive at a certain output. In this blog, we’ll dive into the need for AI explainability, the various methods available currently, and their applications. Why do we need Explainable AI (XAI)?
Uber wrote about how they build a datadrift detection system. This incident was detected after 45 days manually by one of the datascientists. In our case that meant prioritizing stability, performance, and flexibility above all else. Don’t be afraid to use boring technology. How was it Detected?
This post explains the functions based on a modular pipeline approach. Datascientists can use Amazon SageMaker Experiments , which automatically tracks the inputs, parameters, configurations, and results of iterations as trials.
By outsourcing the day-to-day management of the data science platform to the team who created the product, AI builders can see results quicker and meet market demands faster, and IT leaders can maintain rigorous security and data isolation requirements.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
Ensuring Long-Term Performance and Adaptability of Deployed Models Source: [link] Introduction When working on any machine learning problem, datascientists and machine learning engineers usually spend a lot of time on data gathering , efficient data preprocessing , and modeling to build the best model for the use case.
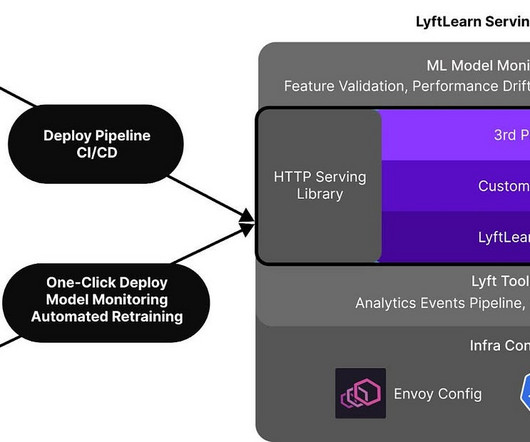
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
For true impact, AI projects should involve datascientists, plus line of business owners and IT teams. By 2025, according to Gartner, chief data officers (CDOs) who establish value stream-based collaboration will significantly outperform their peers in driving cross-functional collaboration and value creation.
With governed, secure, and compliant environments, datascientists have the time to focus on innovation, and IT teams can focus on compliance, risk, and production with live performance updates, streamed to a centralized machine learning operations system.
When a new version of the model is registered in the model registry, it triggers a notification to the responsible datascientist via Amazon SNS. If the batch inference pipeline discovers data quality issues, it will notify the responsible datascientist via Amazon SNS.
The model training process is not a black box—it includes trust and explainability. You can see the entire process from data to predictions with all of the different steps—as well as the supportive documentation on every stage and an automated compliance report, which is very important for highly regulated industries.
The first is by using low-code or no-code ML services such as Amazon SageMaker Canvas , Amazon SageMaker Data Wrangler , Amazon SageMaker Autopilot , and Amazon SageMaker JumpStart to help data analysts prepare data, build models, and generate predictions. Monitoring setup (model, datadrift).
For example, the IKEA effect is a cognitive bias that causes datascientists to overvalue AI systems that they have personally built. And sensory gating causes our brains to filter out information that isn’t novel, resulting in a failure to notice gradual datadrift or slow deterioration in system accuracy.
This could lead to performance drifts. Performance drifts can lead to regression for a slice of customers. And usually what ends up happening is that some poor datascientist or ML engineer has to manually troubleshoot this in a Jupyter Notebook. The second is drift. How do you detect changes in distribution?
This could lead to performance drifts. Performance drifts can lead to regression for a slice of customers. And usually what ends up happening is that some poor datascientist or ML engineer has to manually troubleshoot this in a Jupyter Notebook. The second is drift. How do you detect changes in distribution?
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. You can get the full code here. We pay our contributors, and we don’t sell ads.
This could lead to performance drifts. Performance drifts can lead to regression for a slice of customers. And usually what ends up happening is that some poor datascientist or ML engineer has to manually troubleshoot this in a Jupyter Notebook. The second is drift. How do you detect changes in distribution?
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial.
Articles Netflix explained how they build a federated search on their heterogeneous contents for their content engineering. Built for datascientists, NannyML has an easy-to-use interface, interactive visualizations, is completely model-agnostic and currently supports all tabular use cases, classification and regression.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
The platform typically includes components for the ML ecosystem like data management, feature stores, experiment trackers, a model registry, a testing environment, model serving, and model management. It checks the data for quality issues and detects outliers and anomalies. Is it a black-box model, or can the decisions be explained?
Figure 1: Representation of the Text2SQL flow As our world is getting more global and dynamic, businesses are more and more dependent on data for making informed, objective and timely decisions. However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of datascientists and analysts.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content