

The Importance of Data Drift Detection that Data Scientists Do Not Know
Analytics Vidhya
OCTOBER 15, 2021
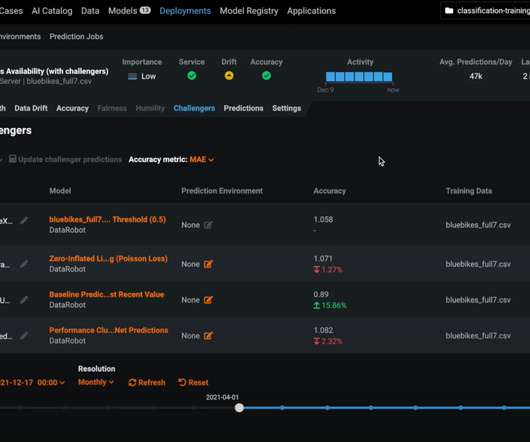
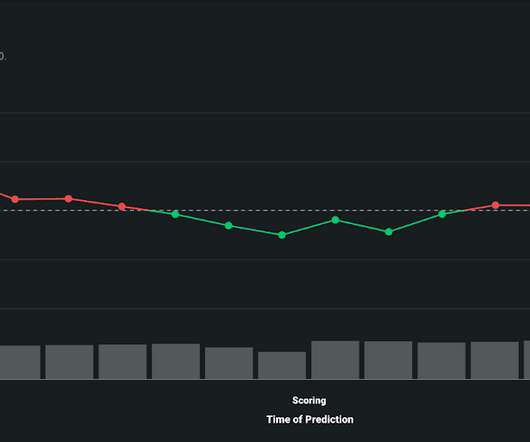
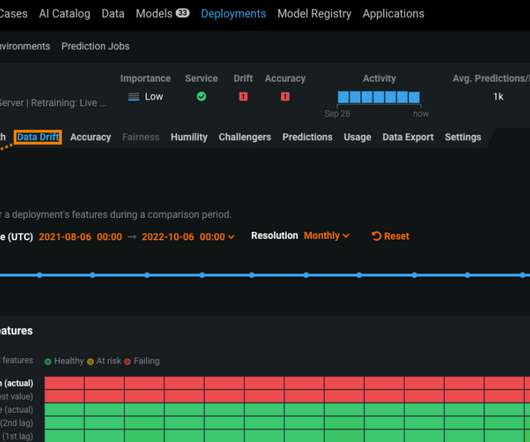
There might be changes in the data distribution in production, thus causing […]. The post The Importance of Data Drift Detection that Data Scientists Do Not Know appeared first on Analytics Vidhya. But, once deployed in production, ML models become unreliable and obsolete and degrade with time.







































Let's personalize your content