This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon What is Model Monitoring and why is it required? Machine learning creates static models from historical data. There might be changes in the data distribution in production, thus causing […].
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for datascientist to remain competitive in the market. Coding skills remain important, but the real value of datascientists today is shifting.
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and data governance processes.
Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among datascientists, DevOps engineers, and IT teams. Model Training Frameworks This stage involves the process of creating and optimizing predictive models with labeled and unlabeled data.
Axfood has a structure with multiple decentralized datascience teams with different areas of responsibility. Together with a central data platform team, the datascience teams bring innovation and digital transformation through AI and ML solutions to the organization.
DataScience Software Acceleration at the Edge Attendees had an amazing time learning about unlocking the potential of datascience through acceleration. The approach is comprehensive and ensures efficient utilization of resources and maximizes the impact of datascience in edge computing environments.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute datascience workflows.
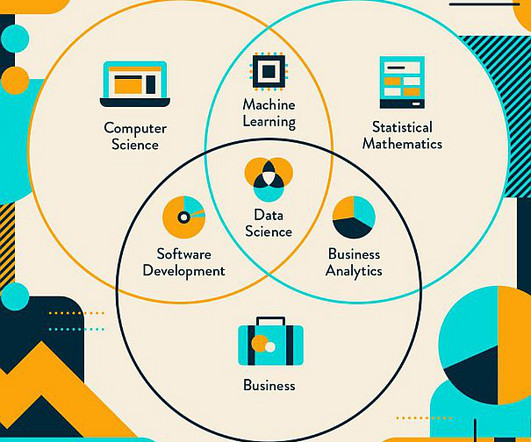
Datascience is a multidisciplinary field that relies on scientific methods, statistics, and Artificial Intelligence (AI) algorithms to extract knowledgable and meaningful insights from data. At its core, datascience is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions.
As a result, enterprises can now get powerful insights and predictive analytics from their business data by integrating DataRobot-trained machine learning models into their SAP-specific business processes and applications, while bringing datascience and analytics teams and business users closer together for better outcomes.
As AI-driven use cases increase, the number of AI models deployed increases as well, leaving resource-strapped datascience teams struggling to monitor and maintain this growing repository. “We These accelerators are specifically designed to help organizations accelerate from data to results.
Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Datascientists need to understand the business problem and the project scope to assess feasibility, set expectations, define metrics, and design project blueprints. Assess the infrastructure.
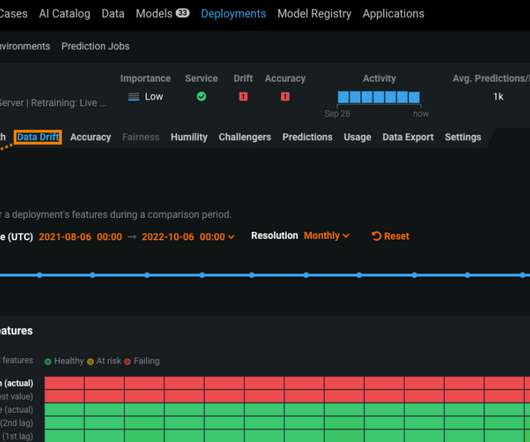
Datadrift is a phenomenon that reflects natural changes in the world around us, such as shifts in consumer demand, economic fluctuation, or a force majeure. The key, of course, is your response time: how quickly datadrift can be analyzed and corrected. Drill Down into Drift for Rapid Model Diagnostics.
The primary goal of model monitoring is to ensure that the model remains effective and reliable in making predictions or decisions, even as the data or environment in which it operates evolves. Datadrift refers to a change in the input data distribution that the model receives.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
Machine Learning Operations (MLOps) can significantly accelerate how datascientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
The first is by using low-code or no-code ML services such as Amazon SageMaker Canvas , Amazon SageMaker Data Wrangler , Amazon SageMaker Autopilot , and Amazon SageMaker JumpStart to help data analysts prepare data, build models, and generate predictions. Conduct exploratory analysis and data preparation.
By outsourcing the day-to-day management of the datascience platform to the team who created the product, AI builders can see results quicker and meet market demands faster, and IT leaders can maintain rigorous security and data isolation requirements. Peace of Mind with Secure AI-Driven DataScience on Google Cloud.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
How do you drive collaboration across teams and achieve business value with datascience projects? With AI projects in pockets across the business, datascientists and business leaders must align to inject artificial intelligence into an organization. You can also go beyond regular accuracy and datadrift metrics.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a datascience development account (which has more controls than a typical application development account).
This new guided workflow is designed to ensure success for your AI use case, regardless of complexity, catering to both seasoned datascientists and those just beginning their journey. See what Snorkel can do to accelerate your datascience and machine learning teams. Book a demo today. The post Snorkel Flow 2023.R3
Ensuring Long-Term Performance and Adaptability of Deployed Models Source: [link] Introduction When working on any machine learning problem, datascientists and machine learning engineers usually spend a lot of time on data gathering , efficient data preprocessing , and modeling to build the best model for the use case.
With governed, secure, and compliant environments, datascientists have the time to focus on innovation, and IT teams can focus on compliance, risk, and production with live performance updates, streamed to a centralized machine learning operations system. MLOps allows organizations to stand out in their AI implementation.
Solution: Because MLOps allows model reuse, datascientists do not have to create the same models over and over, and the business can package, control, and scale them. Refreshing models according to the business schedule or signs of datadrift. How to Thrive in the Age of Data Dominance. Download Now.
Inadequate Monitoring : Neglecting to monitor user interactions and datadrifts hampers insights into product adoption and long-term performance. By adopting these practices, data professionals can drive innovation while mitigating risks, ensuring LLM-based solutions achieve both traction and reliability.
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional data engineering and machine learning life cycles.
There are several techniques used for model monitoring with time series data, including: DataDrift Detection: This involves monitoring the distribution of the input data over time to detect any changes that may impact the model’s performance. You can get the full code here. We pay our contributors, and we don’t sell ads.
Failure to consider the severity of these problems can lead to issues like degraded model accuracy, datadrift, security issues, and data inconsistencies. Data retrieval: Having several dataset versions requires machine learning practitioners to know which dataset versions correspond to a certain model performance outcome.
By simplifying Time Series Forecasting models and accelerating the AI lifecycle, DataRobot can centralize collaboration across the business—especially datascience and IT teams—and maximize ROI. You can also deploy the model using the DataRobot API—ensuring a smooth and fast connection between datascientists and the IT team.
Uber wrote about how they build a datadrift detection system. This incident was detected after 45 days manually by one of the datascientists. In our case that meant prioritizing stability, performance, and flexibility above all else. Don’t be afraid to use boring technology. How was it Detected?
Stefan is a software engineer, datascientist, and has been doing work as an ML engineer. He also ran the data platform in his previous company and is also co-creator of open-source framework, Hamilton. To a junior datascientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Datascience practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
The platform typically includes components for the ML ecosystem like data management, feature stores, experiment trackers, a model registry, a testing environment, model serving, and model management. It checks the data for quality issues and detects outliers and anomalies. Pipelines can be scheduled to carry out CI, CD, or CT.
This workflow will be foundational to our unstructured data-based machine learning applications as it will enable us to minimize human labeling effort, deliver strong model performance quickly, and adapt to datadrift.” – Jon Nelson, Senior Manager of DataScience and Machine Learning at United Airlines.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content