This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Luckily, Excel’s VLOOKUP tool comes to the rescue, making datadiscovery much easier. Whether you’re a seasoned Excel user or a beginner, mastering VLOOKUP can greatly enhance your data analysis skills. Are you tired of spending endless hours searching for specific information in large Excel files?
Key components of data security platforms Effective DSPs are built on several core components that work together to protect data from unauthorised access, misuse, and theft. Datadiscovery and classification Before data can be secured, it needs to be classified and understood. The components include: 1.
This requires traditional capabilities like encryption, anonymization and tokenization, but also creating capabilities to automatically classify data (sensitivity, taxonomy alignment) by using machine learning.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
Today, datadiscovery and classification provider BigID announced the launch of BigAI, a new large language model (LLM) designed to scan and classify enterprises’ data to optimize their security and enhance risk management initiatives. BigAI enables organizations to scan structured and unstructured …
The post Using Healthcare-Specific LLM’s for DataDiscovery from Patient Notes & Stories appeared first on John Snow Labs. We will also review responsible and trustworthy AI practices that are critical to delivering these technology in a safe and secure manner.
If you add in IBM data governance solutions, the top left will look a bit more like this: The data governance solution powered by IBM Knowledge Catalog offers several capabilities to help facilitate advanced datadiscovery, automated data quality and data protection.
The platform’s distinctive and adaptable design makes connecting and organizing data across any cloud storage option possible. As a result, data silos are eliminated and procedures are streamlined. Key Features When it comes to artificial intelligence, old-fashioned data management technologies can’t keep up.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change?
AI-powered features in Cognos Analytics today IBM has embedded AI throughout Cognos Analytics to streamline processes, enhance datadiscovery and enable users to gain deeper insights with minimal effort. These capabilities lend themselves to a vision for the next generation of BI, powered by IBM® Granite™ foundation models.
Further development of watsonx.data will also incorporate IBM’s Storage Fusion technology to enhance data caching across remote sources as well as semantic automation capabilities built on IBM Research’s foundation models to automate datadiscovery, exploration, and enrichment through conversational user experiences.
” AI automation tools can facilitate more efficient evaluation and review procedures, perform sensitive datadiscoveries and support monitoring. . “Chasing after compliance regulations and spending all your energy to check off boxes is not the best way to use your cyber talent.”
An enterprise data catalog does all that a library inventory system does – namely streamlining datadiscovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Rethink data protection in the gen AI era With the scale and use scenarios of data in gen AI solutions, organizations must rethink their data lifecycle and how to protect it at scale, in all its states. Think about securing training data by protecting it from theft and manipulation.
For example, a bank may get rid of its decade old datawarehouse and deliver all BI and AI use cases from a single data platform, by implementing a lakehouse. Address data complexity with a data fabric architecture. Along with existing data platform nodes, one or multiple lakehouse nodes may also participate there.
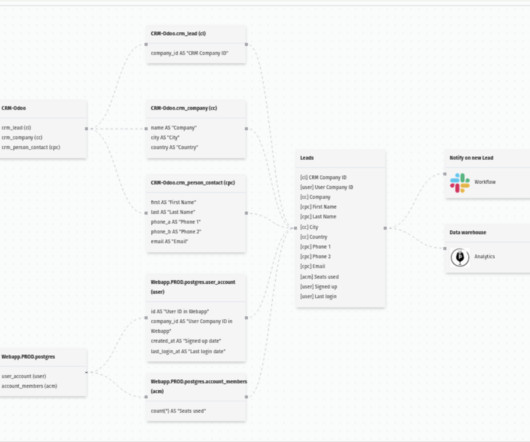
The first is the raw input data that gets ingested by source systems, the second is the output data that gets extracted from input data using AI, and the third is the metadata layer that maintains a relationship between them for datadiscovery.
DATALORE uses Large Language Models (LLMs) to reduce semantic ambiguity and manual work as a data transformation synthesis tool. Second, for each provided base table T, the researchers use datadiscovery algorithms to find possible related candidate tables. These models have been trained on billions of lines of code.
Even among datasets that include the same subject matter, there is no standard layout of files or data formats. This obstacle lowers productivity through machine learning development—from datadiscovery to model training. Additionally, it makes it harder to create essential tools for dealing with huge datasets.
A well-designed data architecture creates a foundation for data quality through transparency and standardization that frames how your organization views, uses and talks about data. As previously mentioned, a data fabric is one such architecture.
With a semantic layer, you can generate data enrichments that enable clients to find and understand previously cryptic, effectively structured data across your data estate in natural language through semantic search to accelerate datadiscovery and unlock data insights faster, no SQL required.
Conclusion The incorporation of generative AI into Discovery Navigator underscores Verisk’s commitment to using cutting-edge technologies to drive operational efficiencies and enhance outcomes for its clients in the insurance industry.
June 8, 2015: Attivio ( www.attivio.com ), the Data Dexterity Company, today announced Attivio 5, the next generation of its software platform. Newton, Mass., Attivio 5 will be made available for evaluation the following day, Wednesday, June 10.
In Rita Sallam’s July 27 research, Augmented Analytics , she writes that “the rise of self-service visual-bases datadiscovery stimulated the first wave of transition from centrally provisioned traditional BI to decentralized datadiscovery.” We agree with that.
In the scientific community and throughout various levels of the public sector, reproducibility and transparency are essential for progress, so sharing data is vital.
Clustering: Grouping similar data points to identify segments within the data. Applications EDA is widely employed in research and datadiscovery across industries. Researchers use EDA to better understand their data before conducting more formal statistical analyses.
Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai In this demo, you’ll see how Delphina’s AI-powered “junior” data scientist can transform the data science workflow, automating labor-intensive tasks like datadiscovery, transformation, and model building.
In a blog post by Snowflake co-founder Benoit Dagevill, he acknowledged that the goal of this addon will be to use generative AI and other AI-based tools to allow their users to query data in new ways to help them with datadiscovery.
Get Answers as Fast as the World Produces Data With Visual Analytics on SAS Viya, you’ll have datadiscovery and exploration with interactive reporting all from a single application. Keeping all stakeholders informed and involved to make the most informed next action is paramount.
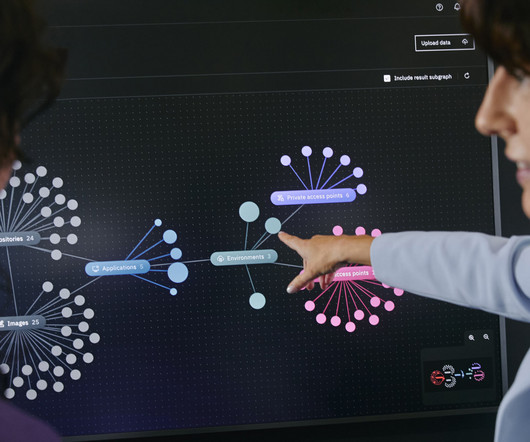
Datadiscovery, mapping, classification, incident response, and remediation are ongoing. With the automated remediation that DSPM offers, access policies can be tweaked to adhere to zero trust methodology. This reduces the chance of misusing stolen credentials to gain illicit access. DSPM has to be a continuous process.
Each subsystem is essential, and sequentially, each sub-system feeds into the next until data reaches its destination. ETL data pipeline architecture | Source: Author DataDiscovery: Data can be sourced from various types of systems, such as databases, file systems, APIs, or streaming sources.
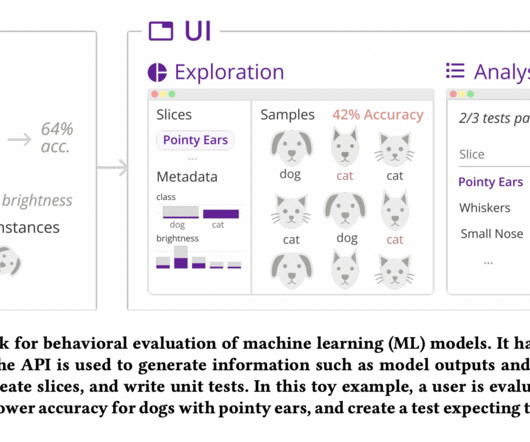
There are two main zeno frontend views: the Exploration UI, which is used for datadiscovery and slice creation, and the Analysis UI, which is used for test creation, report creation, and performance monitoring. The API’s outputs are a framework to build the main interface for conducting behavioral evaluation and testing.
Tools and Technologies for Data Classification: Aiding the Process This can be complex and time-consuming, especially for large organizations with vast amounts of data. To create a comprehensive data inventory, they can scan network drives, cloud storage repositories, and even employee devices.
AWS Glue A fully managed ETL service that makes it easy to prepare and load data for analytics. It automates the process of datadiscovery, transformation, and loading. These tools streamline the process, allowing organisations to focus on analysing the data rather than managing the ingestion itself.
However, use colour judiciously, considering colour blindness and ensuring colour choices effectively represent the data. Interactivity Enhances Engagement Explore interactive visualizations that allow users to explore the data themselves. This can foster deeper understanding and promote datadiscovery.
Utilizing Hive in Hadoop: Use Cases and Benefits Hive is widely used in big data analytics for various use cases, including: Data Exploration Hive allows users to interactively explore and analyze large datasets stored in Hadoop, enabling datadiscovery and gaining valuable insights.
Uncovering the Power of Comet Across the Data Science Journey Photo by Nguyen Le Viet Anh on Unsplash Machine learning (ML) projects are usually complicated and include several stages, from datadiscovery to model implementation. Comet is a robust platform that provides comprehensive functionality to streamline these stages.
An online SQL client, a cloud data backup tool, and an OData server-as-a-service option are also included. Voracity supports hundreds of data sources and immediately feeds BI and visualization targets as a “production analytic platform.”
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and Data Quality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage.
Generally, data is produced by one team, and then for that to be discoverable and useful for another team, it can be a daunting task for most organizations. Even larger, more established organizations struggle with datadiscovery and usage.
Algorithmic methods that find clusters of data with high error have also shown promise for surfacing problematic behaviors. Datadiscovery and generation. Having high-quality, representative data remains a persistent obstacle for behavioral evaluation.
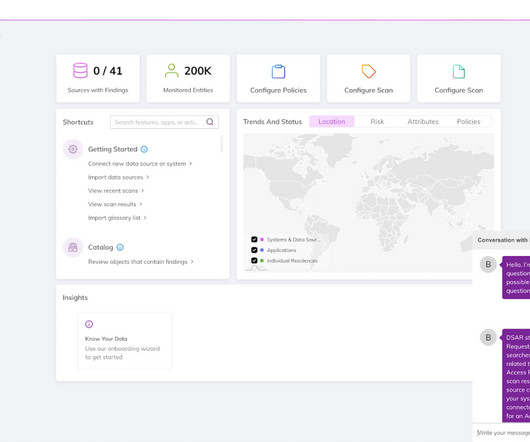
You can also use custom data identifiers to create data identifiers tailored to your specific use case. Datadiscovery and findability Findability is an important step of the process. Organizations need to have mechanisms to find the data under consideration in an efficient and quick manner for timely response.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content