This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video dataanalysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Database metadata can be expressed in various formats, including schema.org and DCAT. Unfortunately, these formats weren’t made with machine learning data in mind. Google has recently introduced Croissant, a new format for metadata in ML-ready datasets. Users can then publish their datasets.
This type of siloed thinking leads to data redundancy and slower data-retrieval speeds, so companies need to prioritize cross-functional communications and collaboration from the beginning. Here are four best practices to help future-proof your data strategy: 1.
Illumex enables organizations to deploy genAI analytics agents by translating scattered, cryptic data into meaningful, context-rich business language with built-in governance. By creating business terms, suggesting metrics, and identifying potential conflicts, Illumex ensures data governance at the highest standards.
They can select from options like requesting vacation time, checking company policies using the knowledge base, using a code interpreter for dataanalysis, or submitting expense reports. Code Interpreter For performing calculations and dataanalysis. A code interpreter tool for performing calculations and dataanalysis.
Data discovery has become increasingly challenging due to the proliferation of easily accessible dataanalysis tools and low-cost cloud storage. While these advancements have democratized data access, they have also led to less structured data stores and a rapid expansion of derived artifacts in enterprise environments.
Developers have designed a system in compliance with European General Data Protection Rules or GDPR by storing privacy-related information, and artwork metadata in a distributed file system that exists off the chain. Large-scale dataanalysis methods that offer privacy protection by utilizing both blockchain and AI technology.
This approach helps teams identify patterns in manufacturing quality, predict maintenance needs, and improve supply chain resilience, making dataanalysis more effective and scalable across the organization. You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base.
Team Whistle is using AI to generate metadata for its videos on social platforms like TikTok and YouTube and claimed more of these videos have gone viral, which evp of content Noah Weissman credits in part to the technology. One TikTok video that Team Whistle used AI to help with research, metadata and scripting has over 176,000 views.
Oil and gas dataanalysis – Before beginning operations at a well a well, an oil and gas company will collect and process a diverse range of data to identify potential reservoirs, assess risks, and optimize drilling strategies. Consider a financial dataanalysis system.
4 Ways to Use Speech AI for Healthcare Market Research Speech AI helps researchers gain deeper insights, improve the accuracy of their data, and accelerate the time from research to actionable results. Marvin is a qualitative dataanalysis platform that has integrated advanced AI models to accelerate and improve its research processes.
Return item metadata in inference responses – The new recipes enable item metadata by default without extra charge, allowing you to return metadata such as genres, descriptions, and availability in inference responses. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts.
introduces several new features, including metadata columns, partitioning, and auxiliary columns. The update allows users to store non-vector data alongside vectors in virtual tables, enabling advanced filtering and metadata integration directly within queries. The latest version, 0.1.6, The updates in version 0.1.6
Generate accompanying metadata describing dataset characteristics and the generation process. The end result is a diverse, realistic synthetic dataset for uses like system testing, ML model training, or dataanalysis. The metadata provides transparency into the generation process and data characteristics.
The following diagram illustrates the solution architecture. Immediate (0-30 days):** - Enforce IMDSv2 on all EC2 instances - Conduct S3 bucket permission audit and rectify public access issues - Adjust security group rules to eliminate broad access 2.
ETL ( Extract, Transform, Load ) Pipeline: It is a data integration mechanism responsible for extracting data from data sources, transforming it into a suitable format, and loading it into the data destination like a data warehouse. The pipeline ensures correct, complete, and consistent data.
It includes the capability to define relationships between different data elements, apply business logic, and standardize metrics across various data sources. Enhanced Data Consistency: They ensure that everyone in the organization uses the same definitions and business rules, leading to consistent and reliable analytics.
It leverages both GPU and CPU processing to query massive datasets quickly, with support for SQL and geospatial data. The platform includes visual analytics tools for interactive dashboards, cross-filtering, and scalable data visualizations, enabling efficient big dataanalysis across various industries. How does HEAVY.AI
loading webpage content by URL and pandas dataframe on the fly These loaders use standard document formats comprising content and associated metadata. Data Loaders in LangChain Using prebuild loaders is often more comfortable than writing your own. connect to applications (Slack, Notion, Figma, Wikipedia, etc.). ChunkViz v0.1
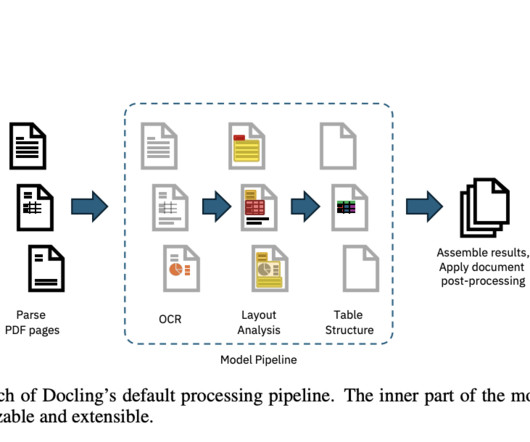
Traditional methods often falter due to the wide variability in PDF formats, leading to problems such as inaccurate table reconstruction, misplaced text, and lost metadata. The results of these analyses are then aggregated and post-processed to enhance metadata, determine the document’s language, and correct reading order.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadataanalysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables.
LLM-powered dataanalysis The transcribed interviews and ingested documents are fed into a powerful LLM, which can understand and correlate the information from multiple sources. The LLM can identify key insights, potential issues, and areas of non-compliance by analyzing the content and context of the data.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, data lakes, data warehouses and SQL databases, providing a holistic view into business performance. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. There are 16 files that include product description and metadata of Amazon products in the format of listings/metadata/listings_.json.gz. We use the first metadata file in this demo.
These advanced technologies can handle a wide range of tasks, such as customer support, dataanalysis, scheduling, and even content generation! This intuitive approach simplifies asset discovery and enables quick access to relevant files based on various criteria, such as file types, tags, metadata, timeframe, and more.
SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including dataanalysis, data processing, model training, generative AI app building, and more, in a single governed environment.
My story (The Shift from Jupyter Notebooks to VS Code) Throughout early to mid-2019, when I started my data science career, Jupyter Notebooks were my constant companions. Because of its interactive features, it’s ideal for learning and teaching, prototypes, exploratory dataanalysis projects, and visualizations.
Conventional data science pipelines lack the required acceleration to handle the large data volumes associated with fraud detection. This leads to slower processing times that hinder real-time dataanalysis and fraud detection capabilities.
The IBM team is even using generative AI to create synthetic data to build more robust and trustworthy AI models and to stand in for real-world data protected by privacy and copyright laws. These systems can evaluate vast amounts of data to uncover trends and patterns, and to make decisions.
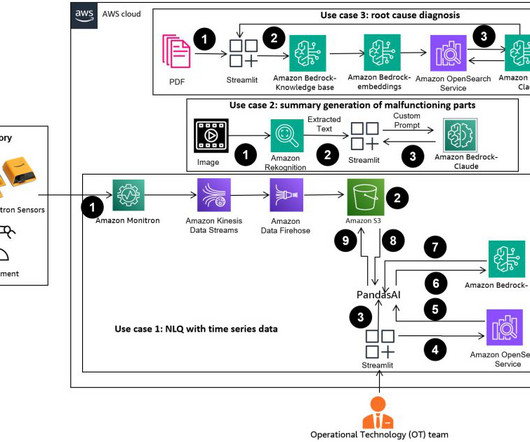
Agents like PandasAI come into play, running this code on high-resolution time series data and handling errors using FMs. PandasAI is a Python library that adds generative AI capabilities to pandas, the popular dataanalysis and manipulation tool. Reformat the Python script, input question, and CSV metadata into a string.
CloudFerro and European Space Agency (ESA) -lab have introduced the first global embeddings dataset for Earth observations, a significant development in geospatial dataanalysis. Data Integration : The embeddings and metadata are compiled into GeoParquet archives, ensuring streamlined access and usability.
Full list of new or updated datasets This dataset joins 33 other new or updated datasets on the Registry of Open Data in four categories: climate and weather, geospatial, life sciences, and machine learning (ML). 94-171) Demonstration Noisy Measurement File from United States Census Bureau What are people doing with open data?
These AI agents have demonstrated remarkable versatility, being able to perform tasks ranging from creative writing and code generation to dataanalysis and decision support. The broker agent determines where to send each message based on its content or metadata, making routing decisions at runtime.
ChromaDB offers several notable features: Efficient vector storage – ChromaDB uses advanced indexing techniques to efficiently store and retrieve high-dimensional vector data, enabling fast similarity searches and nearest neighbor queries. Create a SageMaker endpoint with the BGE Large En v1.5 The producer of this airplane is Airbus.
This not only speeds up content production but also allows human writers to focus on more creative and strategic tasks. - **DataAnalysis and Summarization**: These models can quickly analyze large volumes of data, extract relevant information, and summarize findings in a readable format.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Thus, making it easier for analysts and data scientists to leverage their SQL skills for Big Dataanalysis.
Through automation, you can scale in-demand skillsets, such as model and dataanalysis, introducing and enforcing in-depth analysis of your models at scale across diverse product teams. The second step receives the evaluation and updates the model’s status and metadata based on the values received.
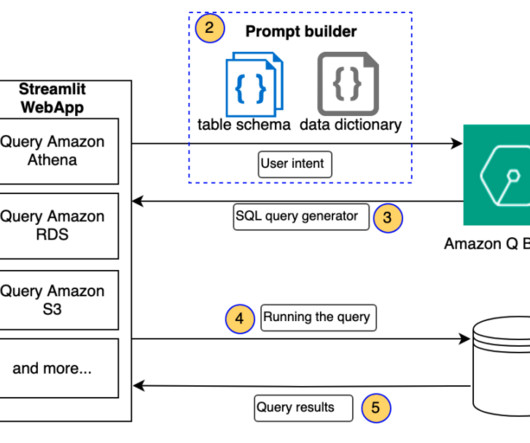
In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business. You can extend this architecture to use additional data sources, query validation, and prompting techniques to cover a wider range of use cases.
Ultimately, Data Blending in Tableau fosters a deeper understanding of data dynamics and drives informed strategic actions. Data Blending in Tableau Data Blending in Tableau is a sophisticated technique pivotal to modern dataanalysis endeavours. What is Data Blending in tableau with an example?
In computer vision datasets, if we can view and compare the images across different views with their relevant metadata and transformations within a single and well-designed UI, we are one step ahead in solving a CV task. Adding image metadata. Locate the “Metadata” section and toggle the dropdown. jpeg').to_pil() jpeg').to_pil()
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation.
Specifically, such dataanalysis can result in predicting trends and public sentiment while also personalizing customer journeys, ultimately leading to more effective marketing and driving business. The chatbot built by AWS GenAIIC would take in this tag data and retrieve insights.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content