This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
IBP brings together various functions, including sales, marketing, finance, supply chain, human resources, IT and beyond to collaborate across business units and make informed decisions that drive overall business success. Data integration and analytics IBP relies on the integration of data from different sources and systems.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The following elements serve as a backbone for a functional data warehouse.
With well-defined schemas, it is ideal for processing and organizing structured data, allowing for sophisticated queries and aggregations. A data warehouse’s essential characteristics are as follows. Projects that need a lot of scalability in order to handle varying data volumes. When to use each?
For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training. In this post, we primarily focus on the zero-shot and few-shot capabilities of LLMs for customer feedback analysis. For more information, refer to Prompt engineering. No explanation is required.
These types of data are historical raw data from an ML perspective. For example, each log is written in the format of timestamp, user ID, and event information. Also, there is static data describing the players such as their age and registration date, which is non-historical data.
Understanding Data Engineering Data engineering is collecting, storing, and organising data so businesses can use it effectively. It involves building systems that move and transform raw data into a usable format. Without data engineering , companies would struggle to analyse information and make informed decisions.
Architecture for data democratization Data democratization requires a move away from traditional “data at rest” architecture, which is meant for storing static data. Traditionally, data was seen as information to be put on reserve, only called upon during customer interactions or executing a program.
Data profiling is a crucial tool. For evaluating data quality. It entails analyzing, cleansing, transforming, and modeling data to find valuable information, improve data quality, and assist in better decision-making, What is Data Profiling? A variety of profiling rules are available for your dataanalysis.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Dataanalysis helps organizations make informed decisions by turning raw data into actionable insights. With businesses increasingly relying on data-driven strategies, the demand for skilled data analysts is rising. You’ll learn the fundamentals of gathering, cleaning, analyzing, and visualizing data.
These tools transform raw data into actionable insights, enabling businesses to make informed decisions, improve operational efficiency, and adapt to market trends effectively. Introduction Business Intelligence (BI) tools are essential for organizations looking to harness data effectively and make informed decisions.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. Section 4: Reporting data for the project insights. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load.
This flexibility allows organizations to store vast amounts of raw data without the need for extensive preprocessing, providing a comprehensive view of information. Centralized Data Repository Data Lakes serve as a centralized repository, consolidating data from different sources within an organization.
Summary: Understanding Business Intelligence Architecture is essential for organizations seeking to harness data effectively. This framework includes components like data sources, integration, storage, analysis, visualization, and information delivery.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Business Intelligence (BI) refers to the technology, techniques, and practises that are used to gather, evaluate, and present information about an organisation in order to assist decision-making and generate effective administrative action. Based on the report of Zion Research, the global market of Business Intelligence rose from $16.33
They all agree that a Datamart is a subject-oriented subset of a data warehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for dataanalysis, not the full history of data.
This role is vital for data-driven organizations seeking competitive advantages. Introduction We are living in an era defined by data. From customer interactions to market trends, every aspect of business generates a wealth of information. Essentially, BI bridges the gap between raw data and actionable knowledge.
Eight prominent concepts stand out: Customer Data Platforms (CDPs), Master Data Management (MDM), Data Lakes, Data Warehouses, Data Lakehouses, Data Marts, Feature Stores, and Enterprise Resource Planning (ERP). Pros: Data Consistency: Ensures consistent and accurate data across the organization.
By integrating AI capabilities, Excel can now automate DataAnalysis, generate insights, and even create visualisations with minimal human intervention. AI-powered features in Excel enable users to make data-driven decisions more efficiently, saving time and effort while uncovering valuable insights hidden within large datasets.
The blog also presents popular data analytics courses, emphasizing their curriculum, learning methods, certification opportunities, and benefits to help aspiring Data Analysts choose the proper training for their career advancement. Describe a challenging problem you encountered during a dataanalysis project and how you solved it.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Thus, making it easier for analysts and data scientists to leverage their SQL skills for Big Dataanalysis.
It relates to employing algorithms to find and examine data patterns to forecast future events. Through practice, machines pick up information or skills (or data). Deep learning is a branch of machine learning frequently used with text, audio, visual, or photographic data. Built to use predictive models.
This addition enhances data accessibility and management within your development environment. or lower) or in a custom environment, refer to appendix for more information. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas.
It involves developing data pipelines that efficiently transport data from various sources to storage solutions and analytical tools. The goal is to ensure that data is available, reliable, and accessible for analysis, ultimately driving insights and informed decision-making within organisations.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. It supports both batch and real-time processing.
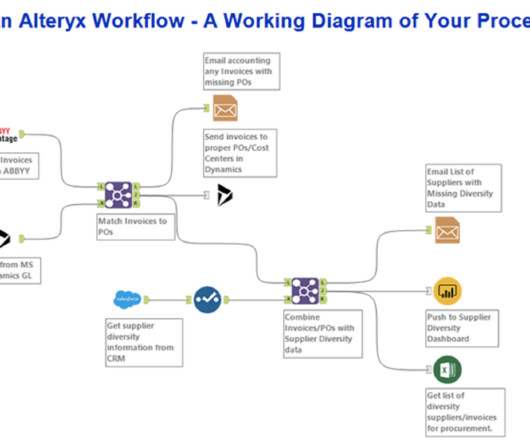
Unleash the potential of Alteryx certification to transform your data workflows and make informed, data-driven decisions. Alteryx: A comprehensive guide Alteryx stands as a robust data analytics and visualization platform. Streamlined Data Integration Alteryx redefines the way organizations handle data integration.
Improved Data Navigation Hierarchies provide a clear structure for users to navigate through data. This allows for intuitive querying and reporting, making it easier for users to find the information they need. Enhanced DataAnalysis By allowing users to drill down into data, hierarchies enable more detailed analysis.
In this blog, well explore the 5 key components of Power BI , their features, and how they can help you make data-driven decisions. Key Takeaways User-Friendly Interface: Simplifies dataanalysis for non-technical users. Key Features Data Import: Connects to multiple data sources like Excel, SQL Server, or cloud services.
Use Cases of Hadoop Hadoop is widely used in finance, healthcare, and retail industries for fraud detection, risk analysis, customer segmentation, and large-scale data storage. It also supports ETL (Extract, Transform, Load) processes, making data warehousing and analytics essential. What is Apache Spark?
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries.
From the above, you can see how Data Warehousing has grown crucial for large and medium-sized enterprises. Data Warehouse facilitates the team’s access to data and helps them draw conclusions from the information and merge data from many sources. It expedites access to helpful information in this way.
Its core components include: Lakehouse : Offers robust data storage and processing capabilities. Data Factory : Simplifies the creation of ETL pipelines to integrate data from diverse sources. Developed by Microsoft, it is designed to simplify DataAnalysis for users at all levels, from beginners to advanced analysts.
This week, I will cover why I think data janitor work is dying and companies that are built in on top of data janitor work could be ripe for disruption through LLMs and what to do about it. A data janitor is a person who works to take big data and condense it into useful amounts of information.
You can take a look at the upper half of the diagram above to see how these intersections end up on a scale that goes from 1 (an organization completely immature in terms of data adoption) to 5 (an organization completely mature, professional and advanced in terms of data adoption). 3 The SQS queues were messy to maintain.
Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy. Introduction Are you a Python enthusiast looking to import data into your code with ease?
However, it was inflexible and could not handle many-to-many relationships or complex relationships between data, which limited its use in more complex applications. Hierarchical databases, such as IBM’s Information Management System (IMS), were widely used in early mainframe database management systems.
Instead, flexible open-source programming languages and public data repositories are empowering anyone to experiment, build models, and question through data. Students, academics, startupsall levels now avail equal resources to mine information forgood. This allows iterative dataanalysis workflows rather than rigid scripts.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. I’ll show you best practices for using Jupyter Notebooks for exploratory dataanalysis. When data science was sexy , notebooks weren’t a thing yet.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
Dataanalysis helps organizations make informed decisions by turning raw data into actionable insights. With businesses increasingly relying on data-driven strategies, the demand for skilled data analysts is rising. You’ll learn the fundamentals of gathering, cleaning, analyzing, and visualizing data.
Focused on addressing the challenge of agricultural data standardization, Agmatix has developed proprietary patented technology to harmonize and standardize data, facilitating informed decision-making in agriculture. Most companies are unable to use their field trial data based on manual processes and disparate systems.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content