This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process begins with data ingestion and preprocessing, where prescriptive AI gathers information from different sources, such as IoT sensors, databases, and customer feedback. It organizes it by filtering out irrelevant details and ensuring dataquality. Another advantage is the improvement in operational efficiency.
Can you explain the core concept and what motivated you to tackle this specific challenge in AI and data analytics? In 2021, despite the fact that generative AI semantic models have existed since 2017, and graph neural nets have existed for even longer, it was a tough task to explain to VCs why we need automated context and reasoning.
While traditional AI tools might excel at specific tasks or dataanalysis, AI agents can integrate multiple capabilities to navigate complex, dynamic environments and solve multifaceted problems. Model Interpretation and Explainability: Many AI models, especially deep learning models, are often seen as black boxes.
Introduction Are you struggling to decide between data-driven practices and AI-driven strategies for your business? Besides, there is a balance between the precision of traditional dataanalysis and the innovative potential of explainable artificial intelligence.
Summary: DataAnalysis and interpretation work together to extract insights from raw data. Analysis finds patterns, while interpretation explains their meaning in real life. Introduction DataAnalysis and interpretation are key steps in understanding and making sense of data.
Regulatory compliance By integrating the extracted insights and recommendations into clinical trial management systems and EHRs, this approach facilitates compliance with regulatory requirements for data capture, adverse event reporting, and trial monitoring.
Dr. Tomic highlighted how AI is transforming education, making coding and dataanalysis more accessible but also raising new challenges. Historically, data analysts were required to write SQL queries or scripts in Python to extract insights. Gary explained that this shift inverts the traditional analytics pyramid.
This shift marks a pivotal moment in the industry, with AI set to revolutionize various aspects of QE, from test automation to dataquality management. DataQuality: The Foundation for AI-Driven Testing As organizations become more reliant on data-driven decision-making, the quality of their data takes on heightened importance.
Risk of data swamps A data swamp is the result of a poorly managed data lake that lacks appropriate dataquality and data governance practices to provide insightful learnings, rendering the data useless. Map a data framework –When you achieve full data democratization, what will that look like?
There are many well-known libraries and platforms for dataanalysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. These tools will help make your initial data exploration process easy.
If the test or validation data distribution has too much deviance from the training data distribution, then we must go for retraining since it is a sign of population drift. Model Interpretability and Explainability Model interpretability and explainability describe how a machine learning model arrives at its predictions or decisions.
Characteristics of a Good Measure of Dispersion A good measure of dispersion helps us understand how the values in a data set are spread out. Here are the crucial characteristics explained in simple terms: Easy to calculate and understand : Anyone should be able to use it without complex math. Not suitable for full dataanalysis.
Unlike supervised learning, where the algorithm is trained on labeled data, unsupervised learning allows algorithms to autonomously identify hidden structures and relationships within data. These algorithms can identify natural clusters or associations within the data, providing valuable insights for demand forecasting.
We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations. Finally, we show how to export the data flow and train a model using SageMaker Autopilot. Data Wrangler creates the report from the sampled data.
Common Applications: Real-time monitoring systems Basic customer service chatbots DigitalOcean explains that while these agents may not handle complex decision-making, their speed and simplicity are well-suited for specific uses. DataQuality and Bias: The effectiveness of AI agents depends on the quality of the data they are trained on.
Exploratory dataanalysis After you import your data, Canvas allows you to explore and analyze it, before building predictive models. You can preview your imported data and visualize the distribution of different features. This information can be used to refine your input data and drive more accurate models.
AI users say that AI programming (66%) and dataanalysis (59%) are the most needed skills. Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% Developers are learning how to find qualitydata and build models that work. Many AI adopters are still in the early stages.
Top 50+ Interview Questions for Data Analysts Technical Questions SQL Queries What is SQL, and why is it necessary for dataanalysis? SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. Explain the difference between a bar chart and a histogram.
Businesses must understand how to implement AI in their analysis to reap the full benefits of this technology. In the following sections, we will explore how AI shapes the world of financial dataanalysis and address potential challenges and solutions.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, dataanalysis, data cleaning, and data visualization. It facilitates exploratory DataAnalysis and provides quick insights.
If your dataset is not in time order (time consistency is required for accurate Time Series projects), DataRobot can fix those gaps using the DataRobot Data Prep tool , a no-code tool that will get your data ready for Time Series forecasting. Prepare your data for Time Series Forecasting. Perform exploratory dataanalysis.
Let’s explore some key challenges: Data Infrastructure Limitations Small-scale DataAnalysis tools like Excel might suffice for basic tasks. But as data volume and complexity increase, traditional infrastructure struggles to keep up.
Summary: Statistical Modeling is essential for DataAnalysis, helping organisations predict outcomes and understand relationships between variables. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informed decisions. Below are the essential steps involved in the process.
Data Processing Data processing involves cleaning, transforming, and organizing the collected data to prepare it for analysis. This step is crucial for eliminating inconsistencies and ensuring data integrity. DataAnalysisDataanalysis is the heart of deriving insights from the gathered information.
Enter predictive modeling , a powerful tool that harnesses the power of data to anticipate what tomorrow may hold. Predictive modeling is a statistical technique that uses DataAnalysis to make informed forecasts about future events. Incomplete, inaccurate, or biased data can lead to skewed or misleading results.
Moreover, the traditional mindset and organizational culture that prioritize gut instincts and experience over data-driven insights is something you will always have to fight. However, beware of bad data. Under normal circumstances, dataquality may seem like an afterthought, something for the IT guys to worry about.
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. We explain the metrics and show techniques to deal with data to obtain better model performance. Quick model is useful when iterating to more quickly understand the impact of data changes to your model accuracy.
The Tangent Information Modeler, Time Series Modeling Reinvented Philip Wauters | Customer Success Manager and Value Engineer | Tangent Works Existing techniques for modeling time series data face limitations in scalability, agility, explainability, and accuracy. Check them out for free!
Every piece of data adds to the picture, providing insights that can lead to innovation and efficiency. Among these puzzle pieces, marketing data stands out as a valuable component. On the technical front, handling large volumes of data and integrating disparate data sources can pose significant challenges.
The field demands a unique combination of computational skills and biological knowledge, making it a perfect match for individuals with a data science and machine learning background. Developing robust data integration and harmonization methods is essential to derive meaningful insights from heterogeneous datasets.
Explainable AI As ANNs are increasingly used in critical applications, such as healthcare and finance, the need for transparency and interpretability has become paramount. Explainable AI (XAI) aims to provide insights into how neural networks make decisions, helping stakeholders understand the reasoning behind predictions and classifications.
OpenAI has wrote another blog post around dataanalysis capabilities of the ChatGPT. It has a number of neat capabilities that are supported by interactively and iteratively: File Integration Users can directly upload data files from cloud storage services like Google Drive and Microsoft OneDrive into ChatGPT for analysis.
The systems must be explainable, fair, and aligned with ethical standards for stakeholders to rely on AI. Building Explainable and Interpretable AI Systems Explainability enables users to understand how AI systems make decisions. Explainability fosters transparency, helping users trust the systems logic and reasoning.
Read More: Use of Excel in DataAnalysis Key Takeaways Streamlined Data Entry: Dropdown lists make data entry faster and more efficient for users. Data Integrity: They help maintain accurate and consistent data entries. This uniformity is essential for accurate dataanalysis and reporting.
City’s pulse (quality and density of the points of interest). The great thing about DataRobot Explainable AI is that it spans the entire platform. You can understand the data and model’s behavior at any time. Understand & Explain Models with DataRobot Trusted AI. Global Explainability.
Image from "Big Data Analytics Methods" by Peter Ghavami Here are some critical contributions of data scientists and machine learning engineers in health informatics: DataAnalysis and Visualization: Data scientists and machine learning engineers are skilled in analyzing large, complex healthcare datasets.
Diagnostic Analytics Diagnostic analytics goes a step further by explaining why certain events occurred. It uses data mining , correlations, and statistical analyses to investigate the causes behind past outcomes. DataQuality Issues Inaccurate, incomplete, or outdated data can lead to flawed analyses.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, data preparation, and algorithm selection. Dataquality significantly impacts model performance.
HDFS (Hadoop Distributed File System) stores data across multiple machines, ensuring scalability and fault tolerance. The NameNode manages metadata and keeps track of data blocks stored in the DataNodes within HDFS. Explain the Term MapReduce. Explain the Role of Apache HBase. What is the Role of Zookeeper in Big Data?
This will only worsen, and companies must learn to adapt their models to unique, content-rich data sources. Model improvements in the future wont come from brute force and more data; they will come from better dataquality, more context, and the refinement of underlying techniques.
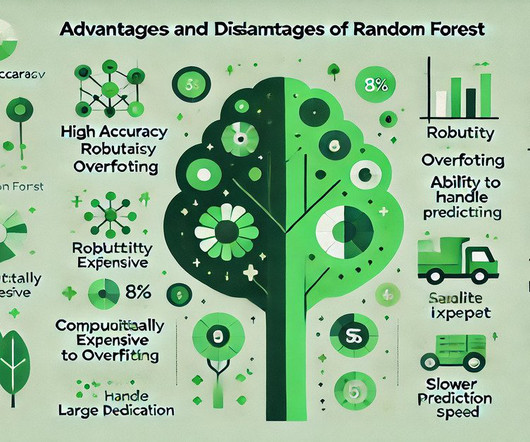
Understanding these pros and cons will help you decide when to effectively utilise Random Forest in your DataAnalysis projects. Handles Missing Data Effectively Random Forest can handle missing data without imputation, which is particularly beneficial in real-world datasets with common missing values.
However, it’s important to note that the context provided also discusses other key aspects of data science, such as Veracity, which deals with the trustworthiness or usefulness of results obtained from dataanalysis, and the challenges faced in Big Data Analytics, including dataquality, validation, and scalability of algorithms.
Determine which systems impact EU patients or process EU health data Next, determine which systems impact EU patients or process EU health data. Provide clear explanations of how AI systems work and what data they use Next, provide clear, understandable explanations of how these AI systems work.
Beyond Interpretability: An Interdisciplinary Approach to Communicate Machine Learning Outcomes Merve Alanyali, PhD | Head of Data Science Research and Academic Partnerships | Allianz Personal Explainable AI (XAI) is one of the hottest topics among AI researchers and practitioners. billion customer interactions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content