This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ETL ( Extract, Transform, Load ) Pipeline: It is a data integration mechanism responsible for extracting data from data sources, transforming it into a suitable format, and loading it into the data destination like a data warehouse. The pipeline ensures correct, complete, and consistent data.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. There are 16 files that include product description and metadata of Amazon products in the format of listings/metadata/listings_.json.gz. We use the first metadata file in this demo.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. It applies the data structure during querying rather than dataingestion. Why Do We Need Hadoop Hive?
Preceded by dataanalysis and feature engineering, a model is trained and ready to be productionized. We may observe a growing awareness among machine learning and data science practitioners of the crucial role played by pre- and post-training activities. But what happens next? This triggers a bunch of quality checks (e.g.
In addition, it also defines the framework wherein it is decided what action needs to be taken on certain data. And so, a company dealing in Big DataAnalysis needs to follow stringent Data Governance policies. It can include data refresh cadences, PII limitations, regulatory data regulations, or even data access.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Dataingestion (extraction and versioning). Data validation (writing tests to check for data quality). Data preprocessing. Let’s briefly go over each of the components below. CSV, Parquet, etc.)
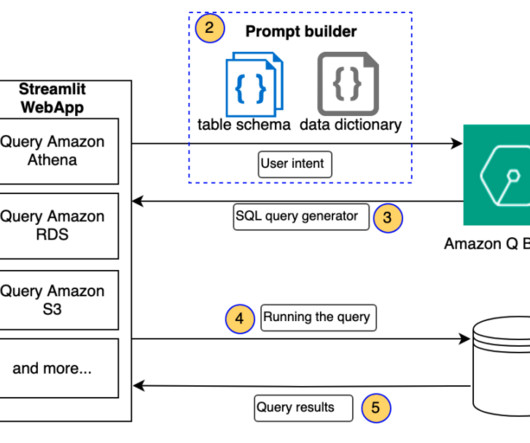
In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business. You can extend this architecture to use additional data sources, query validation, and prompting techniques to cover a wider range of use cases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content