This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On Thursday, Google and the Computer History Museum (CHM) jointly released the source code for AlexNet , the convolutionalneuralnetwork (CNN) that many credit with transforming the AI field in 2012 by proving that "deeplearning" could achieve things conventional AI techniques could not.
Project Structure Accelerating ConvolutionalNeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating ConvolutionalNeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
In this tutorial, we explore an innovative and practical application of IBM’s open-source ResNet-50 deeplearning model, showcasing its capability to classify satellite imagery for disaster management rapidly.
We download the documents and store them under a samples folder locally. Load data We use example research papers from arXiv to demonstrate the capability outlined here. arXiv is a free distribution service and an open-access archive for nearly 2.4 samples/2003.10304/page_0.png'
Home Table of Contents Faster R-CNNs Object Detection and DeepLearning Measuring Object Detector Performance From Where Do the Ground-Truth Examples Come? One of the most popular deeplearning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al.
The Rise of CUDA-Accelerated AI Frameworks GPU-accelerated deeplearning has been fueled by the development of popular AI frameworks that leverage CUDA for efficient computation. NVIDIA TensorRT , a high-performance deeplearning inference optimizer and runtime, plays a vital role in accelerating LLM inference on CUDA-enabled GPUs.
Image recognition with deeplearning is a key application of AI vision and is used to power a wide range of real-world use cases today. I n past years, machine learning, in particular deeplearning technology , has achieved big successes in many computer vision and image understanding tasks.
Home Table of Contents Deploying a Vision Transformer DeepLearning Model with FastAPI in Python What Is FastAPI? You’ll learn how to structure your project for efficient model serving, implement robust testing strategies with PyTest, and manage dependencies to ensure a smooth deployment process. Testing main.py Testing main.py
Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g., If you are a regular PyImageSearch reader and have even basic knowledge of DeepLearning in Computer Vision, then this tutorial should be easy to understand. tomato, brinjal, and bottle gourd).
Starting with the input image , which has 3 color channels, the authors employ a standard ConvolutionalNeuralNetwork (CNN) to create a lower-resolution activation map. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? That’s not the case.
Firstly, YOLOv8 introduces a new backbone network, Darknet-53, which is significantly faster and more accurate than the previous backbone used in YOLOv7. DarkNet-53 is a convolutionalneuralnetwork that is 53 layers deep and can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals.
Object detection works by using machine learning or deeplearning models that learn from many examples of images with objects and their labels. In the early days of machine learning, this was often done manually, with researchers defining features (e.g., Object detection is useful for many applications (e.g.,
OpenCV Android can be downloaded and set up in Android by the following steps. Download Android release of OpenCV from [link] ; Extract it and move the subfolder OpenCV-android-sdk under it into app/src/main/cpp in the image classification app that we are making; Set OpenCV_DIR in app/src/main/cpp/CMakeLists.txt. f, 0.4822f*255.f,
You can access these resources on the website or in the downloadable program. DeepConvolutionalNeuralNetworks (DCNN) trained on millions of photos power VanceAI’s A.I. VanceAI uses deeplearning to its full potential because its method is distinct from tools based on traditional mathematical procedures.
AI vs. Machine Learning vs. DeepLearning First, it is important to gain a clear understanding of the basic concepts of artificial intelligence types. We often find the terms Artificial Intelligence and Machine Learning or DeepLearning being used interchangeably. Get the Whitepaper or a Demo.
GCNs use a combination of graph-based representations and convolutionalneuralnetworks to analyze large amounts of textual data. A GCN consists of multiple layers, each of which applies a graph convolution operation to the input graph. Download the Cora dataset here.
The process of diagnosis is not easy and requires some medical laboratory tools and advanced medical skill, but we can use deeplearning and computer vision to build a fast and easy tool that will help doctors be able to detect pneumonia. The core of our model will be a pre-trained convolutionalneuralnetwork (CNN) named VGG16.
item() print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total)) # Save the Trained Model torch.save(model.state_dict(), 'image_classifier.pt') Upon reviewing the PyTorch code generated by Gemini Pro for image classification, it generally aligns well with best practices and shows a structured approach.
Single-threaded In the JavaScript library, single threads download synchronously, which might throttle performance. Automatic Picture Manipulation: auto-adjust images based on a predefined rule-set using a browser-based application — even generate art using convolutionalneuralnetworks , as Google has done. And in Node.js
Diabetic Retinopathy Diagnosis Doctors are successfully leveraging deeplearning to automate the diagnosis of diabetic retinopathy : a complication associated with diabetes that can cause blindness. The technology uses convolutionalneuralnetworks to indicate likely issues on a patient’s retina, boasting accuracy levels of 92.3%
ZenDNN ZenDNN, which is available open-source from GitHub , is a low-level AMD deepneuralnetwork library that includes basic neuralnetwork building blocks optimized for AMD EPYC CPUs. Download ZenDNN Plug-in CPU wheel file from the TensorFlow Community Supported Builds webpage. manylinux2014_x86_64.whl
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Network Intrusion Detection: In cybersecurity, anomaly detection is used to identify potential network intrusions. Looking for the source code to this post? for 3000+ credit card transactions.
Viso Suite is the end-to-end, No-Code Computer Vision Platform for Businesses – Learn more What is YOLO You Only Look Once (YOLO) is an object-detection algorithm introduced in 2015 in a research paper by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. The essential mechanics of an object detection model – source.
This model is deployed using the text-generation-inference (TGI) deeplearning container. This not only helps you learn new words but also enhances your understanding of their subtle differences in meaning. Word-a-day calendars or apps: Subscribe to a word-a-day email or download a vocabulary-building app.
Jump Right To The Downloads Section Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series Introduction Image segmentation is a pivotal task in computer vision where each pixel in an image is assigned a specific label, effectively dividing the image into distinct regions. Looking for the source code to this post?
The research engineers at DeepMind including well known AI researcher and author of the book Grokking DeepLearning , Andrew Trask have published an impressive paper on a neuralnetwork model that can learn simple to complex numerical functions with great extrapolation (generalisation) ability.
We use our model (shown as CNN (convolutionalneuralnetwork) in Figure 1 ) to compute the feature embedding corresponding to each face in our database (i.e., , , , ) and store the embedding in our database as shown. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated?
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This list will consist of Machine learning projects, DeepLearning Projects, Computer Vision Projects , and all other types of interesting projects with source codes also provided. This is a simple project.
Those models are based on convolutionalneuralnetworks (CNNs) which are a popular type of artificial neuralnetworks (ANNs) that work great for vision tasks like classification and detection. Train Model We will first start by downloading the YOLOv5 repository and install the needed libraries. !git
The raw model weights are downloadable from the documentation and on GitHub. The concept of a transformer, an attention-layer-based, sequence-to-sequence (“Seq2Seq”) encoder-decoder architecture, was conceived in a 2017 paper authored by pioneer in deeplearning models Ashish Vaswani et al called “Attention Is All You Need”.
In supervised learning, the model is trained on data with labels, where a neuralnetwork can learn relationships between the images and their depth maps, and make predictions based on the learned relationships. Researchers widely use convolutionalneuralnetworks (CNNs).
This is a guest post from Andrew Ferlitsch, author of DeepLearning Patterns and Practices. It provides an introduction to deepneuralnetworks in Python. Andrew is an expert on computer vision, deeplearning, and operationalizing ML in production at Google Cloud AI Developer Relations.
Download the dataset, and let's get started! pip install opendatasets # to help download data directly from Kaggle import opendatasets as od # download # Kaggle API key required od.download("[link] Visualizing the Dataset With Kangas Kangas comes in handy for visualizing multimedia data.
s2v_most_similar(3) # [(('machine learning', 'NOUN'), 0.8986967), # (('computer vision', 'NOUN'), 0.8636297), # (('deeplearning', 'NOUN'), 0.8573361)] Evaluating the vectors Word vectors are often evaluated with a mix of small quantitative test sets , and informal qualitative review. ._.s2v_freq vector = doc[3:6]._.s2v_vec
Going Beyond with Keras Core The Power of Keras Core: Expanding Your DeepLearning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup Data Pipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? What Is Keras Core?
Step 1: Getting Dataset and Heading to Notebook To download the dataset used in this project, visit this link to Kaggle, register (if you are not a member), and download: NB: The dataset is originally found in the Tensorflow Utils datasets. A high value will not be suitable for a convolutionalneuralnetwork.
Instead of complex and sequential architectures like Recurrent NeuralNetworks (RNNs) or ConvolutionalNeuralNetworks (CNNs), the Transformer model introduced the concept of attention, which essentially meant focusing on different parts of the input text depending on the context. How Are LLMs Used?
Solution overview For an introduction to MMEs and MMEs with GPU, refer to Create a Multi-Model Endpoint and Run multiple deeplearning models on GPU with Amazon SageMaker multi-model endpoints. The impact is more for models using a convolutionalneuralnetwork (CNN). Deploy a SageMaker MME on a GPU instance.
But how can we harness machine learning for something as niche as rice classification? Well, this is where PyTorch, a powerful deeplearning library, steps in. Today, I’ll guide you through creating a ConvolutionalNeuralNetwork (CNN) using PyTorch to classify rice varieties based on images.
Viso Suite, the all-in-one computer vision solution The journey of AI in art traces back to the development of neuralnetworks and deeplearning technologies. And, Generative Adversarial Networks (GANs) , which opened new doors for generating high-quality, realistic images.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























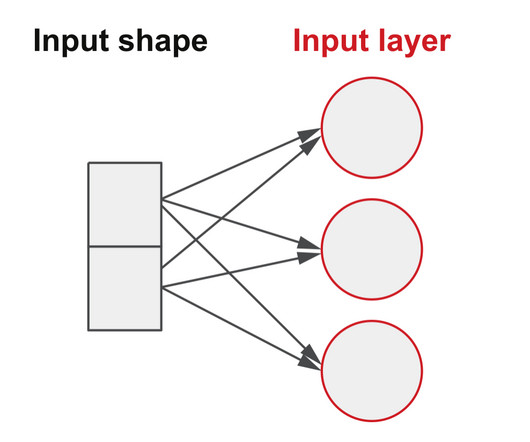





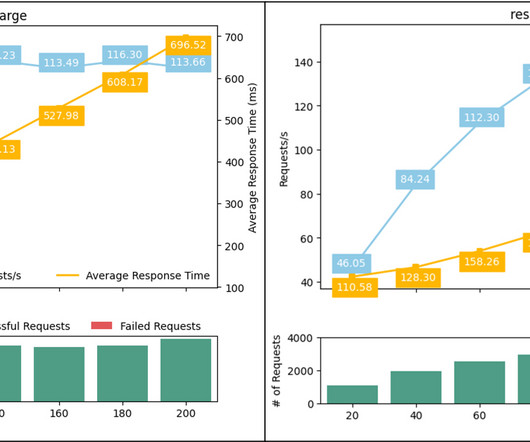








Let's personalize your content