This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
TL;DR: In many machine-learning projects, the model has to frequently be retrained to adapt to changing data or to personalize it. Continuallearning is a set of approaches to train machine learning models incrementally, using data samples only once as they arrive. What is continuallearning?
Building a robust data foundation is critical, as the underlying data model with proper metadata, data quality, and governance is key to enabling AI to achieve peak efficiencies. There are three areas of AI in particular that will always require human involvement to achieve optimal outcomes. Building a strong data foundation.
The ultimate goal of the SEER model is to help in developing strategies for the pre-training process that use uncurated data to deliver top-notch state of the art performance in transfer learning. However, this approach needs to filter images, and it works best only when a textual metadata is present.
Most available datasets either lack the temporal metadata necessary for time-based splits or come from less extensive data acquisition and feature engineering pipelines compared to common industry ML practices. This can influence the types and amounts of predictive, uninformative, and correlated features, impacting model selection.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
Current research explores techniques like sliding windows and “small2big” methods Metadata Integration Information like dates, purpose, chapter summaries, etc. This improves the retriever efficiency by not only searching the documents but also by assessing the similarity to the metadata. It is like a continuouslearning process.
We continuouslylearn from patterns that work and quickly integrate those insights, providing users with a powerful, intuitive tool for managing and leveraging their data. How is data.world investing in research and development to stay at the forefront of AI and data integration technologies?
To learn about these possibilities and more, refer to the Amazon Kendra Developer Guide. Senthil’s area of interest is AI, especially Deep Learning and Machine Learning. He focuses on application automations with continuouslearning and improving human enterprise experience.
And with the latest release of O’Reilly Answers, the idea of a royalties engine that fairly pays creators is now a practical day-to-day reality—and core to the success of the two organizations’ partnership and continued growth together.
This is done on the features that security vendors might sign, starting from hardcoded strings, IP/domain names of C&C servers, registry keys, file paths, metadata, or even mutexes, certificates, offsets, as well as file extensions that are correlated to the encrypted files by ransomware.
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. Before you can enable invocation logging, you need to set up an Amazon Simple Storage Service (Amazon S3) or CloudWatch Logs destination.
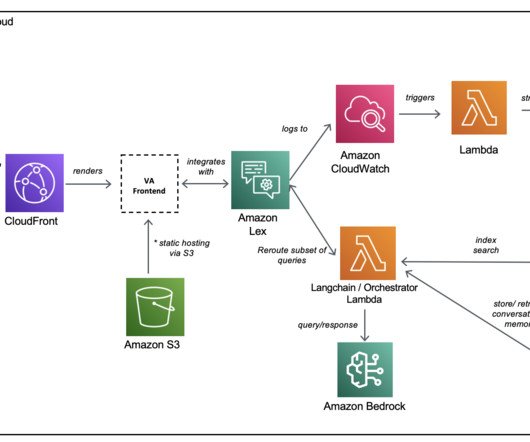
Metadata about the request/response pairings are logged to Amazon CloudWatch. Online reporting The online reporting process consists of the following steps: End-users interact with the chatbot via a CloudFront CDN front-end layer.
The features are constructed and managed as a metadata-only “ghost cache” (similar to classical policies like ARC ). tracking and updating feature metadata in a capacity-constrained key-value store) needed to update the dynamic internal representation.
Foster continuouslearning – In the early stages of our generative AI journey, we encouraged our teams to experiment and build prototypes across various domains. LLMs had demonstrated exceptional performance in tasks such as text summarization and generation, which aligned perfectly with the requirements of Account Summaries.
The solution captures speaker audio and metadata directly from your browser-based meeting application (currently compatible with Zoom and Chime, with others coming), and audio from other browser-based meeting tools, softphones, or other audio input.
d) Hypernetwork: A small separate neural network generates modular parameters conditioned on metadata. Instead of learning module parameters directly, they can be generated using an auxiliary model (a hypernetwork) conditioned on additional information and metadata. Continuallearning. During
They believe we have to continuouslylearn and adapt by deploying less powerful versions of the technology in order to minimize “one shot to get it right” scenarios. The schema is from schema.org and more details on the metadata and structure is here. They want to successfully navigate massive risks.
Monitor its performance and continue to refine its behavior based on user feedback. Continuouslearning: Allow the chatbot to continuelearning and improving its behavior over time by incorporating feedback and adjusting its policies based on user interactions.
Applying consistent semantic standards and metadata makes governance scalable. Shafeeq is passionate about advancing data science, fostering continuouslearning, and translating data into actionable insights.
Create data dictionaries and metadata repositories to help users understand the data’s structure and context. Regularly monitor and report on these metrics to ensure continuous improvement. Predictive Data Quality Use machine learning to predict data quality issues before they occur, allowing proactive corrections.
ContinuousLearning Commitment to staying updated on industry trends and emerging technologies. billion 15.83% Metadata-Driven Data Fabric Systematic data management efficiency. by 2030 Edge Computing Reducing latency and fostering continuous operations. billion Value by 2030 – $125.64 Value in 2024 – $305.90
Include additional information like publication dates, authors, and metadata to help users assess the relevance of each result. ContinuousLearning and Adaptation Update the index and ranking algorithms as new documents are added to the collection.
Continuouslearning and improvement As more data is processed, the LLM can continuouslylearn and refine its recommendations, improving its performance over time. You will notice the content of this file as JSON with a text transcript available under the key transcripts, along with other metadata.
The features extracted for this tabular representation can come directly from images using image recognition and detection tools, or from existing metadata like captions, or a combination of both. Further analysis of the extracted tabular data reveals different ways to assess potential bias.
Metadata for Transparency: C2PA metadata (identifying AI-generated content) will be included in future deployments. To continuelearning about the world of AI, check out our other blogs: How to Detect AI-Generated Content Guide to Generative Adversarial Networks (GANs) Ethics in AI: What Happened With Sam Altman and OpenAI?
This post explores how 123RF used Amazon Bedrock, Anthropic’s Claude 3 Haiku, and a vector store to efficiently translate content metadata, significantly reduce costs, and improve their global content discovery capabilities. Metadata such as the content type, domain, and any relevant tags. The corresponding translation chunk.
Be sure to check out his talk, Adaptive RAG Systems with Knowledge Graphs: Building Reinforcement-Learning-Driven AI Applications , there! Imagine an AI assistant that doesnt just answer your questionsit understands the deeper context, adapts in real time, and continuouslylearns from interactions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content