This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
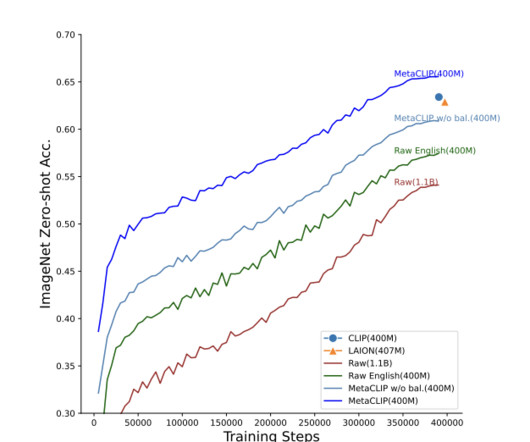
Despite advances in image and text-based AI research, the audio domain lags due to the absence of comprehensive datasets comparable to those available for computervision or natural language processing. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
The SEER model by Facebook AI aims at maximizing the capabilities of self-supervised learning in the field of computervision. The Need for Self-Supervised Learning in ComputerVision Data annotation or data labeling is a pre-processing stage in the development of machine learning & artificial intelligence models.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
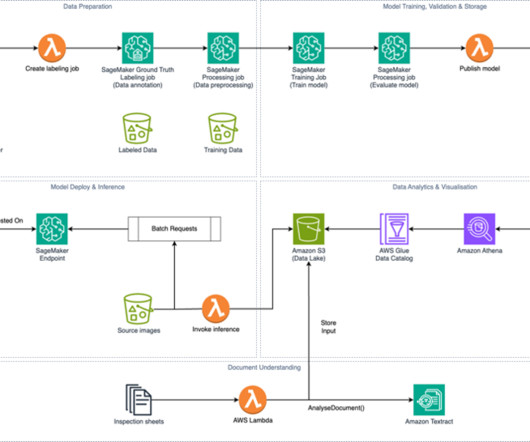
Specifically, we cover the computervision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. The resulting dashboard highlighted that 141 power pole assets required action, out of a network of 57,230 poles.
Our goal – and our biggest challenge – is to be the leader in our field, and one of our key advantages in this technology-driven market is Cipia’s extensive experience with computervision and AI. Those are just a few of the dozens of features enabled by computervision AI that would enhance the driving experience.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Model Manifests: Metadata files describing the models architecture, hyperparameters, and version details, helping with integration and version tracking. Vision model with ollama pull llama3.2-vision vision , Ollama downloads and stores both the model blobs and manifests in the ~/.ollama/models Join me in computervision mastery.
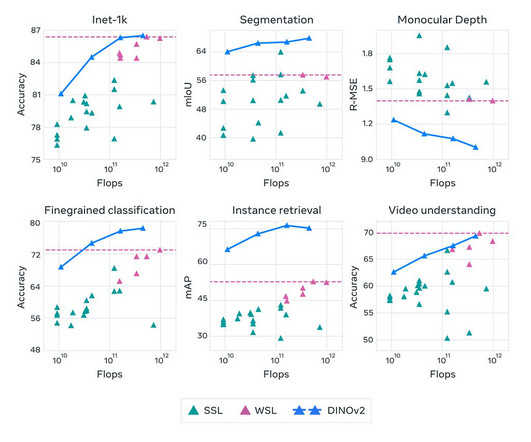
Building disruptive ComputerVision applications with No Fine-Tuning Imagine a world where computervision models could learn from any set of images without relying on labels or fine-tuning. Understanding DINOv2 DINOv2 is a cutting-edge method for training computervision models using self-supervised learning.
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite. What is TensorFlow?
In recent years, advances in computervision have enabled researchers, first responders, and governments to tackle the challenging problem of processing global satellite imagery to understand our planet and our impact on it. This ID will identify the image for its entire lifecycle.
In academic research, particularly in computervision, keeping track of conference papers can be a real challenge. Unlike journal articles, conference papers often lack easily accessible metadata such as DOI or ISBN, making them harder to find and cite. We found this tool being featured on reddit.
You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. You can apply filters to your retrievals, instructing the vector store to pre-filter based on document metadata and then search for relevant documents. Reranking allows GraphRAG to refine and optimize search results.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
product specifications, movie metadata, documents, etc.) Course information: 86 total classes 115+ hours of on-demand code walkthrough videos Last updated: October 2024 4.84 (128 Ratings) 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computervision and deep learning.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. He focuses on Deep learning including NLP and ComputerVision domains.
Deliver new insights Expert systems can be trained on a corpus—metadata used to train a machine learning model—to emulate the human decision-making process and apply this expertise to solve complex problems. Computervision guides self-driving cars.
These are all stoves, even if your typical computervision system wouldn’t always know it: These are all stoves, but today’s machine learning systems would likely struggle to recognize them as such. They then mapped Dollar Street’s metadata to categories in ImageNet and tested the neural networks against the new data set.
The funding will allow ApertureData to scale its operations and launch its new cloud-based service, ApertureDB Cloud, a tool designed to simplify and accelerate the management of multimodal data, which includes images, videos, text, and related metadata. ApertureData’s flagship product, ApertureDB , addresses this challenge head-on.
In recent years, there have been exceptional advancements in Artificial Intelligence, with many new advanced models being introduced, especially in NLP and ComputerVision. It has helped advance numerous computervision research and has supported modern recognition systems and generative models.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. She has expertise in Machine Learning, covering natural language processing, computervision, and time-series analysis.
Understanding the DINOv2 Model, its Advantages, and its Applications in ComputerVision Introduction : Meta AI, has recently open-sourced DINOv2, a self-supervised learning method for training computervision models. References: Meta AI Blog BECOME a WRITER at MLearning.ai
Bias detection in ComputerVision (CV) aims to find and eliminate unfair biases that can lead to inaccurate or discriminatory outputs from computervision systems. Computervision has achieved remarkable results, especially in recent years, outperforming humans in most tasks. Let’s get started.
Examples include financial systems processing transaction data streams, recommendation engines processing user activity data, and computervision models processing video frames. Publish the BYOC image to Amazon ECR Create a script named model_quality_monitoring.py
In computervision datasets, if we can view and compare the images across different views with their relevant metadata and transformations within a single and well-designed UI, we are one step ahead in solving a CV task. Adding image metadata. Locate the “Metadata” section and toggle the dropdown. jpeg').to_pil()
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. TensorFlow on Google Cloud This course covers designing TensorFlow input data pipelines and building ML models with TensorFlow and Keras.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. Mani Khanuja is a Tech Lead Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computervision , natural language processing , and more. NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT.
It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements. Metadata customization for.csv files Knowledge Bases for Amazon Bedrock now offers an enhanced.csv file processing feature that separates content and metadata.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph. in F1-score.
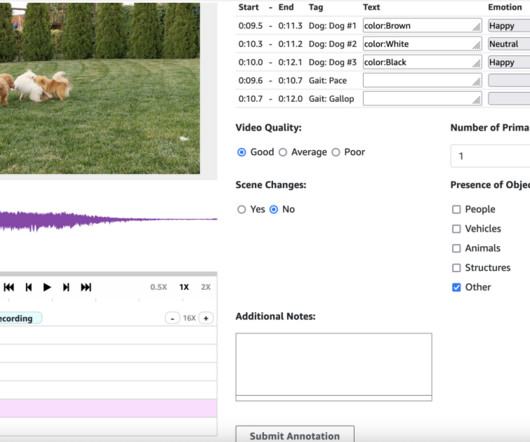
We start with a simple scenario: you have an audio file stored in Amazon S3, along with some metadata like a call ID and its transcription. What feature would you like to see added ? " } You can adapt this structure to include additional metadata that your annotation workflow requires.
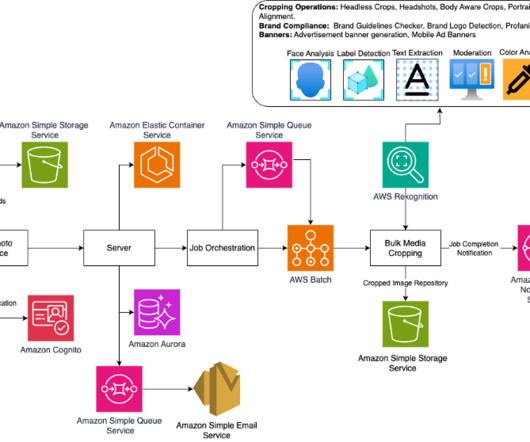
Amazon Rekognition is an AWS computervision service that powers Crop.photos automated image analysis. This transcribed text can then be used to enrich the metadata and descriptions associated with the product images or videos, improving searchability and accessibility for customers.
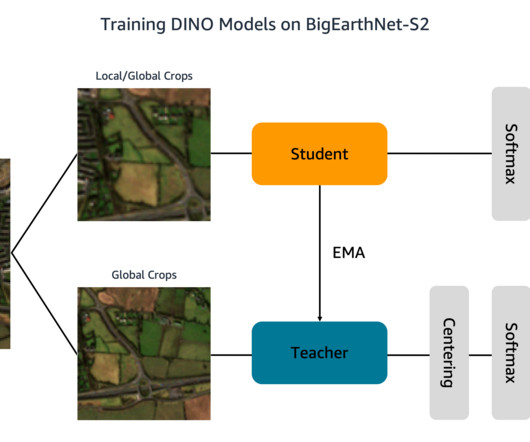
Additionally, each folder contains a JSON file with the image metadata. To perform statistical analyses of the data and load images during DINO training, we process the individual metadata files into a common geopandas Parquet file. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. tif" --include "_B03.tif"
One of the most powerful features of Spotlight is its ability to generate structured metadata from images. Its ability to generate accurate descriptions, captions, and structured metadata opens up a wide range of applications, from content creation to data management.
Jump Right To The Downloads Section People Counter on OAK Introduction People counting is a cutting-edge application within computervision, focusing on accurately determining the number of individuals in a particular area or moving in specific directions, such as “entering” or “exiting.” Looking for the source code to this post?
A media metadata store keeps the promotion movie list up to date. The agent takes the promotion item list (movie name, description, genre) from a media metadata store. The first component retrieves data from a feature store, and the second component acquires a list of movie promotions from the metadata store.
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deep learning, computervision, natural language processing, machine learning, cloud computing, and edge AI. Viso Suite enables organizations to solve the challenges of scaling computervision.
Her primary areas of interest encompass Deep Learning, with a focus on GenAI, ComputerVision, NLP, and time series data prediction. in a code subdirectory. in a code subdirectory. in a code subdirectory. in a code subdirectory. Feel free to share your thoughts in the comments.
Voxel51 is the company behind FiftyOne, the open-source toolkit for building high-quality datasets and computervision models. FiftyOne by Voxel51 is an open-source toolkit for curating, visualizing, and evaluating computervision datasets so that you can train and analyze better models by accelerating your use cases.
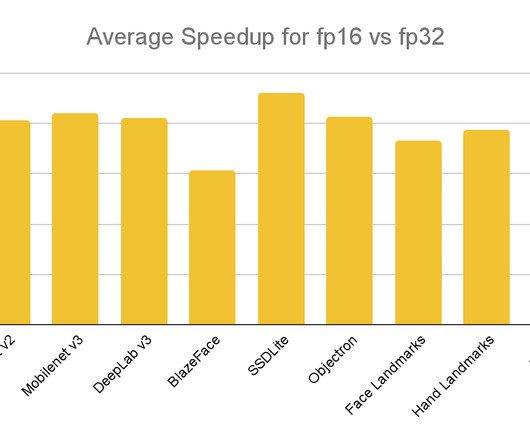
To benefit from the half-precision inference in XNNPack, the user must provide a floating-point (FP32) model with FP16 weights and special "reduced_precision_support" metadata to indicate model compatibility with FP16 inference. Additionally, the XNNPack delegate provides an option to force FP16 inference regardless of the model metadata.
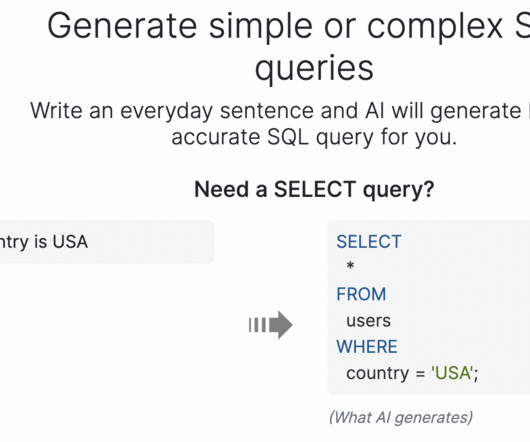
This enables supplementing the natural language input with crucial metadata like table and column names. When creating a custom database schema, users can use autosuggest after the database schema has been imported. The AI Bot will be able to grasp the database schema and produce extremely accurate SQL queries.
Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata. CreateDatasetGroup DatasetIncludeItem Specify if you want to provide item metadata for this use case. A dataset must conform to the schema defined within Forecast.
Noise: The metadata associated with the content doesn’t have a well-defined ontology. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? Join me in computervision mastery. That’s not the case.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content