This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
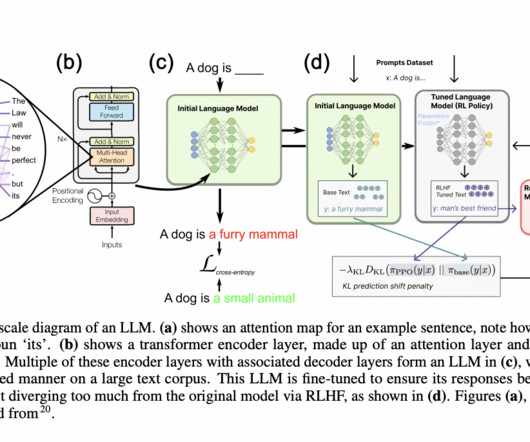
Introduction The introduction of the original transformers paved the way for the current LargeLanguageModels. Similarly, after the introduction of the transformer model, the vision transformer (ViT) was introduced.
In Part 1 of this series, we introduced Amazon SageMaker Fast Model Loader , a new capability in Amazon SageMaker that significantly reduces the time required to deploy and scale largelanguagemodels (LLMs) for inference. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
The importance of sight in understanding the world makes computervision essential for AI systems. By simplifying computervision development, startup Roboflow helps bridge the gap between AI and people looking to harness it. 22:15 How multimodalilty allows AI to be more intelligent.
The goal of this blog post is to show you how a largelanguagemodel (LLM) can be used to perform tasks that require multi-step dynamic reasoning and execution. He specializes in helping customers accelerate business outcomes on AWS through the application of machine learning and generative AI.
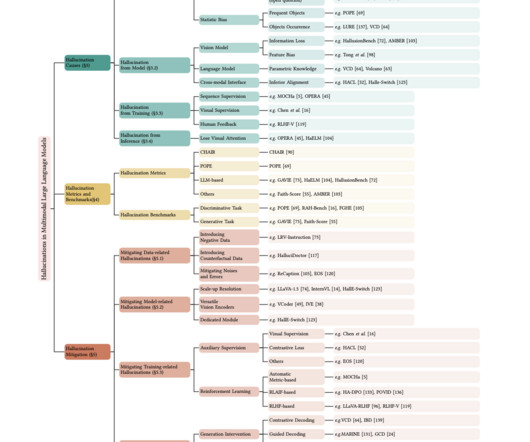
Multimodal largelanguagemodels (MLLMs) rapidly evolve in artificial intelligence, integrating vision and language processing to enhance comprehension and interaction across diverse data types. Check out the Paper and Model Card on Hugging Face. Don’t Forget to join our 55k+ ML SubReddit.
Computervision can be a viable solution to speed up operator inspections and reduce human errors by automatically extracting relevant data from the label. However, building a standard computervision application capable of managing hundreds of different types of labels can be a complex and time-consuming endeavor.
The emergence of Mixture of Experts (MoE) architectures has revolutionized the landscape of largelanguagemodels (LLMs) by enhancing their efficiency and scalability. This innovative approach divides a model into multiple specialized sub-networks, or “experts,” each trained to handle specific types of data or tasks.
He enjoyed working at the intersection of several fields; human robot interaction, largelanguagemodels, and classical computervision were all necessary to create the robot. “It was a really fun project,” says Oliver Limoyo, one of the creators of PhotoBot.
TL;DR Multimodal LargeLanguageModels (MLLMs) process data from different modalities like text, audio, image, and video. Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application.
LargeLanguageModels (LLMs) signify a revolutionary leap in numerous application domains, facilitating impressive accomplishments in diverse tasks. Yet, their immense size incurs substantial computational expenses. With billions of parameters, these models demand extensive computational resources for operation.
Development History Akool is a tech startup founded in 2022 by Jiajun Lu, a seasoned expert in AI and computervision. Jiajun Lu, the founder and CEO of Akool, has a strong background in AI and computervision. has been recognized as one of the global leaders in artificial intelligence and computervision.
What Is Ollama and the Ollama API Functionality Ollama is an open-source framework that enables developers to run largelanguagemodels (LLMs) like Llama 3.2 Vision locally on their machines. Vision directly on your local machine. With Ollamas model management sorted, its time to meet Llama 3.2,
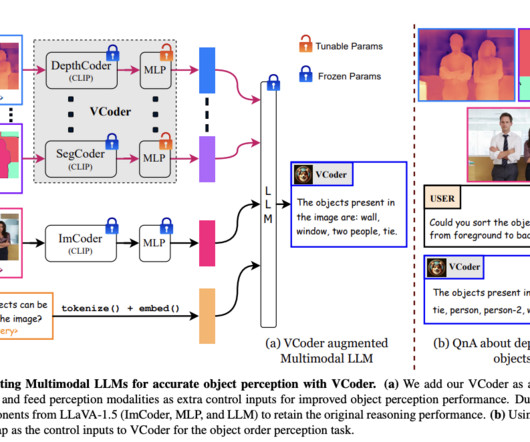
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge intersection of language processing and computervision, tasked with understanding and generating responses that consider both text and imagery. If you like our work, you will love our newsletter.
Introduction This article explores VisionLanguageModels (VLMs) and their advantages over traditional computervision-based models. Learning Objectives This article was published as a part […] The post What are Pre-training Methods of VisionLanguageModels?
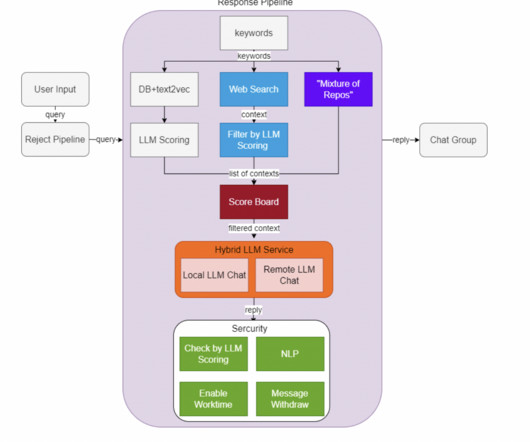
Researchers from Shanghai AI Laboratory introduced HuixiangDou, a technical assistant based on LargeLanguageModels (LLM), to tackle these issues, marking a significant breakthrough. HuixiangDou is designed for group chat scenarios in technical domains like computervision and deep learning.
Multimodal largelanguagemodels (MLLMs) are cutting-edge innovations in artificial intelligence that combine the capabilities of language and visionmodels to handle complex tasks such as visual question answering & image captioning. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
The Ascend 910C delivers high computational power, consuming around 310 watts. The chip is designed for flexibility and scalability, enabling it to handle various AI workloads such as Natural Language Processing (NLP) , computervision , and predictive analytics. The timing of the Ascend 910C launch is significant.
Multimodal largelanguagemodels (MLLMs) focus on creating artificial intelligence (AI) systems that can interpret textual and visual data seamlessly. The NVLM-H model, in particular, strikes a balance between image processing efficiency and multimodal reasoning accuracy, making it one of the most promising models in this field.
From breakthroughs in largelanguagemodels to revolutionary approaches in computervision and AI safety, the research community has outdone itself. Vision Mamba Summary: Vision Mamba introduces the application of state-space models (SSMs) to computervision tasks.
The emergence of largelanguagemodels (LLMs) has sparked a profound shift in the dynamic realm of scientific research. Utilizing LLMs’ natural language understanding capabilities, this system parses figure captions and abstracts to label micrographs with relevant material and accurate instrument information.
In the evolving landscape of artificial intelligence and machine learning, the integration of visual perception with language processing has become a frontier of innovation. This integration is epitomized in the development of Multimodal LargeLanguageModels (MLLMs), which have shown remarkable prowess in a range of vision-language tasks.
To address this issue, the team developed DRoP (Distributionally Robust Pruning), a new pruning approach that carefully selects how many samples to keep from each class based on how difficult that class is for the model to learn. You need to balance these domains while removing redundancy to ensure the model performs well across all ofthem.
Introduction OpenAI’s development of CLIP (Contrastive Language Image Pre-training) has seen a lot of development in multimodal and natural languagemodels. With different applications, this computervision system can help represent text and images in a vector format.
Traditional neural network models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. By using the model’s broad linguistic understanding, you can perform NER on the fly for any specified entity type.
Multimodal LargeLanguageModels (MLLMs) represent an advanced field in artificial intelligence where models integrate visual and textual information to understand and generate responses. If you like our work, you will love our newsletter.
LargeLanguageModels (LLMs) have extended their capabilities to different areas, including healthcare, finance, education, entertainment, etc. These models have utilized the power of Natural Language Processing (NLP), Natural Language Generation (NLG), and ComputerVision to dive into almost every industry.
As artificial intelligence (AI) continues to evolve, so do the capabilities of LargeLanguageModels (LLMs). These models use machine learning algorithms to understand and generate human language, making it easier for humans to interact with machines.
Some of the earliest and most extensive work has occurred in the use of deep learning and computervisionmodels. observational studies and clinical trials–have used population-focused modeling approaches that rely on regression models, in which independent variables are used to predict outcomes.
Recent advancements in multimodal largelanguagemodels (MLLM) have revolutionized various fields, leveraging the transformative capabilities of large-scale languagemodels like ChatGPT. If you like our work, you will love our newsletter.
The ecosystem has rapidly evolved to support everything from largelanguagemodels (LLMs) to neural networks, making it easier than ever for developers to integrate AI capabilities into their applications. environments.
Existing work includes isolated computervision techniques for image classification and natural language processing for textual data analysis. The difficulty lies in extracting relevant information from images and correlating it with textual data, essential for advancing research and applications in this field.
This approach unleashes the full potential of 2D models and strategies to scale them to the 3D world. In this article, we will delve deeper into 3D computervision and the Uni3D framework, exploring the essential concepts and the architecture of the model. So, let’s begin.
Introduction Recently, LargeLanguageModels (LLMs) have made great advancements. However, ChatGPT is limited in processing visual information since it’s trained with a single language modality.
With recent advances in largelanguagemodels (LLMs), a wide array of businesses are building new chatbot applications, either to help their external customers or to support internal teams. He specializes in computervision and languagemodeling, with applications in healthcare, energy, and education.
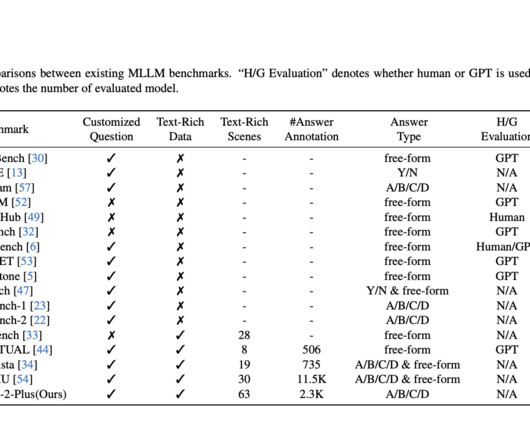
Evaluating Multimodal LargeLanguageModels (MLLMs) in text-rich scenarios is crucial, given their increasing versatility. MLLMs like GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus showcase impressive capabilities but lack comprehensive evaluation in text-rich contexts. If you like our work, you will love our newsletter.
Their work at BAIR, ranging from deep learning, robotics, and natural language processing to computervision, security, and much more, has contributed significantly to their fields and has had transformative impacts on society. Currently, I am working on LargeLanguageModel (LLM) based autonomous agents.
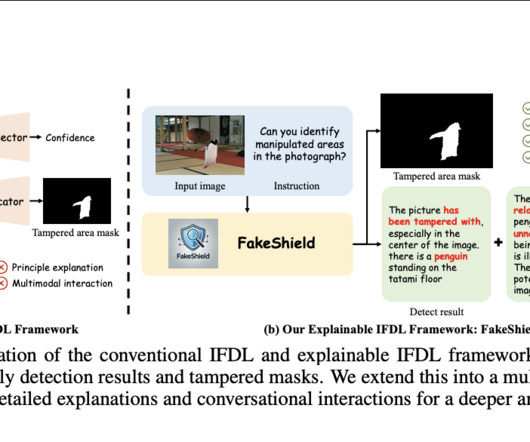
The rise of powerful image editing models has further blurred the line between real and fake content, posing risks such as misinformation and legal issues. The post FakeShield: An Explainable AI Framework for Universal Image Forgery Detection and Localization Using Multimodal LargeLanguageModels appeared first on MarkTechPost.
Multimodal LargeLanguageModels (MLLMs) have made significant progress in various applications using the power of Transformer models and their attention mechanisms. Researchers are focusing on addressing these biases without altering the model’s weights.
The development of multimodal largelanguagemodels (MLLMs) represents a significant leap forward. These advanced systems, which integrate language and visual processing, have broad applications, from image captioning to visible question answering. If you like our work, you will love our newsletter.
VideoLLaMA 2 retains the dual-branch architecture of its predecessor, with separate Vision-Language and Audio-Language branches that connect pre-trained visual and audio encoders to a largelanguagemodel.
The performance of multimodal largeLanguageModels (MLLMs) in visual situations has been exceptional, gaining unmatched attention. However, their ability to solve visual math problems must still be fully assessed and comprehended.
Building on years of experience in deploying ML and computervision to address complex challenges, Syngenta introduced applications like NemaDigital, Moth Counter, and Productivity Zones. Victor Antonino , M.Eng, is a Senior Machine Learning Engineer at AWS with over a decade of experience in generative AI, computervision, and MLOps.
Alix Melchy is the VP of AI at Jumio, where he leads teams of machine learning engineers across the globe with a focus on computervision, natural language processing and statistical modeling. DAOs also capture detailed descriptions of ID documents, ensuring accurate data validation and security checks at scale.
NIM microservices support a range of AI applications, including largelanguagemodels ( LLMs ), visionlanguagemodels, image generation, speech processing, retrieval-augmented generation ( RAG )-based search, PDF extraction and computervision. asr , Maxine Studio Voice RAG: Llama-3.2-NV-EmbedQA-1B-v2
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content