This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
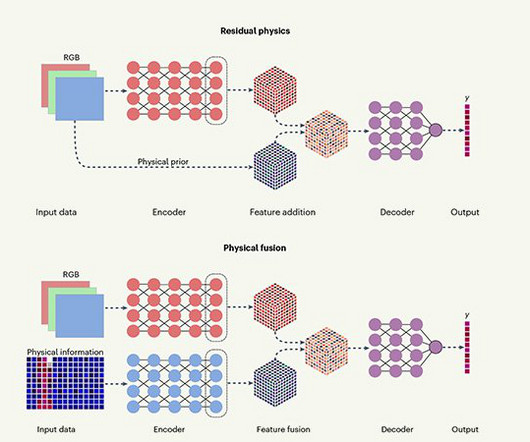
In a pioneering effort to further enhance AI capabilities, researchers from UCLA and the United States Army Research Laboratory have unveiled a unique approach that marries physics-awareness with data-driven techniques in AI-powered computervision technologies.
Information refers to. The post Performing ComputerVision Task With OpenCV And Python appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Data is often defined as raw facts.
Like the transformers which excel at understanding text and generating text given a response, vision transformer models were developed to understand images and provide information […] The post How to Perform ComputerVision Tasks with Florence-2 appeared first on Analytics Vidhya.
As AI disrupts nearly every industry, the agriculture sector, which faces significant obstacles on multiple fronts, is cautiously embracing machine learning, computervision, and other data-driven processes. The tractor didnt just offer farmers a tool to improve their business operations, it also helped supplement food supplies.
Up until now, object detection in images using computervision models faced a major roadblock of a few seconds of lag due to processing time. However, the YOLOv8 computervision model's release by Ultralytics has broken through the processing delay. What Makes YOLOv8 Standout? yaml’ file instead of a ‘.pt’
This article was published as a part of the Data Science Blogathon If you are interested or planning to do anything which is related to images or videos, you should definitely consider using ComputerVision. The post Getting started with the basic tasks of ComputerVision appeared first on Analytics Vidhya.
Ninety percent of information transmitted to the human brain is visual. The importance of sight in understanding the world makes computervision essential for AI systems. By simplifying computervision development, startup Roboflow helps bridge the gap between AI and people looking to harness it.
Despite their capabilities, AI & ML models are not perfect, and scientists are working towards building models that are capable of learning from the information they are given, and not necessarily relying on labeled or annotated data.
One transformative innovation steering this revolution is computervision – AI-driven technology that enables machines to “understand” and react to visual information. Here are 6 ways computervision is driving cars into the future. Here are 6 ways computervision is driving cars into the future.
Comprehensive experiments performed on the EfficientViT model across different scenarios indicate that the EfficientViT outperforms existing efficient models for computervision while striking a good trade-off between accuracy & speed. So let’s take a deeper dive, and explore the EfficientViT model in a little more depth.
Among the most notable innovations is video analytics, which, through the use of computervision, is providing retailers with powerful insights into consumer behavior, store dynamics, and operational efficiency. At its core, computervision enables machines to interpret and understand visual data.
Introduction As we all know, ComputerVision has gained huge popularity in Machine Learning and Artificial Intelligence. The image recognition skill allows computers to process more information than the human eye, often faster and more accurately, or simply when people are not involved in […].
Understanding Query Parameters Query parameters allow users to send additional information as part of the URL. Path parameters are used when the URL needs to include dynamic information, such as an ID or a name. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated?
The system's AI framework extends beyond basic content matching, incorporating NLP and computervision technologies to evaluate subtle nuances in creator content. It processes information from over 4 million influencer profiles through matching algorithms, helping identify and manage authentic brand collaborations.
Introduction Over the years, we have been using Computervision (CV) and image processing techniques from artificial intelligence (AI) and pattern recognition to derive information from images, videos, and other visual inputs.
Introduction ComputerVision Is one of the leading fields of Artificial Intelligence that enables computers and systems to extract useful information from digital photos, movies, and other visual inputs. This article was published as a part of the Data Science Blogathon.
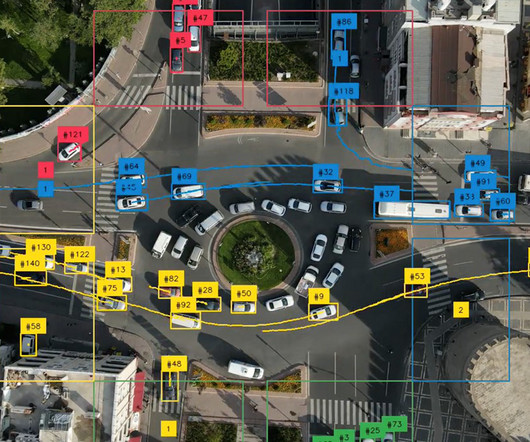
We designed the AVs with deployment in mind, ensuring that they can operate using only basic sensor information about themselves and the vehicle in front. Modular control framework: One key challenge during the test was not having access to the leading vehicle information sensors.
Citation Information 3D Gaussian Splatting vs NeRF: The End Game of 3D Reconstruction? With that, the resulting 3D models often lack detailed textures, colors, and other essential information. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated?
Introduction In the exciting subject of computervision, where images contain many secrets and information, distinguishing and highlighting items is crucial.
Multimodal Capabilities in Detail Configuring Your Development Environment Project Structure Implementing the Multimodal Chatbot Setting Up the Utilities (utils.py) Designing the Chatbot Logic (chatbot.py) Building the Interface (app.py) Summary Citation Information Building a Multimodal Gradio Chatbot with Llama 3.2 Introducing Llama 3.2
This is where the emergence of Large Vision Models (LVMs) becomes crucial. LVMs are a new category of AI models specifically designed for analyzing and interpreting visual information, such as images and videos, on a large scale, with impressive accuracy.
Introduction Computervision is a field of A.I. that deals with deriving meaningful information from images. This article was published as a part of the Data Science Blogathon. These are easy to develop […].
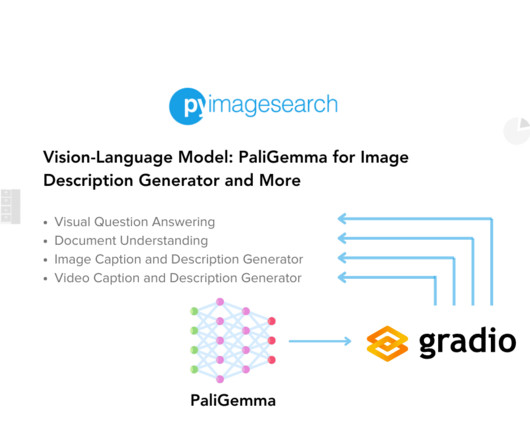
For more information, head over to Fine Tune PaliGemma with QLoRA for Visual Question Answering. The debug=True option enables debugging information, which can be helpful for troubleshooting. Document Understanding involves analyzing images that contain both visual elements and textual information. We begin by using cv2.VideoCapture(video_path)
Photo by Jaredd Craig on Unsplash In this article, we will review the paper titled “Computation-Efficient Knowledge Distillation via Uncertainty-Aware Mixup” [1], which aims to reduce the computational cost associated with distilling the knowledge of computervision models. Katharopoulos et al. [4]
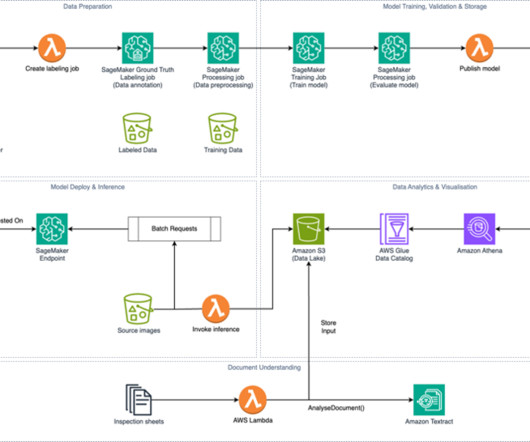
Specifically, we cover the computervision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. The resulting dashboard highlighted that 141 power pole assets required action, out of a network of 57,230 poles.
AI/ML and generative AI: Computervision and intelligent insights As drones capture video footage, raw data is processed through AI-powered models running on Amazon Elastic Compute Cloud (Amazon EC2) instances. Computervision algorithms analyze the video in real time.
To learn how to master YOLO11 and harness its capabilities for various computervision tasks , just keep reading. With improvements in its design and training techniques, YOLO11 can handle a variety of computervision tasks, making it a flexible and powerful tool for developers and researchers alike.
These functions are anchored by a comprehensive user management system that controls access to sensitive information and maintains secure connections between patient records and user profiles. Patients can schedule appointments and access health information through a dedicated portal.
Instead of embedding all learned information within fixed-weight parameters, SMLs introduce an external memory system, retrieving information only when needed. This decoupling of computation from memory storage significantly reduces computational overhead, improving scalability without excessive hardware resource consumption.
The model sets a new benchmark for answering visual questions, describing visual content, story creation from images, document information extraction, and even performing arithmetic operations based on visual input.
While current AI systems excel at processing information and generating responses, the next generation of AI needs to do something far more challenging: take meaningful action in both digital and physical spaces. Think about the difference between an assistant that can tell you how to book a flight and one who can actually book it for you.
These models are designed to understand and generate text about images, bridging the gap between visual information and natural language. Rather than answering the question with generic information that the LLM was trained on (which may be out of date), responses will be grounded with your local and specific car sales dataset.
NIM microservices support a range of AI applications, including large language models ( LLMs ), vision language models, image generation, speech processing, retrieval-augmented generation ( RAG )-based search, PDF extraction and computervision. Check out the G-Assist article for system requirements and additional information.
Utilizing computervision algorithms that process a steady stream of captured images, the radar-based technology continuously analyzes various room layouts, outdoor and indoor situations, circumstances with pets, and people of varying shapes, sizes, and ages to accurately classify and detect falls.
These word vectors are trained from Twitter data making them semantically rich in information. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Here youll learn how to successfully and confidently apply computervision to your work, research, and projects.
In the context of OpenAI CLIP, embeddings are vectors that encode semantic information about images and text in a shared representation space. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Join me in computervision mastery. We Made It! Thakur, eds.,
Machine Learning Algorithm Illustration: Source Getty Images ComputerVision is booming, and with the rise of multi modal AI models, its easier than ever to leverage its power. But if youre just getting started and feeling overwhelmed by the sheer amount of information out there dont worry!
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach can also enhance the quality of retrieved information and responses generated by the RAG applications.
Figures present another challenge captions might be separated from their images, and important visual information gets lost in translation. Traditional systems frequently misinterpret these elements, turning a simple equation into gibberish or losing critical technical information. Interpret visual scenes to answer questions.
AI comprises numerous technologies like deep learning, machine learning, natural language processing, and computervision. ComputerVision With computervision algorithms, AI is enabled to study medical images and videos, positively impacting medical diagnosis.
Despite advances in image and text-based AI research, the audio domain lags due to the absence of comprehensive datasets comparable to those available for computervision or natural language processing. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
In ComputerVision , Gemma 3 allows machines to interpret visual information precisely. Natural language processing enables machines to understand and generate human language, powering use cases like language translation, sentiment analysis, speech recognition, and intelligent chatbots.
Sponsor AI Investing is here with Pluto Make informed investment decisions like never before with Pluto, the pioneer in AI investing. However, sharing biomedical data can put sensitive personal information at risk. Powered by pluto.fi theage.com.au Try Pluto for free today] pluto.fi
Roadzen has pioneered computervision research, generative AI and telematics including tools and products for road safety, underwriting and claims. How does Roadzen use computervision to assess the value of a vehicle? How is this information then used for accident prevention?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























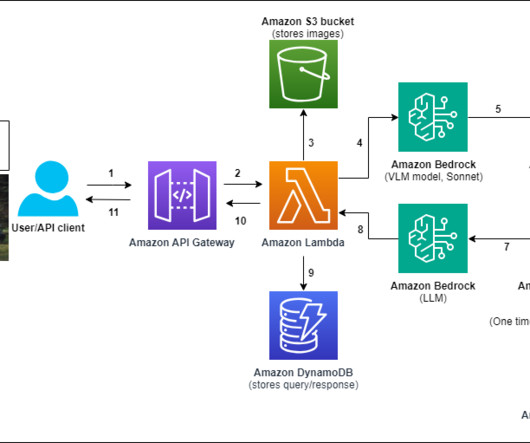

















Let's personalize your content