This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Jump Right To The Downloads Section What Is Gradio and Why Is It Ideal for Chatbots? Model Management: Easily download, run, and manage various models, including Llama 3.2 Default Model Storage Location By default, Ollama stores all downloaded models in the ~/.ollama/models Vision model with ollama pull llama3.2-vision
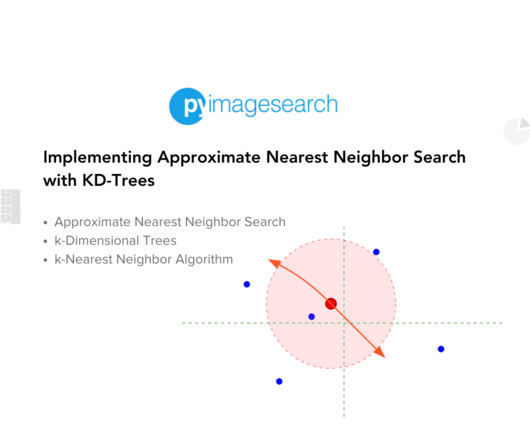
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. product specifications, movie metadata, documents, etc.)
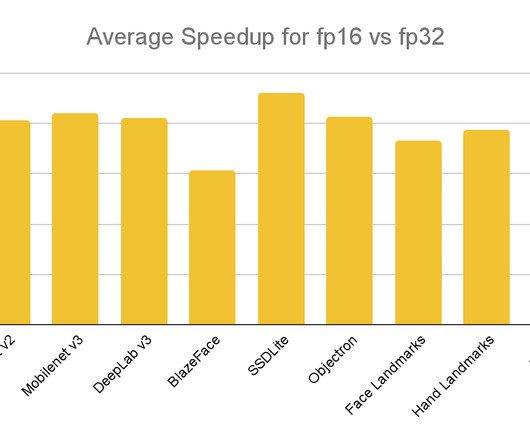
To benefit from the half-precision inference in XNNPack, the user must provide a floating-point (FP32) model with FP16 weights and special "reduced_precision_support" metadata to indicate model compatibility with FP16 inference. Additionally, the XNNPack delegate provides an option to force FP16 inference regardless of the model metadata.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
We start with a simple scenario: you have an audio file stored in Amazon S3, along with some metadata like a call ID and its transcription. Complete the following steps for manual deployment: Download these assets directly from the GitHub repository. The assets (JavaScript and CSS files) are available in our GitHub repository.
Download the model and its components WhisperX is a system that includes multiple models for transcription, forced alignment, and diarization. For smooth SageMaker operation without the need to fetch model artifacts during inference, it’s essential to pre-download all model artifacts. in a code subdirectory. in a code subdirectory.
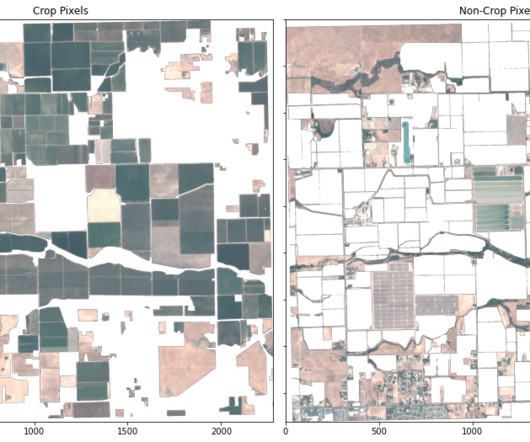
An Introduction to Image Segmentation Image segmentation is a massively popular computervision task that deals with the pixel-level classification of images. Note: Downloading the dataset takes 1.2 Now, let’s download the dataset from the ? dropout ratio) and other relevant metadata (e.g., GB of disk space.
Jump Right To The Downloads Section People Counter on OAK Introduction People counting is a cutting-edge application within computervision, focusing on accurately determining the number of individuals in a particular area or moving in specific directions, such as “entering” or “exiting.” mp4 │ └── example_02.mp4
Noise: The metadata associated with the content doesn’t have a well-defined ontology. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? Join me in computervision mastery. That’s not the case.
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deep learning, computervision, natural language processing, machine learning, cloud computing, and edge AI. Viso Suite enables organizations to solve the challenges of scaling computervision.
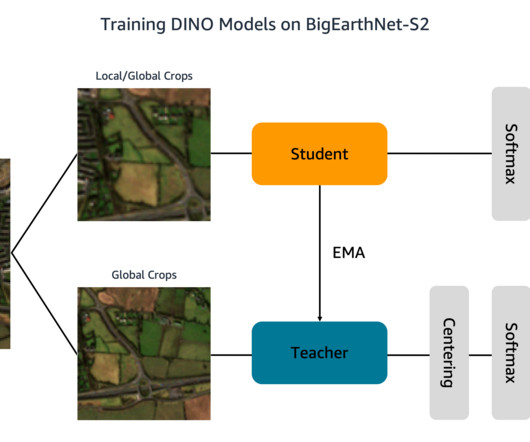
We start by downloading the dataset from the terminal of our SageMaker notebook instance: wget [link] tar -xvf BigEarthNet-S2-v1.0.tar.gz Additionally, each folder contains a JSON file with the image metadata. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. The dataset has a size of about 109 GB.
The coefficients for correcting to at-sensor reflectance are provided in the scene metadata, which further improves the consistency between images taken at different times. This example uses the Python client to identify and download imagery needed for the analysis. Xiong Zhou is a Senior Applied Scientist at AWS.
Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata. CreateDatasetGroup DatasetIncludeItem Specify if you want to provide item metadata for this use case. A dataset must conform to the schema defined within Forecast. Choose Create folder.
Voxel51 is the company behind FiftyOne, the open-source toolkit for building high-quality datasets and computervision models. FiftyOne by Voxel51 is an open-source toolkit for curating, visualizing, and evaluating computervision datasets so that you can train and analyze better models by accelerating your use cases.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs. Creates an OpenSearch Service domain for the search application.
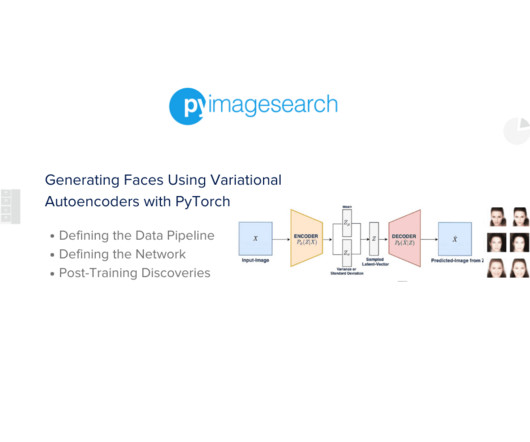
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deep learning has achieved remarkable success in supervised tasks, especially in image recognition. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images. The config.py
Start by using the following code to download the PDF documents from the provided URLs and create a list of metadata for each downloaded document. !mkdir In the next step, you will take the downloaded data, trim the 10-K (first four pages) and overwrite them as processed files. Marco Punio is a Sr.
Most publicly available image databases are difficult to edit beyond crude image augmentations and lack fine-grained metadata. However, it is difficult to get such information due to concerns over privacy, bias, and copyright infringement.
2 For dynamic models, such as those with variable-length inputs or outputs, which are frequent in natural language processing (NLP) and computervision, PyTorch offers improved support. To save the model using ONNX, you need to have onnx and onnxruntime packages downloaded in your system.
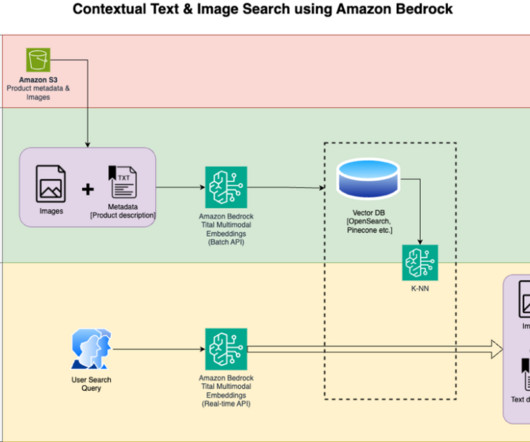
The following are the solution workflow steps: Download the product description text and images from the public Amazon Simple Storage Service (Amazon S3) bucket. Load the publicly available Amazon Berkeley Objects Dataset and metadata in a pandas data frame. You then display the top similar results. Review and prepare the dataset.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. Image 1: Image 2: Input: def url_to_base64(image_url): # Download the image response = requests.get(image_url) if response.status_code != b64encode(img).decode('utf-8')
skills and industry) and course metadata (e.g., Course information: 78 total classes • 97+ hours of on-demand code walkthrough videos • Last updated: July 2023 ★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computervision and deep learning.
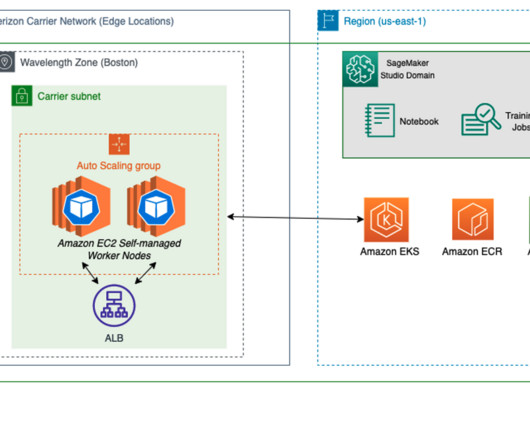
As an example, smart venue solutions can use near-real-time computervision for crowd analytics over 5G networks, all while minimizing investment in on-premises hardware networking equipment. Deploy SageMaker model artifacts Make sure you have kubectl and aws-iam-authenticator downloaded to your AWS Cloud9 IDE. Instances[*].
Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI (GenAI) can be helpful in generating the metadata automatically. This helps us build more refined searches in the image search process.
Jump Right To The Downloads Section Configuring Your Development Environment To follow this guide, you need to have torch , torchvision , tqdm , and matplotlib libraries installed on your system. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images. The config.py
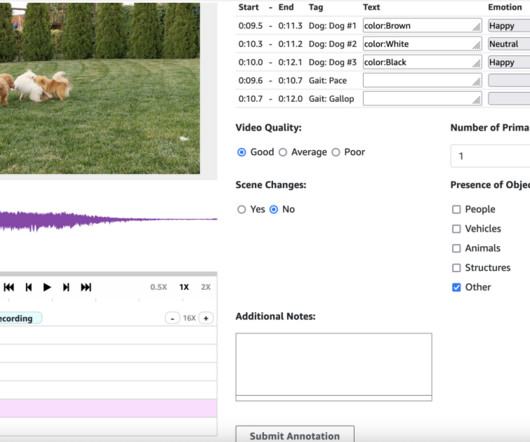
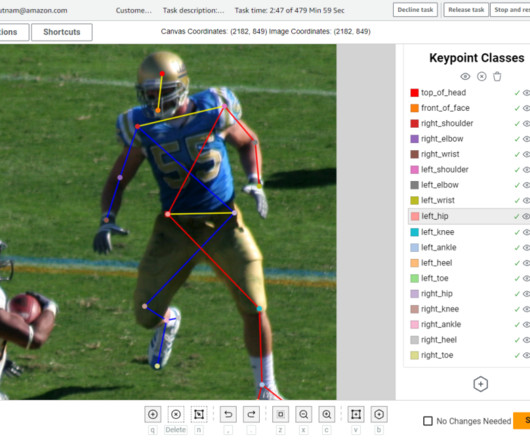
Pose estimation is a computervision technique that detects a set of points on objects (such as people or vehicles) within images or videos. This input manifest file contains metadata for a labeling job, acts as a reference to the data that needs to be labeled, and helps configure how the data should be presented to the annotators.
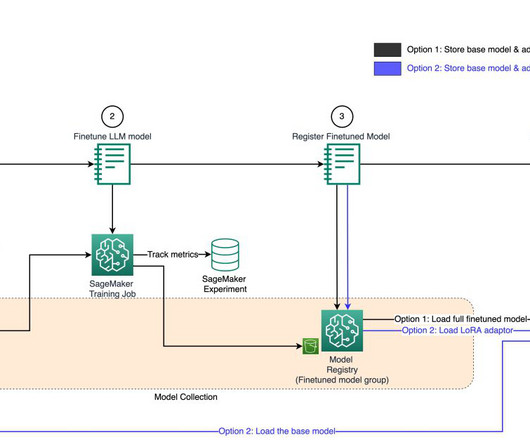
Each works through a different way to handle LoRA fine-tuned models as illustrated in the following diagram: First, we download the pre-trained Llama2 model with 7 billion parameters using SageMaker Studio Notebooks. They can also use SageMaker Experiments to download the created charts and share the model evaluation with their stakeholders.
The AWS Professional Services team has partnered with the NFL and Biocore to provide machine learning (ML)-based solutions for identifying helmet impacts from game footage using computervision (CV) techniques. You can download the endzone and sideline videos , and also the ground truth labels.
Jump Right To The Downloads Section OAK-D: Understanding and Running Neural Network Inference with DepthAI API Introduction In our previous tutorial, Introduction to OpenCV AI Kit (OAK) , we gave a primer on OAK by discussing the Luxonis flagship products: OAK-1 and OAK-D, becoming the most popular edge AI devices with depth capabilities.
Text to SQL: Using natural language to enhance query authoring SQL is a complex language that requires an understanding of databases, tables, syntaxes, and metadata. If you specify model_id=defog/sqlcoder-7b-2 , DJL Serving will attempt to directly download this model from the Hugging Face Hub.
Once downloaded in your .cache Image from Author Through the get_schema() , as shown in the above image, we can get information about how is set the data and metadata of our DataGrid and also the data types of each of them. cache/ Image from Author I know you may be wondering why the DataGrid is stored in a .arrow
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. Triton uses TorchScript for improved performance and flexibility.
Steps followed 1) Data Collection Creating the Google credentials and generating the YouTube Data API Key Scraping Youtube links using Python code and a generated API Key Downloading the videos of the links saved 2) Setup and Installations Setting up the virtual Python 3.9 mp4 │ │ │ ├── video2.mp4 mp4 │ │ │ ├── video4.mp4 mp4 │ │ ├── video8.mp4
Each item has rich metadata (e.g., And it goes on to personalize title images, trailers, metadata, synopsis, etc. These features can be simple metadata or model-based features (extracted from a deep learning model), representing how good that video is for a member. Or requires a degree in computer science?
Install Git and Docker to build Docker images and download the application from GitHub. Although this post only included natural language processing of sensitive data, you can modify this architecture to support alternate LLMs supporting audio, computervision, or multi-modalities. You need to update the server.py
that comply to YOLOv5 with specific requirement on model output, which easily got mess up thru conversion of model from PyTorch > ONNX > Tensorflow > TensorflowJS) ComputerVision Annotation Tool (CVAT) CVAT is build by Intel for doing computervision annotation which put together openCV, OpenVino (to speed up CPU inference).
Jump Right To The Downloads Section Configuring Your Development Environment To follow this guide, you need to have numpy , Pillow , torch , torchvision , matplotlib , pandas , scipy , and imageio libraries installed on your system. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
The solution captures speaker audio and metadata directly from your browser-based meeting application (currently compatible with Zoom and Chime, with others coming), and audio from other browser-based meeting tools, softphones, or other audio input. To deploy the LMA for healthcare, select Healthcare from the dropdown menu as your domain.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computervision, natural language processing, content creation, and more. After you log in to your EC2 instance, download the AWS PyTorch 2.0 Complete the following steps to download your DLC: a.
_backward : This is a private method that computes the global derivative of the children of the current node. class Value(object): """ We need to wrap the raw data into a class that will store the metadata to help in automatic differentiation. Or requires a degree in computer science? Join me in computervision mastery.
How Veo Eliminated Work Loss With Neptune Computer-vision models are an integral part of Veo’s products. Initially, the team started with MLflow as the experiment tracker but quickly found it unreliable, especially under heavy computational loads. Neptune offers dedicated user support, helping to solve issues quickly.
They clicked on it, they found it, they take a selfie of Earth, and they have one image collected, plus all the metadata. TLDR, all those unique modules are available online and you can mix and match them for any computervision problem. Let’s say when we started, it turns out that downloading data from NASA is work.
They clicked on it, they found it, they take a selfie of Earth, and they have one image collected, plus all the metadata. TLDR, all those unique modules are available online and you can mix and match them for any computervision problem. Let’s say when we started, it turns out that downloading data from NASA is work.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content