This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The SEER model by Facebook AI aims at maximizing the capabilities of self-supervised learning in the field of computervision. The Need for Self-Supervised Learning in ComputerVision Data annotation or data labeling is a pre-processing stage in the development of machine learning & artificial intelligence models.
Model Manifests: Metadata files describing the models architecture, hyperparameters, and version details, helping with integration and version tracking. Vision model with ollama pull llama3.2-vision vision , Ollama downloads and stores both the model blobs and manifests in the ~/.ollama/models Join me in computervision mastery.
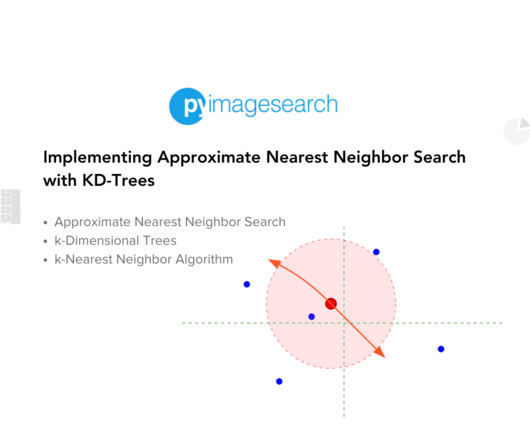
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. product specifications, movie metadata, documents, etc.)
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deeplearning, computervision , natural language processing , and more. Another subfield that is quite popular amongst AI developers is deeplearning, an AI technique that works by imitating the structure of neurons.
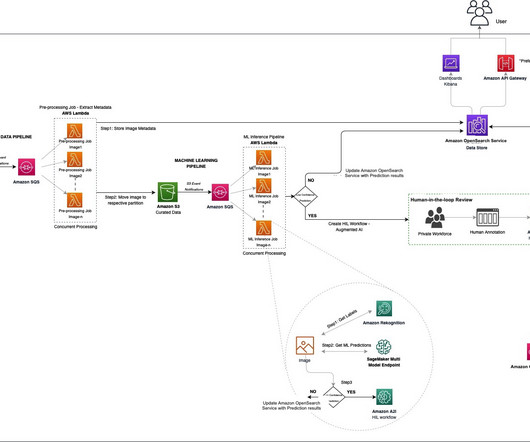
In recent years, advances in computervision have enabled researchers, first responders, and governments to tackle the challenging problem of processing global satellite imagery to understand our planet and our impact on it. With Amazon Rekognition, we get a good baseline of detected objects.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. He focuses on Deeplearning including NLP and ComputerVision domains.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Deliver new insights Expert systems can be trained on a corpus—metadata used to train a machine learning model—to emulate the human decision-making process and apply this expertise to solve complex problems. AI platforms can use machine learning and deeplearning to spot suspicious or anomalous transactions.
Bias detection in ComputerVision (CV) aims to find and eliminate unfair biases that can lead to inaccurate or discriminatory outputs from computervision systems. Computervision has achieved remarkable results, especially in recent years, outperforming humans in most tasks. Let’s get started.
In computervision datasets, if we can view and compare the images across different views with their relevant metadata and transformations within a single and well-designed UI, we are one step ahead in solving a CV task. Adding image metadata. Locate the “Metadata” section and toggle the dropdown. jpeg').to_pil()
This post gives a brief overview of modularity in deeplearning. Fuelled by scaling laws, state-of-the-art models in machine learning have been growing larger and larger. We give an in-depth overview of modularity in our survey on Modular DeepLearning. Case studies of modular deeplearning.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deeplearning, computervision, natural language processing, machine learning, cloud computing, and edge AI. Software #9: Observe.AI Software #10: TensorFlow Software #11: H2O.ai
Noise: The metadata associated with the content doesn’t have a well-defined ontology. To address all these challenges, YouTube employs a two-stage deeplearning-based recommendation strategy that trains large-scale models (with approximately one billion parameters) on hundreds of billions of examples. That’s not the case.
This lesson is the 3rd in our series on OAK 102 : Training the YOLOv8 Object Detector for OAK-D Hand Gesture Recognition with YOLOv8 on OAK-D in Near Real-Time People Counter on OAK (this tutorial) To learn how to implement and run people counting on OAK, just keep reading. Looking for the source code to this post? mp4 │ └── example_02.mp4
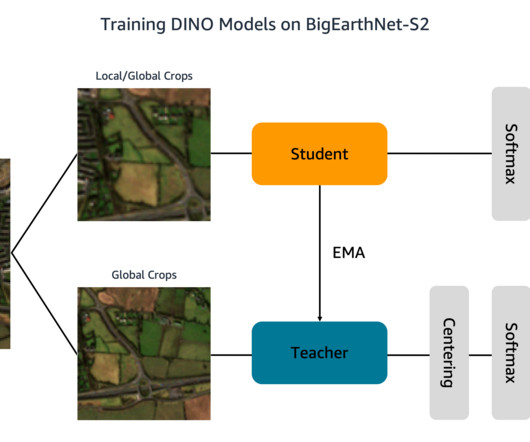
Additionally, each folder contains a JSON file with the image metadata. To perform statistical analyses of the data and load images during DINO training, we process the individual metadata files into a common geopandas Parquet file. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. tif" --include "_B03.tif"
About the Authors Ying Hou, PhD , is a Machine Learning Prototyping Architect at AWS. Her primary areas of interest encompass DeepLearning, with a focus on GenAI, ComputerVision, NLP, and time series data prediction. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": in a code subdirectory.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
A complete guide to building a deeplearning project with PyTorch, tracking an Experiment with Comet ML, and deploying an app with Gradio on HuggingFace Image by Freepik AI tools such as ChatGPT, DALL-E, and Midjourney are increasingly becoming a part of our daily lives. These tools were developed with deeplearning techniques.
In this section, you will see different ways of saving machine learning (ML) as well as deeplearning (DL) models. Saving deeplearning model with TensorFlow Keras TensorFlow is a popular framework for training DL-based models, and Ker as is a wrapper for TensorFlow. Now let’s see how we can save our model.
An Introduction to Image Segmentation Image segmentation is a massively popular computervision task that deals with the pixel-level classification of images. dropout ratio) and other relevant metadata (e.g., Do you think learningcomputervision and deeplearning has to be time-consuming, overwhelming, and complicated?
Achieve low latency on GPU instances via TensorRT TensorRT is a C++ library for high-performance inference on NVIDIA GPUs and deeplearning accelerators, supporting major deeplearning frameworks such as PyTorch and TensorFlow. He specializes in ComputerVision (CV) and Visual-Language Model (VLM).
This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs.
These artifacts refer to the essential components of a machine learning model needed for various applications, including deployment and retraining. They can include model parameters, configuration files, pre-processing components, as well as metadata, such as version details, authorship, and any notes related to its performance.
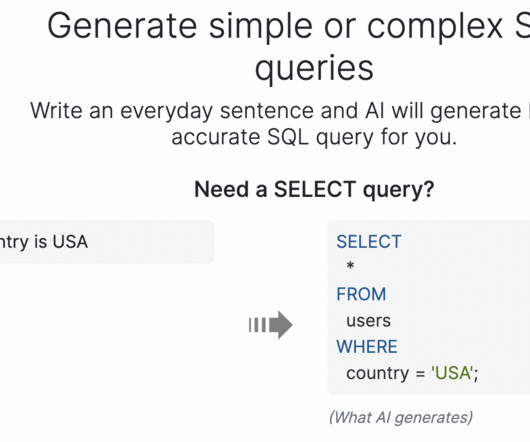
This enables supplementing the natural language input with crucial metadata like table and column names. When creating a custom database schema, users can use autosuggest after the database schema has been imported. The AI Bot will be able to grasp the database schema and produce extremely accurate SQL queries.
These limitations motivated the development of an embedding-based retrieval system that could learn representations directly from user engagement data, mirroring the success of deeplearning in ranking systems.
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. Do you think learningcomputervision and deeplearning has to be time-consuming, overwhelming, and complicated?
The capability of AI to execute complex tasks efficiently is determined by image annotation, which is a key determinant of its success and is defined as the process of labeling images with descriptive metadata. Since it lays the groundwork for AI applications, it is also often referred to as the ‘core of AI and machine learning.’
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computervision, natural language processing, content creation, and more. These are basically big models based on deeplearning techniques that are trained with hundreds of billions of parameters.
skills and industry) and course metadata (e.g., Collaborative Filtering Typically there are three collaborative filtering algorithms: user-item-based utility, matrix factorization technique, and deep neural network-based approach. Or requires a degree in computer science? Join me in computervision mastery.
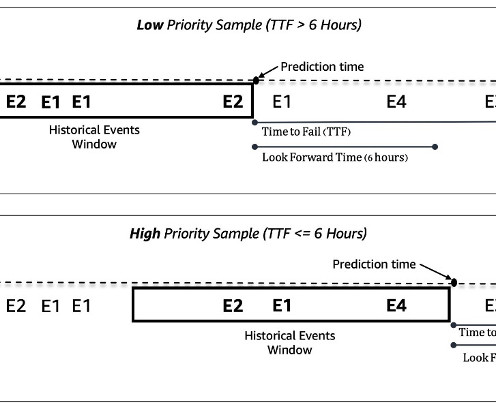
Machine ID Event Type ID Timestamp 0 E1 2022-01-01 00:17:24 0 E3 2022-01-01 00:17:29 1000 E4 2022-01-01 00:17:33 114 E234 2022-01-01 00:17:34 222 E100 2022-01-01 00:17:37 In addition to dynamic machine events, static metadata about each machine is also available. Mohamad Aljazaery is an applied scientist at Amazon ML Solutions Lab.
The sample set of de-identified, already publicly shared data included thousands of anonymized user profiles, with more than fifty user-metadata points, but many had inconsistent or missing meta-data/profile information. He has an extensive background in computer science and machine learning. This was stored in S3.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. Triton uses TorchScript for improved performance and flexibility.
Integrated computervision support. Visualize and filter bounding boxes, labels, and metadata without any extra setup. In this tutorial, I will show you how to get started with this new ComputerVision tool by experimenting with how to generate our own DataGrids, and analyze previously created ones.
This is the 2nd lesson in our 4-part series on OAK-101 : Introduction to OpenCV AI Kit (OAK) OAK-D: Understanding and Running Neural Network Inference with DepthAI API (today’s tutorial) OAK 101: Part 3 OAK 101: Part 4 To learn how DepthAI API works and run neural network inference on OAK-D, just keep reading.
In this post, we describe how Nielsen Sports modernized a system running thousands of different machine learning (ML) models in production by using Amazon SageMaker multi-model endpoints (MMEs) and reduced operational and financial cost by 75%. He excels in building and deploying deeplearning models to handle large-scale data efficiently.
About us: Viso Suite is the end-to-end computervision platform that helps enterprises solve business challenges with no code. To learn more about using Viso Suite to source data, train your model, and deploy it wherever you’d like, book a demo with us. Viso Suite is the end-to-End, No-Code ComputerVision Solution.
About us: Viso Suite is the end-to-end computervision platform that helps enterprises solve business challenges with no code. To learn more about using Viso Suite to source data, train your model, and deploy it wherever you’d like, book a demo with us. Viso Suite is the end-to-End, No-Code ComputerVision Solution.
Each item has rich metadata (e.g., And it goes on to personalize title images, trailers, metadata, synopsis, etc. Machine learning (ML) approaches can be used to learn utility functions by training it on historical data of which home pages have been created for members (i.e., Or requires a degree in computer science?
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. Leveraging her expertise in ComputerVision and DeepLearning, she empowers customers to harness the power of the ML in AWS cloud efficiently.
Earth.com’s leadership team recognized the vast potential of EarthSnap and set out to create an application that utilizes the latest deeplearning (DL) architectures for computervision (CV). It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
is armed with an AI brain that scrutinizes and learns the metadata of architectural designs, spawning variations while accounting for US local regulations and ordinances, ensuring that each project is innovative as well as compliant, championing efficiency, quality, and cost-effectiveness. ArkDesign.ai Like Kaedim, Luma.AI
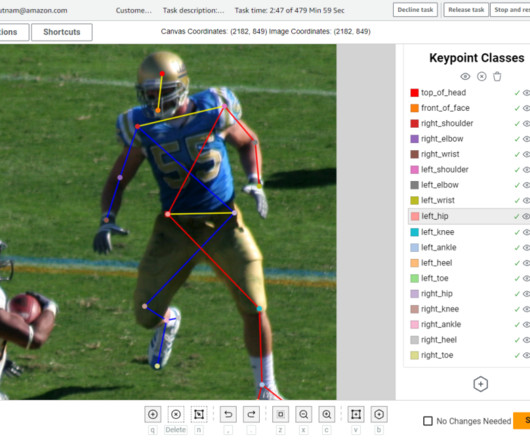
Pose estimation is a computervision technique that detects a set of points on objects (such as people or vehicles) within images or videos. This input manifest file contains metadata for a labeling job, acts as a reference to the data that needs to be labeled, and helps configure how the data should be presented to the annotators.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content