This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
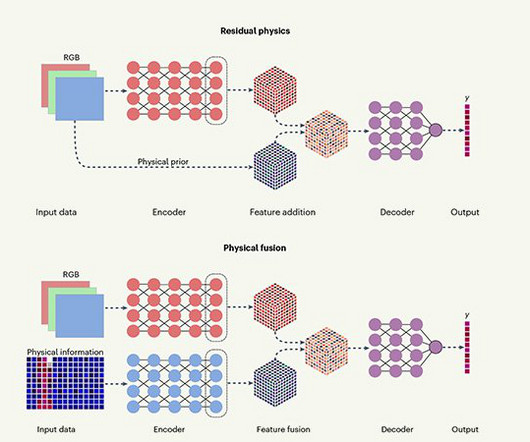
In a pioneering effort to further enhance AI capabilities, researchers from UCLA and the United States Army Research Laboratory have unveiled a unique approach that marries physics-awareness with data-driven techniques in AI-powered computervision technologies.
As AI disrupts nearly every industry, the agriculture sector, which faces significant obstacles on multiple fronts, is cautiously embracing machine learning, computervision, and other data-driven processes. The tractor didnt just offer farmers a tool to improve their business operations, it also helped supplement food supplies.
Like the transformers which excel at understanding text and generating text given a response, vision transformer models were developed to understand images and provide information […] The post How to Perform ComputerVision Tasks with Florence-2 appeared first on Analytics Vidhya.
Despite their capabilities, AI & ML models are not perfect, and scientists are working towards building models that are capable of learning from the information they are given, and not necessarily relying on labeled or annotated data.
Understanding Query Parameters Query parameters allow users to send additional information as part of the URL. Path parameters are used when the URL needs to include dynamic information, such as an ID or a name. Do you think learningcomputervision and deeplearning has to be time-consuming, overwhelming, and complicated?
Summary: DeepLearning vs Neural Network is a common comparison in the field of artificial intelligence, as the two terms are often used interchangeably. Introduction DeepLearning and Neural Networks are like a sports team and its star player. DeepLearning Complexity : Involves multiple layers for advanced AI tasks.
Introduction ComputerVision Is one of the leading fields of Artificial Intelligence that enables computers and systems to extract useful information from digital photos, movies, and other visual inputs. This article was published as a part of the Data Science Blogathon.
For years, deeplearning has relied on traditional dense layers, where every neuron in one layer is connected to every neuron in the next. This structure enables AI models to learn complex patterns, but it comes at a steep cost. Another problem with dense layers is that they struggle with knowledge updates.
Citation Information 3D Gaussian Splatting vs NeRF: The End Game of 3D Reconstruction? In this tutorial, you will learn about 3D Gaussian Splatting. With that, the resulting 3D models often lack detailed textures, colors, and other essential information. Join me in computervision mastery. Thats not the case.
Summary: Autoencoders are powerful neural networks used for deeplearning. Their applications include dimensionality reduction, feature learning, noise reduction, and generative modelling. By the end, you’ll understand why autoencoders are essential tools in DeepLearning and how they can be applied across different fields.
Multimodal Capabilities in Detail Configuring Your Development Environment Project Structure Implementing the Multimodal Chatbot Setting Up the Utilities (utils.py) Designing the Chatbot Logic (chatbot.py) Building the Interface (app.py) Summary Citation Information Building a Multimodal Gradio Chatbot with Llama 3.2 Introducing Llama 3.2
Summary: DeepLearning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction DeepLearning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. With a projected market growth from USD 6.4
While artificial intelligence (AI), machine learning (ML), deeplearning and neural networks are related technologies, the terms are often used interchangeably, which frequently leads to confusion about their differences. How do artificial intelligence, machine learning, deeplearning and neural networks relate to each other?
To learn how to master YOLO11 and harness its capabilities for various computervision tasks , just keep reading. With improvements in its design and training techniques, YOLO11 can handle a variety of computervision tasks, making it a flexible and powerful tool for developers and researchers alike.
For more information, head over to Fine Tune PaliGemma with QLoRA for Visual Question Answering. The debug=True option enables debugging information, which can be helpful for troubleshooting. Document Understanding involves analyzing images that contain both visual elements and textual information. We begin by using cv2.VideoCapture(video_path)
Artificial intelligence (AI) research has increasingly focused on enhancing the efficiency & scalability of deeplearning models. These models have revolutionized natural language processing, computervision, and data analytics but have significant computational challenges.
This article covers an extensive list of novel, valuable computervision applications across all industries. Find the best computervision projects, computervision ideas, and high-value use cases in the market right now. provides Viso Suite , the world’s only end-to-end ComputerVision Platform.
This article was published as a part of the Data Science Blogathon “You can have data without information but you cannot have information without data” – Daniel Keys Moran Introduction If you are here then you might be already interested in Machine Learning or DeepLearning so I need not explain what it is?
These word vectors are trained from Twitter data making them semantically rich in information. Do you think learningcomputervision and deeplearning has to be time-consuming, overwhelming, and complicated? Join me in computervision mastery. Citation Information Mangla, P. Thakur, eds.,
Over the past decade, advancements in deeplearning and artificial intelligence have driven significant strides in self-driving vehicle technology. These technologies have revolutionized computervision, robotics, and natural language processing and played a pivotal role in the autonomous driving revolution.
These deeplearning algorithms get data from the gyroscope and accelerometer inside a wearable device ideally worn around the neck or at the hip to monitor speed and angular changes across three dimensions.
AI comprises numerous technologies like deeplearning, machine learning, natural language processing, and computervision. With the help of these technologies, AI is now capable of learning, reasoning, and processing complex data. This improvement has led to a significant advancement in medical diagnosis.
LVMs are a new category of AI models specifically designed for analyzing and interpreting visual information, such as images and videos, on a large scale, with impressive accuracy. Moreover, LVMs enable insightful analytics by extracting and synthesizing information from diverse visual data sources, including images, videos, and text.
This technique is more useful in the field of computervision and natural language processing (NLP) because of large data that has semantic information. What is the issue of training deeplearning models from scratch? It needs a lot of labeled data that takes more time and effort if not available publicly.It
In 2024, the landscape of Python libraries for machine learning and deeplearning continues to evolve, integrating more advanced features and offering more efficient and easier ways to build, train, and deploy models. PyTorch PyTorch is a widely used open-source machine learning library based on the Torch library.
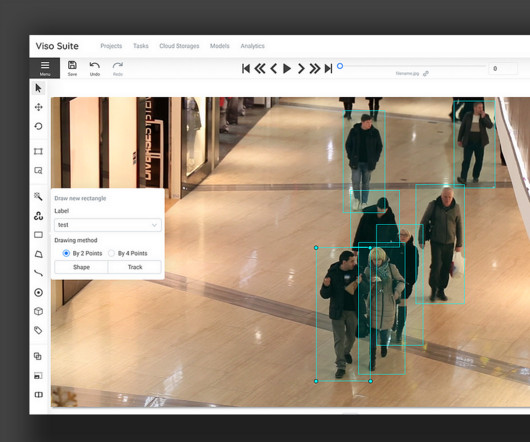
The computervision annotation tool CVAT provides a powerful solution for image annotation in computervision. Computationalvision is the research field that uses machines to collect and analyze images and videos to extract information from processed visual data. Get a demo or the whitepaper.
In the context of OpenAI CLIP, embeddings are vectors that encode semantic information about images and text in a shared representation space. Do you think learningcomputervision and deeplearning has to be time-consuming, overwhelming, and complicated? Join me in computervision mastery.
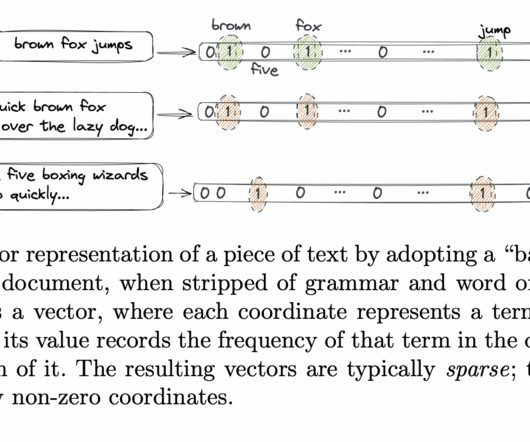
Artificial Intelligence has witnessed a revolution, largely due to advancements in deeplearning. This shift is driven by neural networks that learn through self-supervision, bolstered by specialized hardware. Before the advent of deeplearning, data representation often involved manually curated feature vectors.
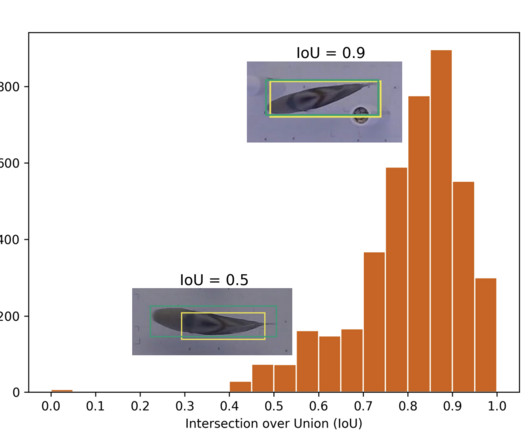
Addressing these challenges, a UK-based research team introduced a hybrid method, merging deeplearning and traditional computervision techniques to enhance tracking accuracy for fish in complex experiments. The deeplearning part involves the use of object detection and tracking.
Deeplearning architectures have revolutionized the field of artificial intelligence, offering innovative solutions for complex problems across various domains, including computervision, natural language processing, speech recognition, and generative models.
What I’ve learned from the most popular DL course Photo by Sincerely Media on Unsplash I’ve recently finished the Practical DeepLearning Course from Fast.AI. So you definitely can trust his expertise in Machine Learning and DeepLearning. Luckily, there’s a handy tool to pick up DeepLearning Architecture.
Figures present another challenge captions might be separated from their images, and important visual information gets lost in translation. Traditional systems frequently misinterpret these elements, turning a simple equation into gibberish or losing critical technical information. Interpret visual scenes to answer questions.
Traditional AI methods have been designed to extract information from objects encoded by somewhat “rigid” structures. The goal was to use AI models to predict the antibiotic activity of molecules by learning their graph representations, this way capturing their potential antibiotic activity.
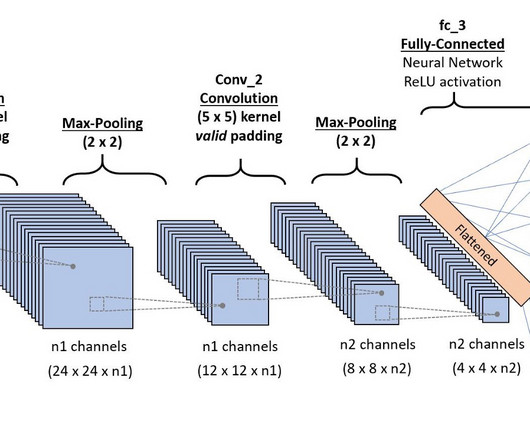
Introduction Computervision is a field of A.I. that deals with deriving meaningful information from images. Since 2012 after convolutional neural networks(CNN) were introduced, we moved away from handcrafted features to an end-to-end approach using deep neural networks. These are easy to develop […].
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. The reasons for this range from wrongly connected model components to misconfigured optimizers.
cryptopolitan.com Applied use cases Alluxio rolls out new filesystem built for deeplearning Alluxio Enterprise AI is aimed at data-intensive deeplearning applications such as generative AI, computervision, natural language processing, large language models and high-performance data analytics. voxeurop.eu
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite.
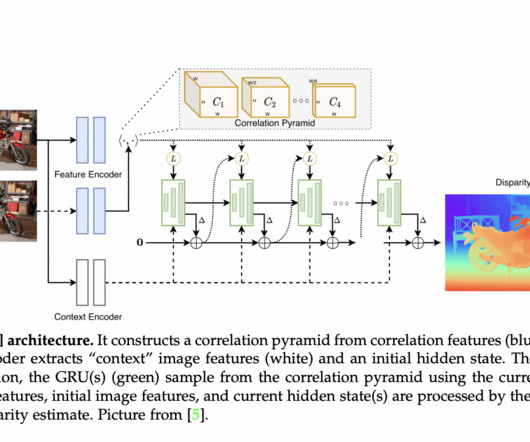
A fundamental topic in computervision for nearly half a century, stereo matching involves calculating dense disparity maps from two corrected pictures. According to their cost-volume computation and optimization methodologies, existing surveys categorize end-to-end architectures into 2D and 3D classes. Check out the Paper.
Computervision tasks like autonomous driving, object segmentation, and scene analysis can negatively impact this effect, which blurs or stretches the image’s object contours, diminishing their clarity and detail. There has been a meteoric rise in the use of deeplearning in image processing in the past several years.
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
In the field of computervision, supervised learning and unsupervised learning are two of the most important concepts. In this guide, we will explore the differences and when to use supervised or unsupervised learning for computervision tasks. What is supervised learning? About us: Viso.ai
Unlike conventional voice recognition systems, FreshAI employs deeplearning models trained on thousands of real-world customer interactions. There is even the potential for computervision AI to help manage drive-thru traffic by tracking cars in real-time, reducing wait times, and keeping things running smoothly.
Course information: 86+ total classes 115+ hours hours of on-demand code walkthrough videos Last updated: March 2025 4.84 (128 Ratings) 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computervision and deeplearning. Join me in computervision mastery.
Pose estimation is a fundamental task in computervision and artificial intelligence (AI) that involves detecting and tracking the position and orientation of human body parts in images or videos. provides the leading end-to-end ComputerVision Platform Viso Suite. Get a demo for your organization.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content