This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, in industrial applications, the main bottleneck in efficient document retrieval often lies in the dataingestion pipeline rather than the embedding model’s performance. Optimizing this pipeline is crucial for extracting meaningful data that aligns with the capabilities of advanced retrieval systems.
Mani Khanuja is a Tech Lead – Generative AI Specialist, author of the book Applied Machine Learning and High Performance Computing on AWS , and a member of the Board of Directors for Women in Manufacturing Education Foundation Board.
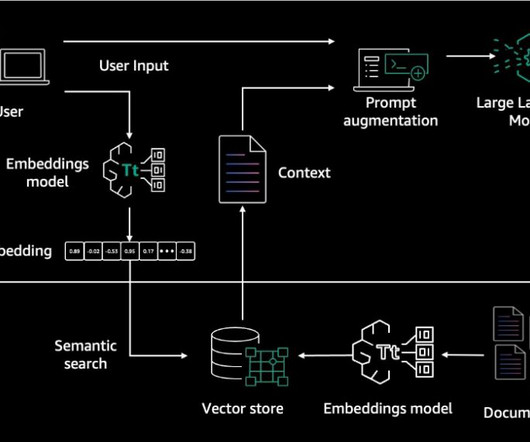
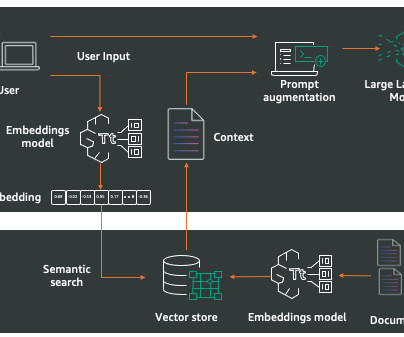
RAG architecture involves two key workflows: data preprocessing through ingestion, and text generation using enhanced context. The dataingestion workflow uses LLMs to create embedding vectors that represent semantic meaning of texts. It offers fully managed dataingestion and text generation workflows.
Choose Sync to initiate the dataingestion job. After data synchronization is complete, select the desired FM to use for retrieval and generation (it requires model access to be granted to this FM in Amazon Bedrock before using). On the Amazon Bedrock console, navigate to the created knowledge base.
Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation. She leads machine learning projects in various domains such as computervision, natural language processing, and generative AI.
You should see two pipelines created: car-data-ingestion-pipeline and car-data-aggregated-ingestion-pipeline. You should see two pipelines created: car-data-ingestion-pipeline and car-data-aggregated-ingestion-pipeline. Choose the car-data-ingestion-pipeline.
Elymsyr wants to develop new projects to improve their ML, RL, computervision, and co-working skills. Building an Enterprise Data Lake with Snowflake Data Cloud & Azure using the SDLS Framework. Dianasanimals is looking for students to test several free chatbots. If this sounds interesting, reach out in the thread!
Manage data through standard methods of dataingestion and use Enriching LLMs with new data is imperative for LLMs to provide more contextual answers without the need for extensive fine-tuning or the overhead of building a specific corporate LLM.
For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds. He is passionate about computervision, NLP, generative AI, and MLOps. SageMaker Feature Store ensures that offline and online datasets remain in sync. Outside of work, he enjoys reading and traveling.
The dependencies template deploys a role to be used by Lambda and another for Step Functions, a workflow management service that will coordinate the tasks of dataingestion and processing, as well as predictor training and inference using Forecast. IAM roles define permissions within AWS for users and services.
Creates two indexes for text ( ooc_text ) and kNN embedding search ( ooc_knn ) and bulk uploads data from the combined dataframe through the ingest_data_into_ops function. This dataingestion process takes 5–10 minutes and can be monitored through the Amazon CloudWatch logs on the Monitoring tab of the Lambda function.
Earth.com’s leadership team recognized the vast potential of EarthSnap and set out to create an application that utilizes the latest deep learning (DL) architectures for computervision (CV). The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
Additionally, the solution must handle high data volumes with low latency and high throughput. This includes dataingestion, data preprocessing, converting documents to document types accepted by Amazon Textract, handling incoming document streams, routing documents by type, and implementing access control and retention policies.
For a deeper dive into end-to-end solutions that cover dataingestion, classification, extraction, enrichment, verification and validation, and consumption, refer to Intelligent document processing with AWS AI services: Part 1 and Part 2. His focus is natural language processing and computervision.
Enhance IDP with Amazon Comprehend Flywheel and Amazon Textract Custom Queries Leverage the Amazon Comprehend flywheel for a streamlined ML process, from dataingestion to deployment. By centralizing datasets within the flywheel’s dedicated Amazon S3 data lake, you ensure efficient data management.
Stable Diffusion: A New Frontier for Text-to-Image Paradigm Sandeep Singh | Head of Applied AI/ComputerVision | Beans.ai Don’t miss this chance to learn from some of the data practitioners defining the future of the industry. Sign me up!
Personas associated with this phase may be primarily Infrastructure Team but may also include all of Data Engineers, Machine Learning Engineers, and Data Scientists. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
1 DataIngestion (e.g., Apache Kafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The next section delves into these architectural patterns, exploring how they are leveraged in machine learning pipelines to streamline dataingestion, processing, model training, and deployment.
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. He focuses on Deep learning including NLP and ComputerVision domains.
SageMaker Canvas supports multiple ML modalities and problem types, catering to a wide range of use cases based on data types, such as tabular data (our focus in this post), computervision, natural language processing, and document analysis.
The major considerations to make when planning an ML platform across special industry verticals include: Data type : For the different types of use cases your team works on, what’s the most prevalent data type, and can your ML platform be flexible enough to handle them? Best Tools To Do ML Model Serving.
Retrieval Augmented Generation Amazon Bedrock Knowledge Bases gives FMs contextual information from your private data sources for RAG to deliver more relevant, accurate, and customized responses. The RAG workflow consists of two key components: dataingestion and text generation.
The traditional way to solve these problems is to use computervision machine learning (ML) models to classify the damage and its severity and complement with regression models that predict numerical outcomes based on input features like the make and model of the car, damage severity, damaged part, and more.
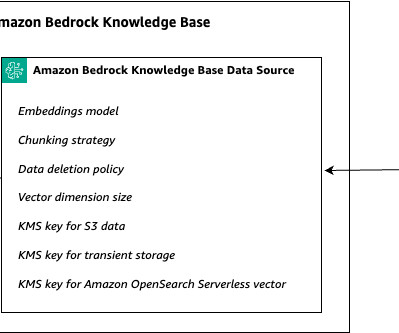
In the context of RAG systems, tenants might have varying requirements for dataingestion frequency, document chunking strategy, or vector search configuration. Single knowledge base A single knowledge base is created to handle the dataingestion for your tenants.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content