This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
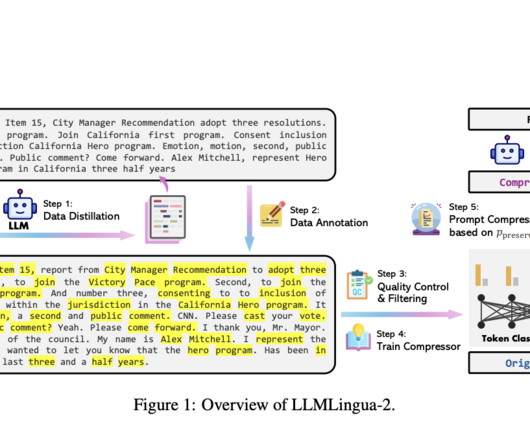
Researchers have introduced a novel approach called natural language embedded programs (NLEPs) to improve the numerical and symbolic reasoning capabilities of largelanguagemodels (LLMs).
In computationallinguistics and artificial intelligence, researchers continually strive to optimize the performance of largelanguagemodels (LLMs). These models, renowned for their capacity to process a vast array of language-related tasks, face significant challenges due to their expansive size.
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: largelanguagemodels (LLMs). These feats of computationallinguistics have redefined our understanding of machine-human interactions and paved the way for brand-new digital solutions and communications.
Quantization, a method integral to computationallinguistics, is essential for managing the vast computational demands of deploying largelanguagemodels (LLMs). It simplifies data, thereby facilitating quicker computations and more efficient model performance. Check out the Paper.
With the significant advancement in the fields of Artificial Intelligence (AI) and Natural Language Processing (NLP), LargeLanguageModels (LLMs) like GPT have gained attention for producing fluent text without explicitly built grammar or semantic modules. If you like our work, you will love our newsletter.
The advent of largelanguagemodels (LLMs) has sparked significant interest among the public, particularly with the emergence of ChatGPT. These models, which are trained on extensive amounts of data, can learn in context, even with minimal examples.
Therefore, it is important to analyze and understand the linguistic features of effective chatbot prompts for education. In this paper, we present a computationallinguistic analysis of chatbot prompts used for education.
What are LargeLanguageModels (LLMs)? In generative AI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a LargeLanguageModel (LLM).
One persistent challenge is the translation of low-resource languages, which often need more substantial data for training robust models. Traditional translation models, primarily based on largelanguagemodels (LLMs), perform well with languages abundant in data but need help with underrepresented languages.
Language Agents represent a transformative advancement in computationallinguistics. They leverage largelanguagemodels (LLMs) to interact with and process information from the external world.
The emergence of LargeLanguageModels (LLMs) has notably enhanced the domain of computationallinguistics, particularly in multi-agent systems. Despite the significant advancements, developing multi-agent applications remains a complex endeavor.
In the last couple of years, LargeLanguageModels (LLMs) such as ChatGPT, T5 and LaMDA have developed amazing skills to produce human language. We are quick to attribute intelligence to models and algorithms, but how much of this is emulation, and how much is really reminiscent of the rich language capability of humans?
The advent of largelanguagemodels (LLMs) has ushered in a new era in computationallinguistics, significantly extending the frontier beyond traditional natural language processing to encompass a broad spectrum of general tasks.
Computationallinguistics focuses on developing advanced languagemodels capable of understanding and generating human language. This dynamic field integrates the latest in machine learning and artificial intelligence, striving to create models that grasp the intricacies of language.
Tokenization is essential in computationallinguistics, particularly in the training and functionality of largelanguagemodels (LLMs). This process involves dissecting text into manageable pieces or tokens, which is foundational for model training and operations.
The team has proposed a truly innovative approach to address these challenges: a data distillation procedure designed to distill essential information from largelanguagemodels (LLMs) without compromising crucial details. Check out the Paper. All credit for this research goes to the researchers of this project.
Research in computationallinguistics continues to explore how largelanguagemodels (LLMs) can be adapted to integrate new knowledge without compromising the integrity of existing information.
The development of LargeLanguageModels (LLMs), such as GPT and BERT, represents a remarkable leap in computationallinguistics. Training these models, however, is challenging.
It is probably good to also to mention that I wrote all of these summaries myself and they are not generated by any languagemodels. Are Emergent Abilities of LargeLanguageModels a Mirage? Do LargeLanguageModels Latently Perform Multi-Hop Reasoning? Here we go. NeurIPS 2023. ArXiv 2024.
Its innovative techniques and optimizations make it a standout performer, capable of handling large-scale language understanding tasks with remarkable speed and reliability. As technology advances, solutions like Marlin play an important role in pushing the boundaries of what’s possible in computationallinguistics.
Rudner Receives Major Grant to Study Uncertainty Quantification in Large LanguageModels Largelanguagemodels (LLMs) often express high confidence even when providing incorrect answers. CDS Faculty Member Tim G. This fundamental challenge in AI reliability motivated CDS faculty member Tim G.
In the past year, the team has increasingly focused on building artificial intelligence (AI) capabilities powered by largelanguagemodels (LLMs) to improve productivity and experience for users. Karthik Raghunathan is the Senior Director for Speech, Language, and Video AI in the Webex Collaboration AI Group.
In computationallinguistics, much research focuses on how languagemodels handle and interpret extensive textual data. These models are crucial for tasks that require identifying and extracting specific information from large volumes of text, presenting a considerable challenge in ensuring accuracy and efficiency.
In particular, we fine-tune a re-ranker model using only the relevant feedback from each query and obtained large performance gains in multiple domains, including news and COVID. Lastly, we are currently working on integrating recent works on LargeLanguageModels such as ChatGPT. Euro) in 2021.
Given the intricate nature of metaphors and their reliance on context and background knowledge, MCI presents a unique challenge in computationallinguistics. This framework leverages the power of largelanguagemodels (LLMs) like ChatGPT to improve the accuracy and efficiency of MCI.
This innovative tool was presented at the 2023 Association for ComputationalLinguistics (ACL) conference. Its primary purpose is quantifying and identifying biases within advanced generative models, like Stable Diffusion, which can magnify existing prejudices in the images generated.
Posted by Malaya Jules, Program Manager, Google This week, the 61st annual meeting of the Association for ComputationalLinguistics (ACL), a premier conference covering a broad spectrum of research areas that are concerned with computational approaches to natural language, is taking place online.
REGISTER NOW Building upon the exponential advancements in Deep Learning, Generative AI has attained mastery in Natural Language Processing. The driving force behind Generative AI and LargeLanguageModels (LLMs) is LanguageModeling, a Natural Language Processing technique that predicts the next word in a sequence of words.
Largelanguagemodels such as ChatGPT process and generate text sequences by first splitting the text into smaller units called tokens. Language Disparity in Natural Language Processing This digital divide in natural language processing (NLP) is an active area of research. Shijie Wu and Mark Dredze.
The 60th Annual Meeting of the Association for ComputationalLinguistics (ACL) 2022 is taking place May 22nd - May 27th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below.
In here, the distinction is that base models want to complete documents(with a given context) where assistant models can be used/tricked into performing tasks with prompt engineering. Largelanguagemodels (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean.
Natural Language Processing (NLP) NLP is subset of Artificial Intelligence that is concerned with helping machines to understand the human language. It combines techniques from computationallinguistics, probabilistic modeling, deep learning to make computers intelligent enough to grasp the context and the intent of the language.
Cisco’s Webex AI (WxAI) team plays a crucial role in enhancing these products with AI-driven features and functionalities, using largelanguagemodels (LLMs) to improve user productivity and experiences. Karthik Raghunathan is the Senior Director for Speech, Language, and Video AI in the Webex Collaboration AI Group.
Increasingly capable foundation models are being released continuously, with largelanguagemodels (LLMs) being one of the most visible model classes. LLMs are models composed of billions of parameters trained on extensive corpora of text, up to hundreds of billions or even a trillion tokens.
The 49th Annual Meeting of the Association for ComputationalLinguistics (ACL 2011). The post Testing the Robustness of LSTM-Based Sentiment Analysis Models appeared first on John Snow Labs. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. Learning Word Vectors for Sentiment Analysis.
Cross-lingual performance prediction [42] could be used to estimate performance for a broader set of languages. Multilingual vs English-centric models Let us now take a step back and look at recent largelanguagemodels in NLP in general. Computationallinguistics, 47(2), 255-308. Winata, G.
One of the most notable applications of largelanguagemodels this year was code generation, which saw with Codex [79] its first integration into a major product as part of GitHub Copilot. Other advances in pre-training models ranged from better pre-training objectives [80] [81] to scaling experiments [82] [83].
That ranges all the way from analytical and computationallinguists to applied research scientists, machine learning engineers, data scientists, product managers, designers, UX researchers, and so on. It’s clear how technology can help us in the advent of generative largelanguagemodels.
That ranges all the way from analytical and computationallinguists to applied research scientists, machine learning engineers, data scientists, product managers, designers, UX researchers, and so on. It’s clear how technology can help us in the advent of generative largelanguagemodels.
One of the best-known critiques of AI largelanguagemodels, or LLMs, for example, compares AI’s lack of language understanding to that of an animal: the concept of the “stochastic parrot,” which refers to how chatbots, not having minds, spit out language based on probabilistic models with no regard for meaning.
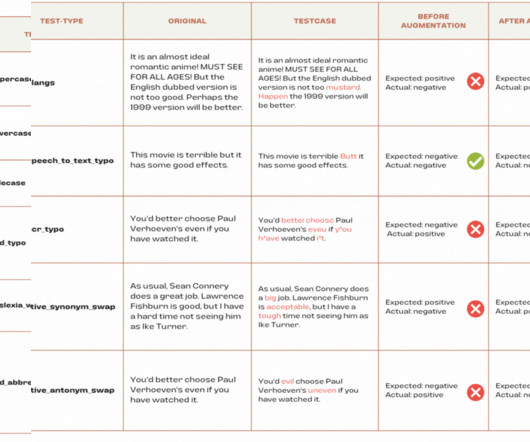
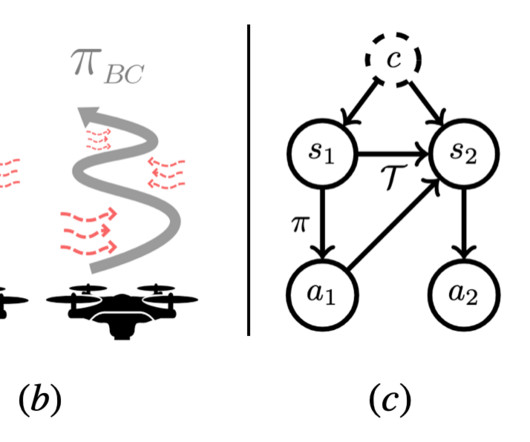
Illustration depicting the process of a human and a largelanguagemodel working together to find failure cases in a (not necessarily different) largelanguagemodel. Trends Human Computer Interaction. [2] Adaptive Testing and Debugging of NLP Models. 2] Marco Tulio Ribeiro and Scott Lundberg.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content