This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It combines statistics and mathematics with computationallinguistics. Allow me to provide an example from the official documentation: import nltk sentence = """At eight o'clock on Thursday morning… Arthur didn't feel very good."""
In computationallinguistics, much research focuses on how language models handle and interpret extensive textual data. This issue is particularly pronounced in tasks where the model needs to discern specific details from large datasets or long documents.
The goal of QA is to create models that can understand the nuances of a question and some given evidence documents to provide an accurate and concise answer. Information retrieval is a key aspect in question answering since it is used to obtain the documents to extract the answers to the given questions. Haritz Puerto is a Ph.D.
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval João Coelho, Bruno Martins, João Magalhães, Jamie Callan, Chenyan Xiong. link] The paper investigates positional biases when encoding long documents into a vector for similarity-based retrieval. ComputationalLinguistics 2022. ArXiv 2024.
It’s Institute of ComputationalLinguistics , which includes the Phonetics Laboratory , lead by Martin Volk and Volker Dellwo, as well as the URPP Language and Space perform research in NLP topics, such as machine translation, sentiment analysis, speech recognition and dialect detection.
The test data consists of three different paragraphs, one on the Australian city of Adelaide from the first two paragraphs of it Wikipedia page , one regarding Amazon Elastic Block Store (Amazon EBS) from the Amazon EBS documentation , and one of Amazon Comprehend from the Amazon Comprehend documentation.
Posted by Malaya Jules, Program Manager, Google This week, the 61st annual meeting of the Association for ComputationalLinguistics (ACL), a premier conference covering a broad spectrum of research areas that are concerned with computational approaches to natural language, is taking place online.
Picture by Anna Nekrashevich , Pexels.com Introduction Sentiment analysis is a natural language processing technique which identifies and extracts subjective information from source materials using computationallinguistics and text analysis. Create a document assembler document = DocumentAssembler().setInputCol("text").setOutputCol("document")
Machine translation is a subfield of computationallinguistics that uses software to translate text or speech from one language to another. An essential resource in SMT and NMT systems is parallel corpora , sets of documents with the same content in two or more languages. What kind of documents do you need to translate?
The 60th Annual Meeting of the Association for ComputationalLinguistics (ACL) 2022 is taking place May 22nd - May 27th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below.
Hundreds of researchers, students, recruiters, and business professionals came to Brussels this November to learn about recent advances, and share their own findings, in computationallinguistics and Natural Language Processing (NLP).
Nuance Nuance is developing intelligent systems for medical documentation, as well as mobile and automotive sectors. From time to time the company hires NLP-related specialists for their office in Berlin. For more information check their jobs section.
Natural Language Processing (NLP) plays a crucial role in advancing research in various fields, such as computationallinguistics, computer science, and artificial intelligence. Supported tools include a Name finder, Tokenizer, Document categorization, POS tagger, Parser, Chunker, and Sentence detector.
In here, the distinction is that base models want to complete documents(with a given context) where assistant models can be used/tricked into performing tasks with prompt engineering. Natural language processing (NLP) or computationallinguistics is one of the most important technologies of the information age.
OpenAI themselves have included some considerations for education in their ChatGPT documentation, acknowledging the chatbot’s use in academic dishonesty. A Chatbot Detector could pick up on the writing style of a human (since a human re-wrote the chatbot answer) and classify the document as human-written. Attention is not Explanation.
Open-Retrieval QA vs Reading Comprehension Open-retrieval QA focuses on the most general setting where given a question we first need to retrieve relevant documents from a large corpus such as Wikipedia. We then process these documents to identify the relevant answer as can be seen below. XQA ( Liu et al., TyDi QA ( Clark et al.,
As we’re moving into a phase with more options for contributions, we want to encourage them where they make the biggest difference: language data, interoperation, tests and documentation. This includes everything you say and do – from documentation you write to issues you answer. to adding tokenizer exceptions for Bengali or Hebrew.
Initiatives The Association for ComputationalLinguistics (ACL) has emphasized the importance of language diversity, with a special theme track at the main ACL 2022 conference on this topic. In Findings of the Association for ComputationalLinguistics: ACL 2022 (pp. Computationallinguistics, 47(2), 255-308.
Adriane is a computationallinguist who has been engaged in research since 2005, completing her PhD in 2012. Many of you might recognize Sebastián’s name as the author of FastAPI , the new Python library for modern REST APIs that’s quickly becoming the industry standard and is known for its incredible technical documentation.
Later approaches then scaled these representations to sentences and documents ( Le and Mikolov, 2014 ; Conneau et al., Early approaches such as word2vec ( Mikolov et al., 2013 ) learned a single representation for every word independent of its context. 2017 ; Peters et al.,
Transactions of the Association for ComputationalLinguistics, 9, 978–994. Transactions of the Association for ComputationalLinguistics, 9, 570–585. End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering. Documenting the English Colossal Clean Crawled Corpus.
The initiative focuses on making ComputationalLinguistics (CL) research accessible in 60 languages and across all modalities, including text/speech/sign language translation, closed captioning, and dubbing. We make practical recommendations such as documenting dialect, style, and register information in datasets.
In the same way that a physicist might assume a frictionless surface or a spherical cow , sometimes it’s useful for computationallinguists to assume projective trees and context-free grammars. The language-specific part-of-speech tags use the Stuttgart-Tübingen Tag Set (STTS) (document in German). It’s a simplifying assumption.
You expect the search engine to retrieve the following documents: Figure 1: search results for the query "actor Scientology" that don't directly involve the word "actor" since they are talking about a certain actor (Tom Cruise or John Travolta) and Scientology. However, what if these documents don't contain the word actor ?
Apart from averaging the word vectors of all the words within a paper, there are also specialised approaches to learn embeddings for whole documents. Both LSA and doc2vec allow us to take documents of text and embed them in a vector space. In our case, we deliberately use the whole full-text of an ArXiv submission as the document.
language models that promise to elevate the standard of AI interactivity and computationallinguistics. Its context window is now expanded to 16K, allowing for a more robust understanding of longer conversations and documents. Turbo, an intermediary yet powerful model, also receives significant enhancements.
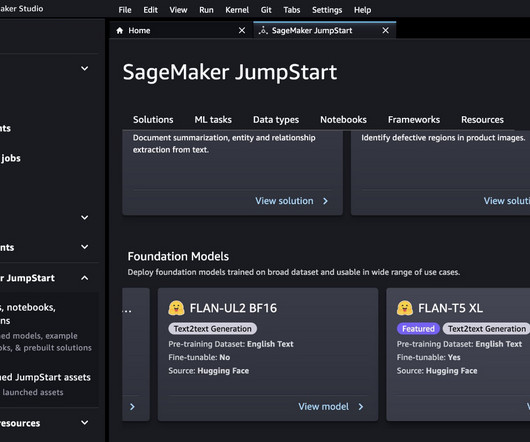
Improved documentation for generative AI – Recognizing the importance of comprehensive documentation to support the growing generative AI ecosystem, Cisco collaborated with the AWS team to enhance the SageMaker documentation.
The 57th Annual Meeting of the Association for ComputationalLinguistics (ACL 2019) is starting this week in Florence, Italy. And, by the way, you can embed not only words, but also other things such as senses, sentences and whole documents. Neural Networks are the workhorse of Deep Learning (cf.
Association for ComputationalLinguistics (ACL)" ) or considering all the word sequences that start with these initials, and deciding on the correct one using rules or a machine-learning based solution. The problem starts when we want to capture the semantics of a multi-word expression (or a sentence, or a document).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content