This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
They must demonstrate tangible ROI from AI investments while navigating challenges around dataquality and regulatory uncertainty. After all, isnt ensuring strong data governance a core principle that the EU AI Act is built upon? To adapt, companies must prioritise strengthening their approach to dataquality.
Since the emergence of ChatGPT, the world has entered an AI boom cycle. Rethinking AI’s Pace Throughout History Although it feels like the buzz behind AI began when OpenAI launched ChatGPT in 2022, the origin of artificial intelligence and natural language processing (NLPs) dates back decades. Then came ChatGPT.
ChatGPT, for example, amassed 100 million users in a mere two months. “If Addressing this gap will require a multi-faceted approach including grappling with issues related to dataquality and ensuring that AI systems are built on reliable, unbiased, and representative datasets.
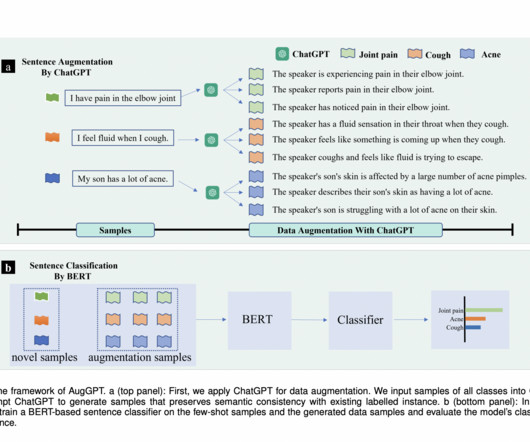
Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges. While these methods enhance model capabilities through architectural designs and pre-trained language models, dataquality and quantity limitations persist. This process enhances data diversity.
According to CNN, some companies imposed internal bans on generative AI tools while they seek to better understand the technology and many have also blocked the use of internal ChatGPT. The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions.
But it means that companies must overcome the challenges experienced so far in GenAII projects, including: Poor dataquality: GenAI ends up only being as good as the data it uses, and many companies still dont trust their data.
It is designed to automatically detect and fix data issues that can negatively impact the performance of machine learning models, including language models prone to hallucinations. They can also identify dataquality issues in text, image, and tabular datasets. Automatically detects mislabeled data. Enhances dataquality.
[Download now] rws.com In The News OpenAI forms safety council as it trains latest AI model OpenAI says it is setting up a safety and security committee and has begun training a new AI model to supplant the GPT-4 system that underpins its ChatGPT chatbot. arxiv.org Sponsor Need Data to Train AI?
Indeed, this perspective characterized much of the coverage around generative AI as the release of ChatGPT and other tools mainstreamed the technology in 2022, with some analysts predicting that we were on the brink of a revolution that would reshape the future of work. In this context, dataquality often outweighs quantity.
Today, ChatGPT and other LLMs can perform cognitive tasks involving natural language that were unimaginable a few years ago. Thanks to this advantage in scalability, most companies choose this as their primary strategy for doing RLHF, as OpenAI did with ChatGPT.
After all, OpenAI’s ChatGPT reached 100 million users in the first two months , making it the fastest-growing consumer application adoption in history. Supply chains are, to a certain extent, well suited for the applications of generative AI, given they function on and generate massive amounts of data.
QA teams must scrutinize data and maintain transparency throughout the testing workflow to ensure fairness. For example, tools like ChatGPT can’t yet test across diverse mobile devices. Similarly, generative AI has not yet fully matured in QA, especially in mobile app testing.
For instance, ChatGPT-4o was used to produce a caption dataset, and was asked to focus on subject-object interactions (such as hands handling utensils and food), object attributes, and temporal dynamics. The Howto100M set was used for dataquality evaluation and also for image-to-video generation. 1-schnell (FLUX.1-s).
For the most part, artificial intelligence models are fairly simple, they take in data and then learn patterns from this data to generate an output. Complex large language models (LLMs) like ChatGPT and Google Bard are no different.
” RLHFs advantages Proven success: Used by OpenAI for ChatGPT, RLHF is a tried-and-true method for improving model alignment. Dataquality dependency: Success depends heavily on having high-quality preference data. A reward model learns to predict these human preferences. helpfulness, safety, and politeness).
Generative AI, in particular, has become increasingly popular, with tools like ChatGPT reaching 100 million users just two months after it launched. But these advanced AI solutions are nothing without meaningful, qualitydata. In fact, Gartner estimates that poor dataquality alone costs organizations an average $12.9
By presenting common queries from Stack Overflow to AI models like ChatGPT , they observed instances where non-existent packages were suggested. These models, like ChatGPT , are trained on diverse code repositories, including open-source projects, Stack Overflow, and other programming resources.
A practical example of this is observed in how ChatGPT operates. When you ask a question, sometimes ChatGPT presents two answers and asks you to rank which is the best. My hope for the future of AI, and its development, hinges on the recognition that AI will only be as good as the data it's trained on.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, data analysis, data cleaning, and data visualization. It facilitates exploratory Data Analysis and provides quick insights.
The well-known chatbot called ChatGPT, based on GPT architecture and developed by OpenAI, imitates humans by generating accurate and creative content, answering questions, summarizing massive textual paragraphs, and language translation. From education and finance to healthcare and media, LLMs are contributing to almost every domain.
The roadmap to LLM integration have three predominant routes: Prompting General-Purpose LLMs : Models like ChatGPT and Bard offer a low threshold for adoption with minimal upfront costs, albeit with a potential price tag in the long haul. Training Data : The essence of a language model lies in its training data.
However, there are several obstacles to overcome, especially when dealing with complex scenarios, because of the wide range of picture resolutions and the need for more training dataquality. Furthermore, LLaVA is innovative in extending instruction-tuning into multimodal situations by fusing multimodal instruction-following data.
This context provides sales teams with the insights they need on products, presentations, customer needs, industry information, data relevant to specific HCPs and their patients’ needs, along with much more. LLMs are at the heart of advanced text analysis, such as that provided by ChatGPT and other advanced AI-based engines.
Almost everybody’s played with ChatGPT, Stable Diffusion, GitHub Copilot, or Midjourney. Executive Summary We’ve never seen a technology adopted as fast as generative AI—it’s hard to believe that ChatGPT is barely a year old. AI users say that AI programming (66%) and data analysis (59%) are the most needed skills.
Cognism Cognism distinguishes itself in the AI SDR landscape through its unwavering focus on dataquality and compliance across global markets. The platform's innovative approach to AI-powered search, utilizing ChatGPT-style textual and voice prompts, simplifies the prospecting process while maintaining precision.
The method addresses the limitations of closed-source large language models (LLMs) like ChatGPT and GPT-4 regarding availability, cost, ethics, and data privacy concerns. PERsD introduced a method for customizing labeled data to student model capacity, yielding more effective learning.
This paradigm shift is driven by the recognition of the transformative potential held by smaller, custom-trained models that leverage domain-specific data. which serves as the foundation for ChatGPT. Acquiring a significant volume of domain-specific data can be challenging, especially if the data is niche or sensitive.
AI as a Tech Stack Accelerator With the popularity of tools like ChatGPT, DALL-E, and Midjourney, most of us are aware of AI’s power to assist with research, write text , and generate images within seconds. Tech stack consolidation, particularly with a strategic focus on AI integration, holds the key to addressing many of these challenges.
AI tools have seen widespread business adoption since ChatGPT's 2022 launch, with 98% of small businesses surveyed by the US Chamber of Commerce using them.
As we delve into this comprehensive analysis, it becomes evident that the landscape of AI underwent a pivotal transformation following the launch of ChatGPT in November 2022. Data Trends For most enterprises engaged in AI projects, the quality of data holds precedence over its quantity. enterprise spectrum.
The global hype cycle of AI, driven in large part by ChatGPT, is dying down and real-world artificial intelligence (AI) adoption and application are taking hold. Early adopters are reaping rewards, and AI leaders are driving significant change in their business models. Banking as a sector was quick to grasp [.]
At Aiimi, we believe that AI should give users more, not less, control over their data. AI should be a driver of dataquality and brand-new insights that genuinely help businesses make their most important decisions with confidence. But shadow AI can pose serious data security risks. Employees may have good intentions.
Customer requests are increasingly going beyond the micro tasking machine learning inputs of the past toward LLMs, and the more complex data sets required by apps like ChatGPT, Gemini and the many offshoots. And all these methodologies are in service of our guaranteed dataquality promise.
The advent of language models like GPT-4, ChatGPT, Mixtral, LLaMA, and others has further fueled rapid evolution, with each model demonstrating enhanced performance in tasks involving complex language processing.
The vision of Vicuna project is to build powerful models similar to OpenAI’s ChatGPT but with an open recipe. The rapid advancement of large language models (LLMs) has revolutionized AI systems, resulting in unprecedented levels of intelligence as seen in OpenAI's ChatGPT. This project is inspired by Llama and Alpaca.
OpenAI has wrote another blog post around data analysis capabilities of the ChatGPT. It has a number of neat capabilities that are supported by interactively and iteratively: File Integration Users can directly upload data files from cloud storage services like Google Drive and Microsoft OneDrive into ChatGPT for analysis.
Important Data Characteristics There are a several aspects to consider when using instruction tuning datasets: Data source: How was the data obtained? Most datasets have been generated using ChatGPT. Human-written examples are more expensive to obtain but are more high quality. Baize data (Xu et al.,
On the other hand, conversational AI that acts as a personal assistant can help with data input without the requirement of typing everything manually. However, it’s still learning as there are many challenges related to speech data and the dataquality it uses to get better. Originally published at [link].
” RLHFs advantages Proven success: Used by OpenAI for ChatGPT, RLHF is a tried-and-true method for improving model alignment. Dataquality dependency: Success depends heavily on having high-quality preference data. A reward model learns to predict these human preferences. helpfulness, safety, and politeness).
OpenAI released ChatGPT and the world was mesmerised. Many users started using ChatGPT as a source of information, like an alternative to Google. This characteristic of “lying with confidence” proved to be one of the biggest criticisms of ChatGPT and LLM techniques, in general.
Internal company data, like sales records or customer feedback, is also valuable. Must Check Out: How to Use ChatGPT APIs in Python: A Comprehensive Guide. Data Collection Methods There are several methods for collecting data. Surveys and questionnaires can capture primary data directly from users.
Cybersecurity Measures to Prevent Data Poisoning Bad actors always look for ways to twist AI algorithms into something more sinister, making data poisoning a serious issue that you should be prepared for.
In parallel, data selection methods, such as ChatGPT-based scoring and gradient-based clustering, have been explored to refine instruction tuning. Recent research has highlighted the challenges of polysemantic neurons encoding multiple concepts, prompting efforts to develop monosemantic neurons for better interpretability.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content