This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system.
Prompt Engineering with LLaMA-2 Difficulty Level: Beginner This course covers the prompt engineering techniques that enhance the capabilities of large language models (LLMs) like LLaMA-2. It includes over 20 hands-on projects to gain practical experience in LLMOps, such as deploying models, creating prompts, and building chatbots.
In this example, the MLengineering team is borrowing 5 GPUs for their training task With SageMaker HyperPod, you can additionally set up observability tools of your choice. metadata: name: job-name namespace: hyperpod-ns-researchers labels: kueue.x-k8s.io/queue-name: queue-name: hyperpod-ns-researchers-localqueue kueue.x-k8s.io/priority-class:
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. An experiment collects multiple runs with the same objective.
Generative AI chatbots have gained notoriety for their ability to imitate human intellect. Finally, we use a QnABot to provide a user interface for our chatbot. This enables you to begin machine learning (ML) quickly. A session stores metadata and application-specific data known as session attributes.
A chatbot for taking notes, an editor for creating images from text, and a tool for summarising customer comments can all be made with a basic understanding of programming and a couple of hours. In the actual world, machine learning (ML) systems can embed issues like societal prejudices and safety worries.
After the completion of the research phase, the data scientists need to collaborate with MLengineers to create automations for building (ML pipelines) and deploying models into production using CI/CD pipelines. Main use cases are around human-like chatbots, summarization, or other content creation such as programming code.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. The following diagram illustrates the end-to-end architecture, consisting of the metadata API layer, ingestion pipeline, embedding generation workflow, and frontend UI.
The workflow consists of the following steps: Either a user through a chatbot UI or an automated process issues a prompt and requests a response from the LLM-based application. The agent returns the LLM response to the chatbot UI or the automated process. The LLM response is passed back to the agent.
Chatbot deployments : Power customer service chatbots that can handle thousands of concurrent real-time conversations with consistently low latency, delivering the quality of a larger model but at significantly lower operational costs. If you haven’t done this yet, see to the prerequisites section for instructions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



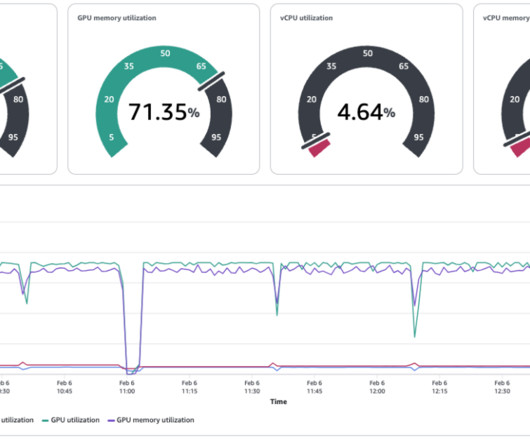


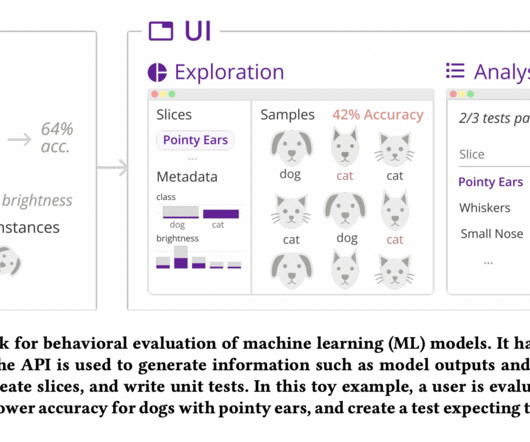










Let's personalize your content