This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system.
Prompt Engineering with LLaMA-2 Difficulty Level: Beginner This course covers the prompt engineering techniques that enhance the capabilities of large language models (LLMs) like LLaMA-2. It helps learn about LLM building blocks, training methodologies, and ethical considerations.
They enable efficient context retrieval or dynamic few-shot prompting to improve the factual accuracy of LLM-generated responses. Use re-ranking or contextual compression techniques to ensure only the most relevant information is provided to the LLM, improving response accuracy and reducing cost.
Top 5 Generative AI Integration Companies Generative AI integration into existing chatbot solutions serves to enhance the conversational abilities and overall performance of chatbots. By integrating generative AI, chatbots can generate more natural and human-like responses, allowing for a more engaging and satisfying user experience.
Recent improvements in Generative AI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval. Given the data sources, LLMs provided tools that would allow us to build a Q&A chatbot in weeks, rather than what may have taken years previously, and likely with worse performance.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
About Building LLMs for Production Generative AI and LLMs are transforming industries with their ability to understand and generate human-like text and images. However, building reliable and scalable LLM applications requires a lot of extra work and a deep understanding of various techniques and frameworks.
However, businesses can meet this challenge while providing personalized and efficient customer service with the advancements in generative artificial intelligence (generative AI) powered by large language models (LLMs). Generative AI chatbots have gained notoriety for their ability to imitate human intellect.
The practical implementation of a Large Language Model (LLM) for a bespoke application is currently difficult for the majority of individuals. It takes a lot of time and expertise to create an LLM that can generate content with high accuracy and speed for specialized domains or, perhaps, to imitate a writing style.
Stable Vicuna is an open-source RLHF chatbot based on the Vicuna and LLaMA models. StableLM is a very comprehensive suite of small and efficient open-source LLMs. Self-Aligned LLM IBM Research published a paper introducing Dromedary, a self-aligned LLM trained with minimum user supervision. Union AI raised $19.1
Awarding it the physics prize, they say, feels like handing the Nobel in Literature to a particularly eloquent chatbot( which might happen soon enough btw). MLE-Bench OpenAI published a paper detailing MLE-Bench, a benchmark for measuring AI agent’s performance in MLengineering tasks. The chemistry prize was less debate.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. MLOps engineers are responsible for providing a secure environment for data scientists and MLengineers to productionize the ML use cases.
We also review the Chatbot Arena framework. Edge 344: We discuss another of hte great papers of the year in which Google shows that the combination of LLMs and memory is enough to simulate any algorithm. 📌 MLEngineering Event: Join Meta, PepsiCo, RiotGames, Uber & more at apply(ops) apply(ops) is in two days!
Created Using Ideogram Next Week in The Sequence: Edge 377: The last issue of our series about LLM reasoning covers reinforced fine-tuning(ReFT), a technique pioneered by ByteDance. Explore Semi-Supervised Learning: Aleksandr Timashov, MLEngineer at Meta, dives into practical approaches for training models with limited labeled data.
You will also become familiar with the concept of LLM as a reasoning engine that can power your applications, paving the way to a new landscape of software development in the era of Generative AI. No-Code and Low-Code AI: A Practical Project-Driven Approach to ML Gwendolyn D.
By the end of the session, attendees will know how to transform unstructured data into reliable, queryable formats, optimize LLM outputs for cost-effective analysis, and apply structured data to answer natural-language queries. Cloning NotebookLM with Open Weights Models Niels Bantilan, Chief MLEngineer atUnion.AI Sign meup!
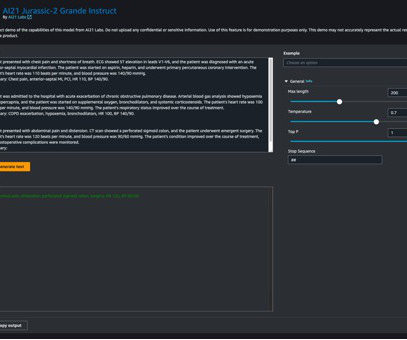
Jurassic-2 Grande Instruct is a large language model (LLM) by AI21 Labs, optimized for natural language instructions and applicable to various language tasks. Popular uses include generating marketing copy, powering chatbots, and text summarization. No MLengineering experience required. It’s as easy as that!
Generative artificial intelligence (AI) applications built around large language models (LLMs) have demonstrated the potential to create and accelerate economic value for businesses. This post provides three guided steps to architect risk management strategies while developing generative AI applications using LLMs.
🛠 Real World MLLLM Architectures at GitHub GitHub MLengineers discuss the architecture of LLMs apps —> Read more. Walmart Enterprise Chatbot Walmart discusses an architecture used to build enteprise chatbots based on LangChain, VectorDB and GPT-4 —> Read more.
We discuss how this innovation significantly reduces container download and load times during scaling events, a major bottleneck in LLM and generative AI inference. We showcase its real-world impact on various applications, from chatbots to content moderation systems. dkr.ecr.amazonaws.com/pytorch-inference:2.5.1-gpu-py311-cu124-ubuntu22.04-sagemaker",
It allows beginners and expert practitioners to develop and deploy Gen AI applications for various use cases beyond simple chatbots, including agentic, multi-agentic, Generative BI, and batch workflows. Amazon Bedrock compatibility : Karini AI integrates with Amazon Bedrock for LLM (Large Language Model) inference.
collection of multilingual large language models (LLMs), which includes pre-trained and instruction tuned generative AI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. Architecturally, the core LLM for Llama 3 and Llama 3.1 models using SageMaker JumpStart.
Read triples from the Neptune database and convert them into text format using an LLM hosted on Amazon Bedrock. A Streamlit application is hosted in Amazon Elastic Container Service (Amazon ECS) as a task, which provides a chatbot UI for users to submit queries against the knowledge base in Amazon Bedrock. account } WHERE { ?asset
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content