This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
address this challenge, Im excited to share with you a Resume Chatbot. This solution allows you to create an interactive, AI-powered chatbot that showcases your skills, experience, and knowledge in a dynamic and engaging way. Why Use a Resume Chatbot? the GitHub repository, you will find the code and a step-by-step guide.
TL;DR LangChain provides composable building blocks to create LLM-powered applications, making it an ideal framework for building RAG systems. makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. Source What is LangChain? langchain-openai== 0.0.6
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata.
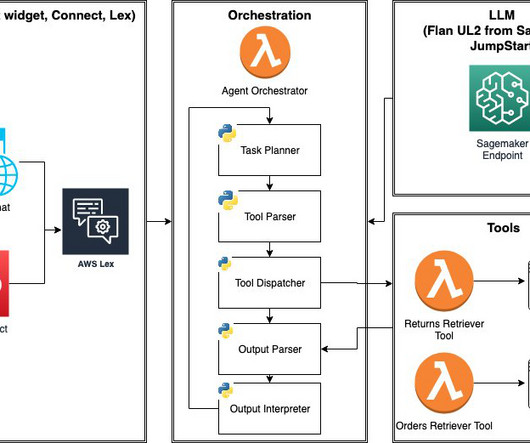
A chatbot enables field engineers to quickly access relevant information, troubleshoot issues more effectively, and share knowledge across the organization. the router would direct the query to a text-based RAG that retrieves relevant documents and uses an LLM to generate an answer based on textual information.
For instance, a medical LLM fine-tuned on clinical notes can make more accurate recommendations because it understands niche medical terminology. For instance, a medical LLM fine-tuned on clinical notes can make more accurate recommendations because it understands niche medical terminology.
This article shows you how to build a simple RAG chatbot in Python using Pinecone for the vector database and embedding model, OpenAI for the LLM, and LangChain for the RAG workflow. In such cases, the chatbot may produce responses that are fluent and confident but factually incorrect. Finally, we’ll upsert (i.e.,
For this, we create a small demo application that lets you load audio data and apply an LLM that can answer questions about your spoken data. The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) page_content) # Runner's knee. Runner's knee is a condition.
For this, we create a small demo application with an LLM-powered query engine that lets you load audio data and ask questions about your data. The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) Getting Started Create a new virtual environment: # Mac/Linux: python3 -m venv venv.
Since the inception of AWS GenAIIC in May 2023, we have witnessed high customer demand for chatbots that can extract information and generate insights from massive and often heterogeneous knowledge bases. Implementation on AWS A RAG chatbot can be set up in a matter of minutes using Amazon Bedrock Knowledge Bases. doc,pdf, or.txt).
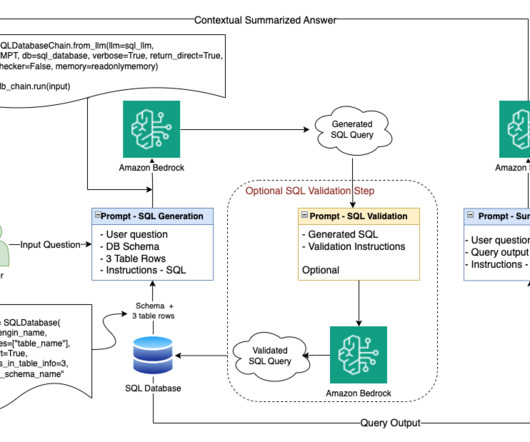
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Sonnet on Amazon Bedrock as our LLM to generate SQL queries for user inputs. This retrieved data is used as context, combined with the original prompt, to create an expanded prompt that is passed to the LLM.
Enterprises turn to Retrieval Augmented Generation (RAG) as a mainstream approach to building Q&A chatbots. The end goal was to create a chatbot that would seamlessly integrate publicly available data, along with proprietary customer-specific Q4 data, while maintaining the highest level of security and data privacy.
Retrieval Augmented Generation (RAG) is a method to augment the relevance and transparency of Large Language Model (LLM) responses. In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. as the LLM and Chroma as the retriever vector database.
Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot. The prompt guides the LLM on how to respond and interact based on the user question.
Moreover, employing an LLM for individual product categorization proved to be a costly endeavor. If it was a 4xx error, its written in the metadata of the Job. The PydanticOutputParser requires a schema to be able to parse the JSON generated by the LLM. The generated categories were often incomplete or mislabeled.
Large language model (LLM) agents are programs that extend the capabilities of standalone LLMs with 1) access to external tools (APIs, functions, webhooks, plugins, and so on), and 2) the ability to plan and execute tasks in a self-directed fashion. We conclude the post with items to consider before deploying LLM agents to production.
Chatbots powered by large-language AI models have transformed computing, and NVIDIA ChatRTX lets users interact with their local data, accelerated by NVIDIA RTX -powered Windows PCs and workstations. The latest version adds support for additional LLMs, including Gemma, the latest open, local LLM trained by Google.
Image by the author One of the major challenges in using LLMs in business is that LLMs hallucinate. How can you entrust your clients to a chatbot that can go mad and tell them something inappropriate at any moment? Thats a problem, especially given that an LLM cant be fired or held accountable.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the large language model (LLM) powering ChatGPT, have been trained on information culled from the internet. But how trustworthy is that training data?
Image by the author One of the major challenges in using LLMs in business is that LLMs hallucinate. How can you entrust your clients to a chatbot that can go mad and tell them something inappropriate at any moment? Thats a problem, especially given that an LLM cant be fired or held accountable.
Image by the author One of the major challenges in using LLMs in business is that LLMs hallucinate. How can you entrust your clients to a chatbot that can go mad and tell them something inappropriate at any moment? Thats a problem, especially given that an LLM cant be fired or held accountable.
Amazon API Gateway (WebSocket API) facilitates real-time interactions, enabling users to query the knowledge base dynamically via a chatbot or other interfaces. Additionally, large language model (LLM)-based analysis is applied to derive further insights, such as video summaries and classifications.
Large Language Models (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. However, deploying LLMs can be a challenging task due to their immense size and computational requirements.
In this post, we show you how to securely create a movie chatbot by implementing RAG with your own data using Knowledge Bases for Amazon Bedrock. Solution overview The IMDb and Box Office Mojo Movies/TV/OTT licensable data package provides a wide range of entertainment metadata, including over 1.6
We discuss the solution components to build a multimodal knowledge base, drive agentic workflow, use metadata to address hallucinations, and also share the lessons learned through the solution development using multiple large language models (LLMs) and Amazon Bedrock Knowledge Bases.
get('source') for i in result['source_documents'])}") return result['result'], set(json.loads(i.metadata['metadata']).get('source') It can be used for various applications, from content indexing to interactive chatbots. Args: query (str): The query for which an answer is sought.
Image by the author One of the major challenges in using LLMs in business is that LLMs hallucinate. How can you entrust your clients to a chatbot that can go mad and tell them something inappropriate at any moment? Thats a problem, especially given that an LLM cant be fired or held accountable.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service.
Using advanced GenAI, CreditAI by Octus is a flagship conversational chatbot that supports natural language queries and real-time data access with source attribution, significantly reducing analysis time and streamlining research workflows. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before.
To create AI assistants that are capable of having discussions grounded in specialized enterprise knowledge, we need to connect these powerful but generic LLMs to internal knowledge bases of documents. The search precision can also be improved with metadata filtering.
They used the metadata layer (schema information) over their data lake consisting of views (tables) and models (relationships) from their data reporting tool, Looker , as the source of truth. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
Retrieval Augmented Generation (RAG) is an AI framework that optimizes the output of a Large Language Model (LLM) by referencing a credible knowledge base outside of its training sources. LLMs are crucial for driving intelligent chatbots and other NLP applications.
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
Its integration into LLMs has resulted in widespread adoption, establishing RAG as a key technology in advancing chatbots and enhancing the suitability of LLMs for real-world applications. When it finds a match or multiple matches, it retrieves the related data, converts it to human-readable words, and passes it back to the LLM.
They can also introduce context and memory into LLMs by connecting and chaining LLM prompts to solve for varying use cases. Getting recommendations along with metadata makes it more convenient to provide additional context to LLMs. We are excited to launch LangChain integration.
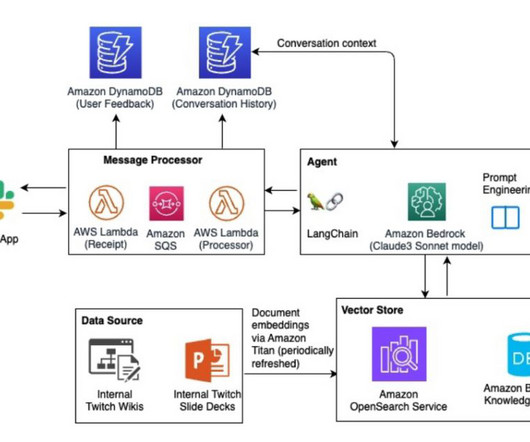
This agent invokes a Lambda function that internally calls the Anthropic Claude Sonnet large language model (LLM) on Amazon Bedrock to perform preliminary analysis on the images. The LLM generates a summary of the damage, which is sent to an SQS queue, and is subsequently reviewed by the claim adjusters.
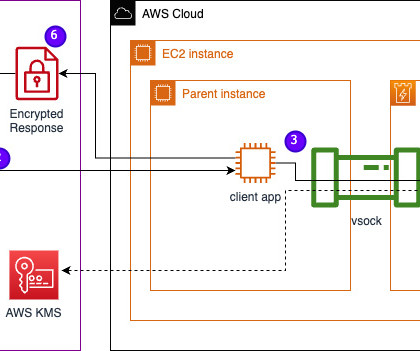
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves. LLMs are designed to understand and generate human-like language, and are used in many industries, including government, healthcare, financial, and intellectual property.
Prompt Engineering with LLaMA-2 Difficulty Level: Beginner This course covers the prompt engineering techniques that enhance the capabilities of large language models (LLMs) like LLaMA-2. Students will learn to write precise prompts, edit system messages, and incorporate prompt-response history to create AI assistant and chatbot behavior.
The applications also extend into retail, where they can enhance customer experiences through dynamic chatbots and AI assistants, and into digital marketing, where they can organize customer feedback and recommend products based on descriptions and purchase behaviors. A media metadata store keeps the promotion movie list up to date.
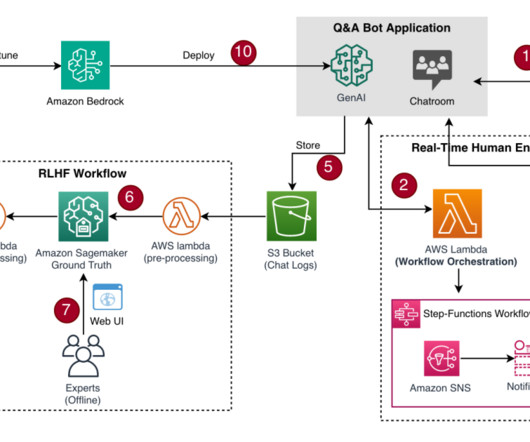
You can build such chatbots following the same process. You can easily build such chatbots following the same process. UI and the Chatbot example application to test human-workflow scenario. A second real-time human workflow is initiated as decided by the LLM. This is an offline process that is part of the RLHF.
LLMs, Chatbots medium.com In Part 3a, we’ll discuss Document Loading and Splitting and build a simple RAG pipeline. loading webpage content by URL and pandas dataframe on the fly These loaders use standard document formats comprising content and associated metadata. LangChain 101 Course (updated) LangChain 101 course sessions.
Take advantage of the current deal offered by Amazon (depending on location) to get our recent book, “Building LLMs for Production,” with 30% off right now! Featured Community post from the Discord Arwmoffat just released Manifest, a tool that lets you write a Python function and have an LLM execute it.
This approach is as important for fine-tuning Large Language Models internally as for projects where you only use LLM-as-a-service for the inference part (think of, e.g., using OpenAI API for calling GPT models). During training, we log all the model metrics and metadata automatically. Why are these elements so important?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content