This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Most of us are used to using internet chatbots like ChatGPT and DeepSeek in one of two ways: via a web browser or via their dedicated smartphone apps. Second, everything you type into the chatbot is sent to the companies servers, where it is analyzed and retained. With the apps, you can run various LLM models on your computer directly.
Researchers at Amazon have trained a new large language model (LLM) for text-to-speech that they claim exhibits “emergent” abilities. “These sentences are designed to contain challenging tasks—none of which BASE TTS is explicitly trained to perform,” explained the researchers.
Increasingly though, large datasets and the muddled pathways by which AI models generate their outputs are obscuring the explainability that hospitals and healthcare providers require to trace and prevent potential inaccuracies. In this context, explainability refers to the ability to understand any given LLM’s logic pathways.
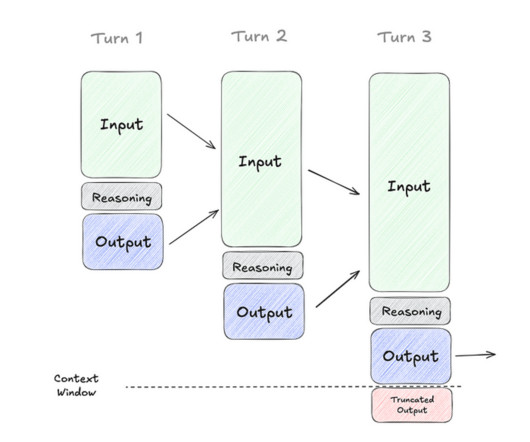
The corresponding increase in tokens per prompt can require over 100x more compute compared with a single inference pass on a traditional LLM an example of test-time scaling , aka long thinking. How Do Tokens Drive AI Economics? There are tradeoffs involved for each metric, and the right balance is dictated by use case.
It cannot discover new knowledge or explain its reasoning process. Researchers are addressing these gaps by shaping RAG into a real-time thinking machine capable of reasoning, problem-solving, and decision-making with transparent, explainable logic.
Using their extensive training data, LLM-based agents deeply understand language patterns, information, and contextual nuances. Understanding LLM-Based Agents and Their Architecture LLM-based agents enhance natural language interactions during web searches. The architecture of LLM-based agents consists of the following modules.
Whether you're leveraging OpenAI’s powerful GPT-4 or with Claude’s ethical design, the choice of LLM API could reshape the future of your business. Why LLM APIs Matter for Enterprises LLM APIs enable enterprises to access state-of-the-art AI capabilities without building and maintaining complex infrastructure.
Supplementary measures, such as additional moderation tools or using LLMs less prone to harmful content and jailbreaks, are essential for ensuring robust AI security. Can you explain the significance of jailbreaks and prompt manipulation in AI systems, and why they pose such a unique challenge?
“AI whisperers” are probing the boundaries of AI ethics by convincing well-behaved chatbots to break their own rules. “Skeleton Key is unique in that it requires multiple interactions with the AI,” explains Chenta Lee, IBM’s Chief Architect of Threat Intelligence.
LLM-Based Reasoning (GPT-4 Chain-of-Thought) A recent development in AI reasoning leverages LLMs. Natural Language Interaction: Agents can communicate their reasoning processes using natural language, providing more explainability and intuitive interfaces for human oversight.
The ever-growing presence of artificial intelligence also made itself known in the computing world, by introducing an LLM-powered Internet search tool, finding ways around AIs voracious data appetite in scientific applications, and shifting from coding copilots to fully autonomous coderssomething thats still a work in progress. Perplexity.ai
address this challenge, Im excited to share with you a Resume Chatbot. This solution allows you to create an interactive, AI-powered chatbot that showcases your skills, experience, and knowledge in a dynamic and engaging way. Why Use a Resume Chatbot? the GitHub repository, you will find the code and a step-by-step guide.
Recent progress in large language models (LLMs) has sparked interest in adapting their cognitive capacities beyond text to other modalities, such as audio. Generalization here refers to the model's ability to adapt appropriately to new, previously unseen data drawn from the same distribution as the one used to train the model.
In this video, Martin Keen briefly explains large language models, how they relate to foundation models, how they work and how they can be used to address various business problems. Proprietary LLMs are owned by a company and can only be used by customers that purchase a license. The license may restrict how the LLM can be used.
LLM-as-Judge has emerged as a powerful tool for evaluating and validating the outputs of generative models. AI judges must be scalable yet cost-effective , unbiased yet adaptable , and reliable yet explainable. AI judges must be scalable yet cost-effective , unbiased yet adaptable , and reliable yet explainable. Lets dive in.
Within this landscape, we developed an intelligent chatbot, AIDA (Applus Idiada Digital Assistant) an Amazon Bedrock powered virtual assistant serving as a versatile companion to IDIADAs workforce. This LLM model has a context window of 200,000 tokens, enabling it to manage different languages and retrieve highly accurate answers.
Can you explain the core concept and what motivated you to tackle this specific challenge in AI and data analytics? This platform unifies the experience of both LLM-based generative AI and business applications for technical and non-technical users around shared context. illumex focuses on Generative Semantic Fabric.
TL;DR: Enterprise AI teams are discovering that purely agentic approaches (dynamically chaining LLM calls) dont deliver the reliability needed for production systems. Incremental gains are harder to achieve, and organizations betting on ever-more-powerful LLMs are beginning to see diminishing returns. LLM deployments in the enterprise.
These techniques work well, but LLM-based recommender systems are shining because of traditional systems' limitations. Interpretability Challenges: Difficulty in explaining why specific recommendations are made, especially in complex hybrid models. Collaborative filtering suggests items based on similar user preferences.
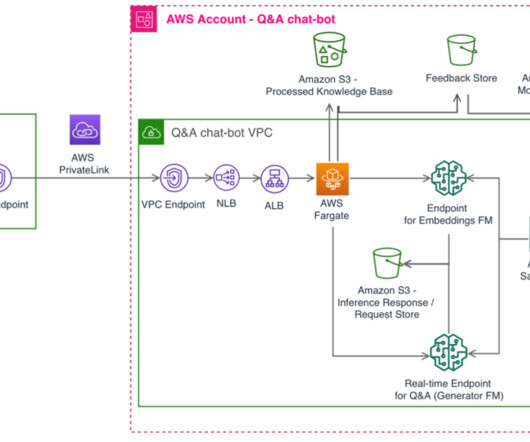
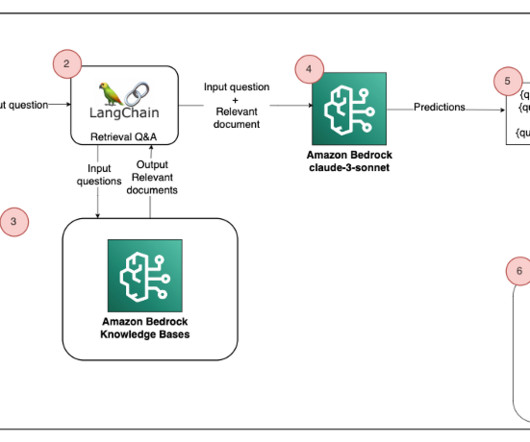
One challenge that agents face is finding the precise information when answering customers’ questions, because the diversity, volume, and complexity of healthcare’s processes (such as explaining prior authorizations) can be daunting. Then we explain how the solution uses the Retrieval Augmented Generation (RAG) pattern for its implementation.
To deal with this issue, various tools have been developed to detect and correct LLM inaccuracies. Pythia Image source Pythia uses a powerful knowledge graph and a network of interconnected information to verify the factual accuracy and coherence of LLM outputs. Cost-effective. Customizable dashboard widgets and alerts.
In this comprehensive guide, we'll explore the landscape of LLM serving, with a particular focus on vLLM (vector Language Model), a solution that's reshaping the way we deploy and interact with these powerful models. Example: Consider a relatively modest LLM with 13 billion parameters, such as LLaMA-13B.
A chatbot enables field engineers to quickly access relevant information, troubleshoot issues more effectively, and share knowledge across the organization. the router would direct the query to a text-based RAG that retrieves relevant documents and uses an LLM to generate an answer based on textual information.
Prompt tuning involves crafting and inputting a carefully designed text “prompt” into a Large Language Model (LLM). Inputting the Prompt: The prompt is fed into the LLM. Example 3: Educational Material Original Prompt: “Explain photosynthesis.”
Unlike older AI systems that use just one AI model like the Transformer based LLM, CAS emphasizes integration of multiple tools. For instance, a chatbot using retrieval-augmented generation (RAG) can handle missing information gracefully. Robustness and Resilience: Diverse components provide redundancy and robustness.
Traditional approaches to developing conversational LLM applications often fail in real-world use cases. Flowchart-based processing , which sacrifices the real magic of LLM-powered interactions: dynamic, free-flowing, human-like interactions. However, their reliability as autonomous customer-facing agents remains a challenge.
As part of this commitment, AWS Japan announced the AWS LLM Development Support Program (LLM Program), through which we’ve had the privilege of working alongside some of Japan’s most innovative teams. Let’s dive in and explore how these organizations are transforming what’s possible with generative AI on AWS.
We also dive into the challenge of imbalanced data in anomaly detection, introducing a method that leverages LLM embeddings to identify subtle irregularities especially useful when traditional techniques like oversampling or undersampling fall short. It details […]
I explore the differences between RAG and sending all data in the input and explain why we believe RAG will remain relevant for the foreseeable future. It offers an easy-to-use platform that shows chatbot performance using clear metrics and graphs. Querying SQL Database Using LLM Agents — Is It a Good Idea? So, is RAG dead?
Large Language Models have emerged as the central component of modern chatbots and conversational AI in the fast-paced world of technology. The use cases of LLM for chatbots and LLM for conversational AI can be seen across all industries like FinTech, eCommerce, healthcare, cybersecurity, and the list goes on.
LlamaIndex is a framework for building LLM applications. Optimized for search and retrieval, it streamlines querying LLMs and retrieving documents. It provides tools for chaining LLM operations, managing context, and integrating external data sources. It uses an LLM to compute metrics.
But for now, Ill be sharing how to stay updated with LLM industry developments where to find the most meaningful resources and how to curate them to stay informed at a level thats both useful and manageable. What if you learned how to teach yourself using the most powerful AI tools instead of relying on courses forever?
Modern chatbots can serve as digital agents, providing a new avenue for delivering 24/7 customer service and support across many industries. Chatbots also offer valuable data-driven insights into customer behavior while scaling effortlessly as the user base grows; therefore, they present a cost-effective solution for engaging customers.
While it is early, this class of reasoning-powered agents is likely to progress LLM adoption and economic impact to the next level. It details the underlying Transformer architecture, including self-attention mechanisms, positional embeddings, and feed-forward networks, explaining how these components contribute to Llamas capabilities.
An LLM, for example, could be post-trained to tackle a task like sentiment analysis or translation or understand the jargon of a specific domain, like healthcare or law. Answering complex questions an essential capability for agentic AI workloads requires the LLM to reason through the question before coming up with an answer.
How to be mindful of current risks when using chatbots and writing assistants By Maria Antoniak , Li Lucy , Maarten Sap , and Luca Soldaini Have you used ChatGPT, Bard, or other large language models (LLMs)? Have you interacted with a chatbot or used an automatic writing assistant? However, they can also just make stuff up.
In this post, well explore four key integration points between Snorkel Flow and Databricks, using a chatbot intent classification use case as an example: Ingesting raw data from Databricks into Snorkel Flow. However, fine-tuned LLMs trained on your proprietary data often outperform generic models.
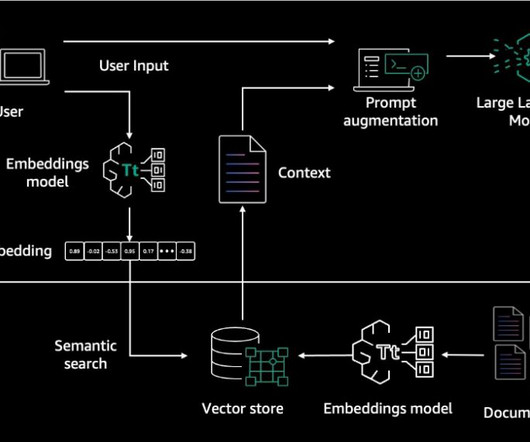
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. When a question gets asked, run its text through this same embedding model, determine which chunks are nearest neighbors , then present these chunks as a ranked list to the LLM to generate a response.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explainLLM in simple or to say general language. No need to train the LLM but one only has to think about Prompt design.
Image by the author One of the major challenges in using LLMs in business is that LLMs hallucinate. How can you entrust your clients to a chatbot that can go mad and tell them something inappropriate at any moment? Thats a problem, especially given that an LLM cant be fired or held accountable.
Enterprise developers, for instance, often utilize prompt engineering to tailor Large Language Models (LLMs) like GPT-3 to power a customer-facing chatbot or handle tasks like creating industry-specific contracts. It's a blend of: Understanding of the LLM: Different language models may respond variably to the same prompt.
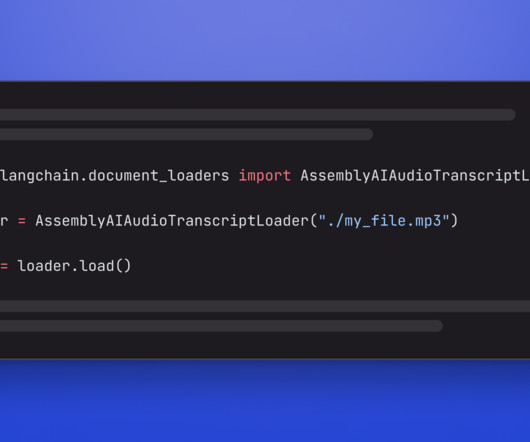
For this, we create a small demo application that lets you load audio data and apply an LLM that can answer questions about your spoken data. If you need to build production-ready LLM apps on spoken data fast, you can also use AssemblyAI's own framework called LeMUR (Leveraging Large Language Models to Understand Recognized Speech).
Perplexity AI is an AI-chatbot-powered research and conversational search engine that answers queries using natural language predictive text. One of the final projects I worked on there was building chatbots for service support. RAG is a general concept for providing external knowledge to an LLM.
The development and use of these models explain the enormous amount of recent AI breakthroughs. It’s essential for an enterprise to work with responsible, transparent and explainable AI, which can be challenging to come by in these early days of the technology. ” Are foundation models trustworthy?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content