This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. The first step is dataingestion, as shown in the following diagram. This structure can be used to optimize dataingestion.
Content ingestion into vector db Select the optimal LLM for your use case Selecting the right LLM for any use case is essential. Every use case has different requirements for context length, token size, and the ability to handle various tasks like summarization, task completion, chatbot applications, and so on.
These concerns include lack of interpretability, bias, and discrimination, privacy, lack of model robustness, fake and misleading content, copyright implications, plagiarism, and environmental impact associated with training and inference of generative AI models. Sign me up!
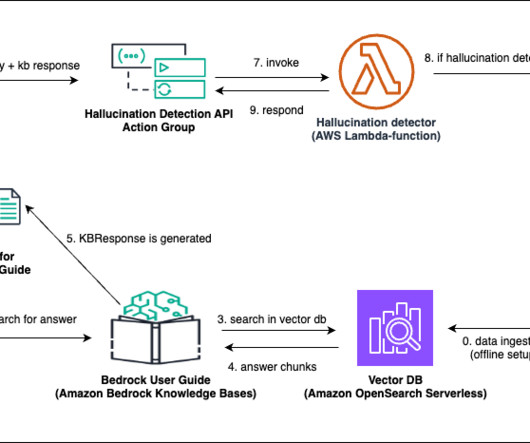
In this post, we will set up our own custom agentic AI workflow using Amazon Bedrock Agents to intervene when LLM hallucinations are detected and route the user query to customer service agents through a human-in-the-loop process. The final agent response is shown in the chatbot UI(User Interface).
The following diagram depicts the high-level steps of a RAG process to access an organization’s internal or external knowledge stores and pass the data to the LLM. The workflow consists of the following steps: Either a user through a chatbot UI or an automated process issues a prompt and requests a response from the LLM-based application.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content